一、安装问题
1. 下载速度太慢
使用国外源,下载速度很慢,可以考虑使用豆瓣的镜像下载
pip install -i https://pypi.douban.com/simple/ scrapy
2. 安装scrapy需要Microsoft Visual C++ 14.0 支持
在下面下载在线安装(可能需要半个小时以上,好几个G),注意安装时选择自定义安装,默认好像是win8.1,记得改为win10的
Download the Visual C++ Build Tools (standalone C++ compiler, libraries and tools)
二、新建scrapy项目
1. cmd新建项目
(SCRAPY~1) F:Python ScriptScrapy>scrapy startproject ArticleSpider
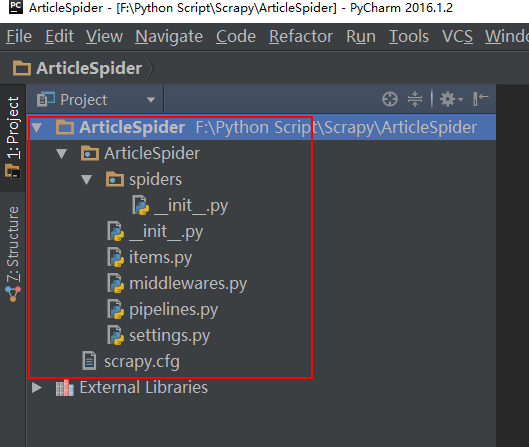
新建完后,就会生成项目,下面这个是Pycharm界面,怎么进入这个界面呢?File->Open 然后选择创建的项目文件夹 ArticleSpider
2. 创建初始模板
创建模板之前,要cd进入项目
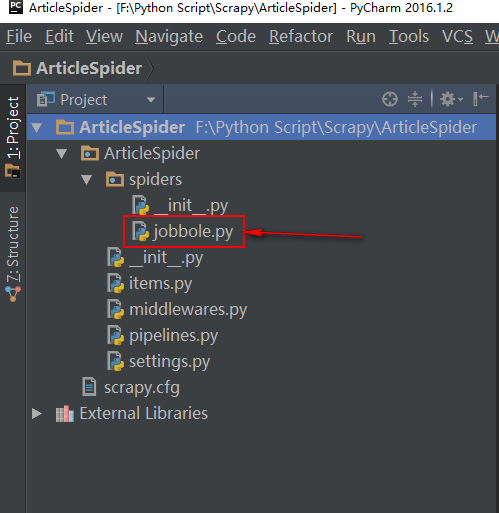
(SCRAPY~1) F:Python ScriptScrapy>cd ArticleSpider (SCRAPY~1) F:Python ScriptScrapyArticleSpider>scrapy genspider jobbole blog.jobbole.com
#jobbole 是我们的爬虫名
