几天前,我写了篇SQL Server里简单参数化的痛苦。今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization)。
强制参数化(Forced Parameterization)
在SQL Server里简单参数化有很多限制,如果你的SQL语句包含下列任意它不会发生:
- JOIN
- IN
- BULK INSERT
- UNION
- INTO
- DISTINCT
- TOP
- GROUP BY
- HAVING
- COMPUTE
- Sub Queries
如果你还想让SQL Server进行自动参数化,你可以启用在数据库层启用强制参数化:
1 -- Let's now activate Forced Parameterization on the AdventureWorks2012 database 2 ALTER DATABASE AdventureWorks2012 SET PARAMETERIZATION FORCED 3 GO
在这个情况下,SQL Server总会自动参数化你的SQL语句除掉以下情况:
- INSERT … EXECUTE
- Prepared SQL Statements
- RECOMPILE
- COMPUTE
为什么强制参数化总不是个好选择
现在让我们看下SQL Server里的强制参数化。对于AdventureWorks2012数据库,最后的代码已经将它启用强制参数化了。下一步我创建Sales.SalesOrderHeader表的副本,并将数据修正,这样的话在CustomerID列我们会有非线性的数据分布。另外我在那一列也创建了非聚集索引。
1 -- Create a copy from the Sales.SalesOrderHeader table 2 SELECT * INTO Sales.SalesOrderHeader2 FROM Sales.SalesOrderHeader 3 GO 4 5 -- Create a Non-Clustered Index on the CustomerID column 6 CREATE NONCLUSTERED INDEX idx_CustomerID ON Sales.SalesOrderHeader2(CustomerID) 7 GO 8 9 -- "Patch" the data in some way, so that the content of the column "CustomerID" is not evenly distributed across the whole table 10 UPDATE Sales.SalesOrderHeader2 11 SET CustomerID = 29675 12 WHERE SalesOrderID < 60000 13 GO
从下图你可以看到:ID为29675的客户有大量的订单,其它客户只有一些订单:
1 SELECT CustomerID,COUNT(SalesOrderID) SaleCount FROM Sales.SalesOrderHeader2 2 GROUP BY CustomerID ORDER BY 2 DESC
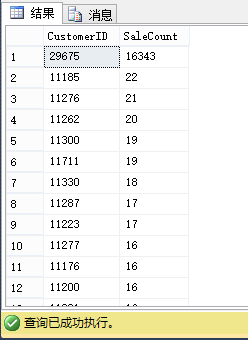
在下一步里我执行一个返回CustomerID为22943的所有记录——只有3条记录。因为查询在临界点前,SQL Server选择了有书签查找的执行计划。查询合计生成了3个逻辑读。因为我们对AdventureWorks2012数据库启用了强制参数化,对这个语句SQL Server也会自动参数化,因此执行计划会被后续的查询重用。
1 -- 3 Logical Reads 2 SELECT * FROM Sales.SalesOrderHeader2 3 WHERE CustomerID = 22943 -- Index Seek, returns 1 record 4 GO

我们再来运行另一个查询,返回所有CustomerID为29675的记录。在这个情况下查询返回16343条记录。当你再次看执行计划时,你会看到查询重用了刚才查询的执行计划。
1 SELECT * FROM Sales.SalesOrderHeader2 2 WHERE CustomerID = 29675 3 GO

这是对的,以为查询自动参数化,SQL Server在计划缓存里找已经缓存的计划。但是重用执行计划并不安全,因为现在我们进行了书签查找16343次——对每一行——反复执行。查询合计生成了16415个逻辑读。使用表扫描的话只要780个逻辑读。
这是强制参数化的副作用。SQL Server不管你执行计划的稳定性。SQL Server值自动参数化你的SQL语句,并反复重用缓存的执行计划。不管这个执行计划有糟糕。因为这是你强制SQL Server只要做的!没有启用强制参数化,SQL Server从不为你自动参数化SQL语句,因为那不安全。
性能问题的根源肯定是强制参数化。这里的根源是你的执行计划包含书签查找。因为书签查找你就没有计划稳定性。计划没有稳定性是说基于你输入参数值你会有不同的执行计划。在这个例子里有时你得到书签查找(临界点前),有时是表扫描(临界点后)。
在这个情况下,如果你修改下你的索引设计,为这个查询定义一个覆盖非聚集索引,性能问题也会消失。这样的话也不需要启用强制参数化,因为使用计划稳定性SQL Server会自动参数化你的SQL语句!
小结
在数据库级别启用强制参数化是个非常危险的事。不管你是否有计划稳定性,SQL Server总会自动参数化你的SQL语句,并反复重用你的执行计划。因此你要知道你的执行计划的详细情况,看看它们是否会引起性能相关的问题。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/07/27/the-pain-of-forced-parameterization-in-sql-server/