在今天的文章里我想谈下SQL Server里与索引相关的特殊性能问题。
问题描述
假设下列的简单查询,在你的日常SQL Server里,这样的查询你已经看到过几百遍了:
1 -- Results in an Index Scan 2 SELECT * FROM Sales.SalesOrderHeader 3 WHERE YEAR(OrderDate) = 2005 AND MONTH(OrderDate) = 7 4 GO
用那个简单查询,我们请求在特定年份特定月份里的销售信息。并不复杂。遗憾的是这个查询性能很差——即使在OrderDate列使用了非聚集索引。当你查看执行计划时,你会看到查询优化器选择了在OrderDate列上的非聚集索引,但遗憾的是SQL Server进行的索引的全扫描,而不是高效的查找操作。
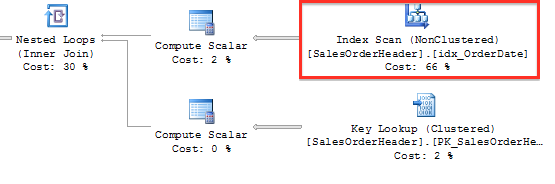
这真不是SQL Server的局限性,而是关系数据库的工作和思考方式:)只要你在索引列上使用了表达式(函数调用,计算)(即所谓的筛选参数(Search Argument)),数据库引擎必须去扫描那个索引,而不是进行查找操作。
解决方法
在执行计划里为了获得可扩展的查找操作,你必须要换种方式重写你的查询来避免DATEPART函数的调用:
1 -- Results in an Index Seek 2 SELECT * FROM Sales.SalesOrderHeader 3 WHERE OrderDate >= '20050701' AND OrderDate < '20050801' 4 GO
从重写的查询可以看到,查询返回同样的结果,但我们已经剔除了DATEPART函数的调用。当你查看执行计划时,你会看到SQL Server进行了查找操作——在那个情况下,这个是所谓的局部范围扫描(Partial Range Scan):SQL Server查找到第1个值,然后扫描到请求范围的最有值。如果你想在索引列上下文调用函数,你必须保证在查询里,这些函数调用的执行在你列的右侧。我们来看一个具体的例子。下面查询把CreditCardID索引列转化为CHAR(4)数据类型:
1 -- Results in an Index Scan 2 SELECT * FROM Sales.SalesOrderHeader 3 WHERE CAST(CreditCardID AS CHAR(4)) = '1347' 4 GO
当你仔细看执行计划时,你会看到SQL Server再次扫描整个非聚集索引。如果你的表越来越大,这是真不能扩展的。如果你在查询里在你索引列的右侧执行转化,你就可以在索引列上剔除函数调用,SQL Server就可以进行查找操作:
1 -- Results in an Index Seek 2 SELECT * FROM Sales.SalesOrderHeader 3 WHERE CreditCardID = CAST('1347' AS INT) 4 GO
小结
从这篇文章里,你可以看到,在你的索引列里不直接调用任何函数或间接调用函数是非常重要的。不然的话SQL Server会扫描你的索引,而不是进行高效的查找操作。而且当你表越来越大时,扫描从不扩展。
如果你碰到这个特殊行为的其他好例子,想分享的话,欢迎留言。
感谢关注。