#blog.jobbole.com 是我们爬虫开始的页面
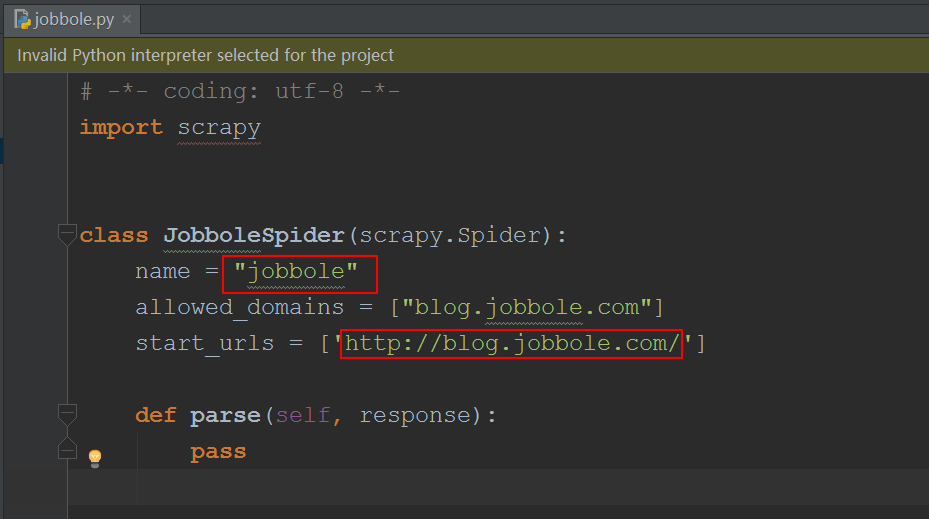
打开看一下,里面的代码
3. 选择开发环境
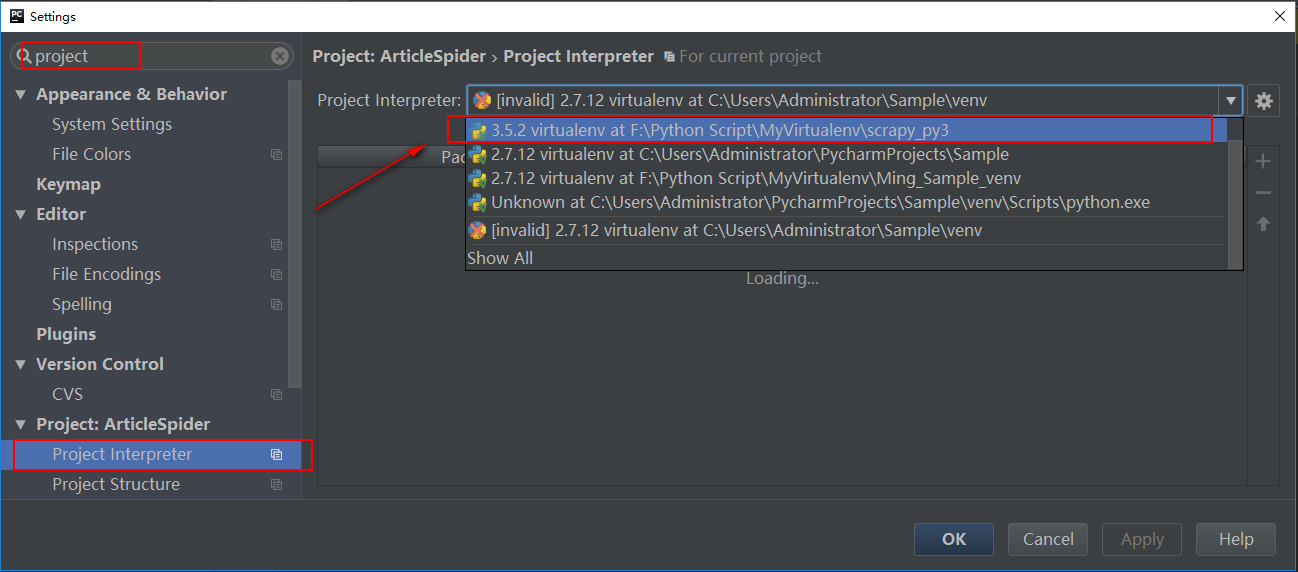
我们打开项目后,还没有选择我们的开发环境
-1. File->Setting,操作如图,选择我们之前搭建的Python3.5虚拟环境:scrapy_py3
4. 尝试运行爬虫
运行前,先安装pypiwin32
(SCRAPY~1) F:Python ScriptScrapyArticleSpider>pip install -i https://pypi.douban.com/simple/ pypiwin32
运行
(SCRAPY~1) F:Python ScriptScrapyArticleSpider>scrapy crawl jobbole
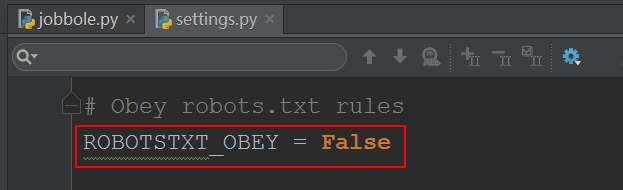
5. 改配置
在setting.py里改下配置
6. 调试
调试断点的简单说明,看这里:PyCharm 教程(五)断点 调试
继续调试快捷键是,F8
由于pycharm没有scrapy的模板,所以是没办法调试的,但是我们通过自定义一个main文件,来调试
#main.py
#coding:utf-8 from scrapy.cmdline import execute import os,sys sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(['scrapy','crawl','jobbole'])
