在一些先决条件下,SQL Server可以缓存临时表(cache Temp Tables)。缓存临时表意味着当你创建反复创建同个临时表时,SQL Server就可以重用它们。这会从整体上大幅度提高你的工作量(性能),因为SQL Server不需要访问内存里的特定页(PFS,GAM,SGAM),经常访问这些页在工作量大的情况下会引起加锁竞争(Latch Contention)。Paul White有一篇很棒的文章详细描述这个情况,可以点此围观下。
临时表缓存的条件之一是不能在存储过程里混合使用DML(Data Manipulation Language 数据操作语言)和DDL(Data Definition Language 数据定义语言)语句。我们来看下面的代码:
1 -- Create a new stored procedure 2 CREATE PROCEDURE PopulateTempTable 3 AS 4 BEGIN 5 -- Create a new temp table 6 CREATE TABLE #TempTable 7 ( 8 Col1 INT IDENTITY(1, 1), 9 Col2 CHAR(4000), 10 Col3 CHAR(4000) 11 ) 12 13 -- Create a unique clustered index on the previous created temp table 14 CREATE UNIQUE CLUSTERED INDEX idx_c1 ON #TempTable(Col1) 15 16 -- Insert 10 dummy records 17 DECLARE @i INT = 0 18 WHILE (@i < 10) 19 BEGIN 20 INSERT INTO #TempTable VALUES ('Woody', 'Tu') 21 SET @i += 1 22 END 23 END 24 GO
这里你通过DDL语句(CREATE UNIQUE CLUSTERED INDEX )创建了索引,这就是说你混合使用了DDL和DML语句。因此SQL Server不能缓存你的临时表。你可以从下面例子里的DMV sys.dm_os_performance_counters ,通过跟踪性能计数器Temp Tables Creation Rate 来验证:
1 DECLARE @table_counter_before_test BIGINT; 2 SELECT @table_counter_before_test = cntr_value FROM sys.dm_os_performance_counters 3 WHERE counter_name = 'Temp Tables Creation Rate' 4 5 DECLARE @i INT = 0 6 WHILE (@i < 1000) 7 BEGIN 8 EXEC PopulateTempTable 9 SET @i += 1 10 END 11 12 DECLARE @table_counter_after_test BIGINT; 13 SELECT @table_counter_after_test = cntr_value FROM sys.dm_os_performance_counters 14 WHERE counter_name = 'Temp Tables Creation Rate' 15 16 PRINT 'Temp tables created during the test: ' + CONVERT(VARCHAR(100), @table_counter_after_test - @table_counter_before_test) 17 GO
当你运行这个代码时,SQL Server需要创建1000个单独的临时表,这个从SSMS的输出窗口就可以看到。

通过PRIMARY KEY约束来强制UNIQUE CLUSTERED INDEX就很容易克服这个问题。在这个方式下,你没有混合使用DDL和DML语句,SQL Server最后也能缓存你的临时表。
1 ALTER PROCEDURE PopulateTempTable 2 AS 3 BEGIN 4 -- Create a new temp table 5 CREATE TABLE #TempTable 6 ( 7 Col1 INT IDENTITY(1, 1) PRIMARY KEY, -- This creates also a Unique Clustered Index 8 Col2 CHAR(4000), 9 Col3 CHAR(4000) 10 ) 11 12 -- Insert 10 dummy records 13 DECLARE @i INT = 0 14 WHILE (@i < 10) 15 BEGIN 16 INSERT INTO #TempTable VALUES ('Woody', 'Tu') 17 SET @i += 1 18 END 19 END 20 GO
当你重新执行刚才用来跟踪相关计数器的代码,可以看到SQL Server值创建了一次临时表并重用它了:
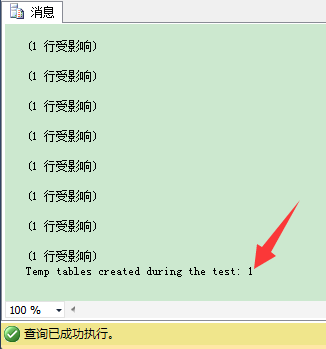
这个结论也意味着,当你创建额外的非聚集索引(Non-Clustered Indexes)时,SQL Server也不能缓存临时表,因为在你的存储过程里,你又一次混合使用DDL和DML语句。
但在SQL Server 2014里,你就可以克服这个限制,因为现在你可以在CREATE TABLE语句行里创建索引。来看下面的代码:
1 ALTER PROCEDURE PopulateTempTable 2 AS 3 BEGIN 4 -- Create a new temp table 5 CREATE TABLE #TempTable 6 ( 7 Col1 INT IDENTITY(1, 1) PRIMARY KEY, -- This creates also a Unique Clustered Index 8 Col2 CHAR(100) INDEX idx_Col2, 9 Col3 CHAR(100) INDEX idx_Col3 10 ) 11 12 -- Insert 10 dummy records 13 DECLARE @i INT = 0 14 WHILE (@i < 10) 15 BEGIN 16 INSERT INTO #TempTable VALUES ('Woody', 'Tu') 17 SET @i += 1 18 END 19 END 20 GO
如你所见,我在创建临时表本身的时候,就在临时表上直接创建2个额外的非聚集索引。又一次我们没有混合使用DDL和DML语句,SQL Server又一次可以缓存并重用你的临时表。
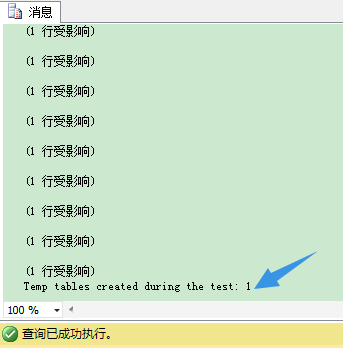
在SQL Server 2014里,在临时表上定义行内定义索引,避开混合使用DML和DDL语句,让临时表只创建一次并重用,是一个很棒的功能!
这个新功能怎样?欢迎在下面评论里告诉我。
参考文章:
https://www.sqlpassion.at/archive/2013/06/27/improved-temp-table-caching-in-sql-server-2014/