在jobbole.py设置断点
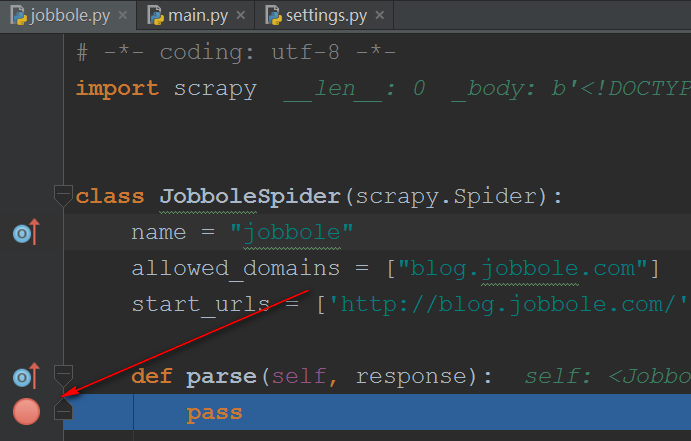
点下右上角的甲虫图标,或者快捷键Shift+F9 ,调试main.py
调试完成后会自动跳到jobbole.py文件的断点处。
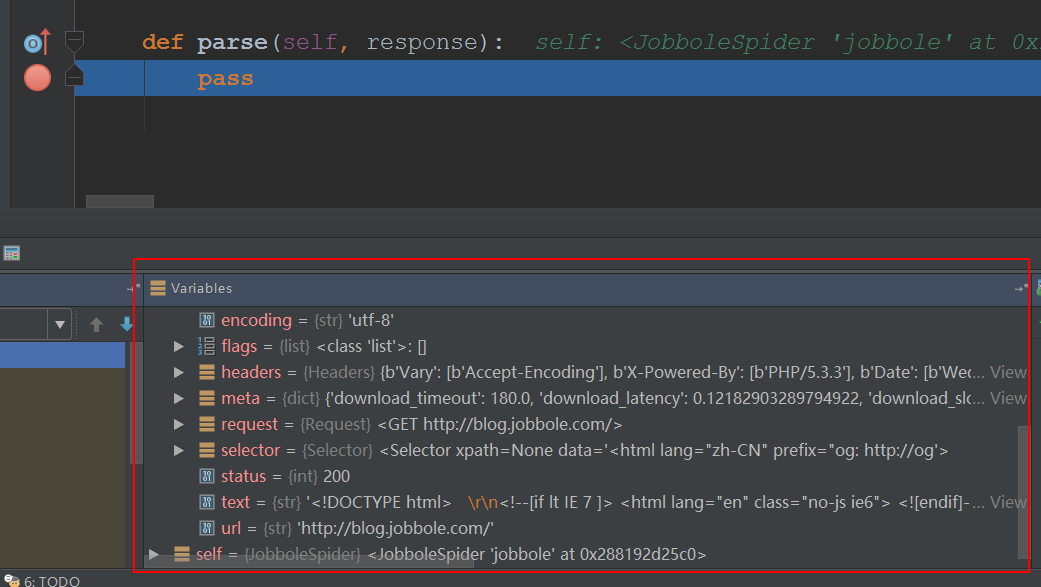
我们可以查看下变量信息
看看,response里的变量
7. scrapy shell 调试
在虚拟环境中venv,进入scrapy项目所在的目录
(SCRAPY~1) F:Python ScriptScrapyArticleSpider>
键入如下命令,进入scrapy shell环境
(SCRAPY~1) F:Python ScriptScrapyArticleSpider>scrapy shell http://blog.jobbole.com/111121/
后面的url,看你要调试哪个网址,就填哪个
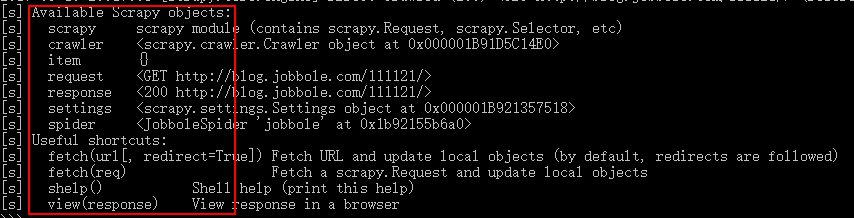
进入后,就可以发现有这么多变量可以使用了,这里我们主要关注response
利用scrapy shell带上User-Agent
scrapy shell -s USER_AGENT:'拷贝进来' https://www.zhihu.com
scrapy增加表头
$ scrapy shell ... ... >>> from scrapy import Request >>> req = Request('yoururl.com', headers={"header1":"value1"}) >>> fetch(req)