
Optimization
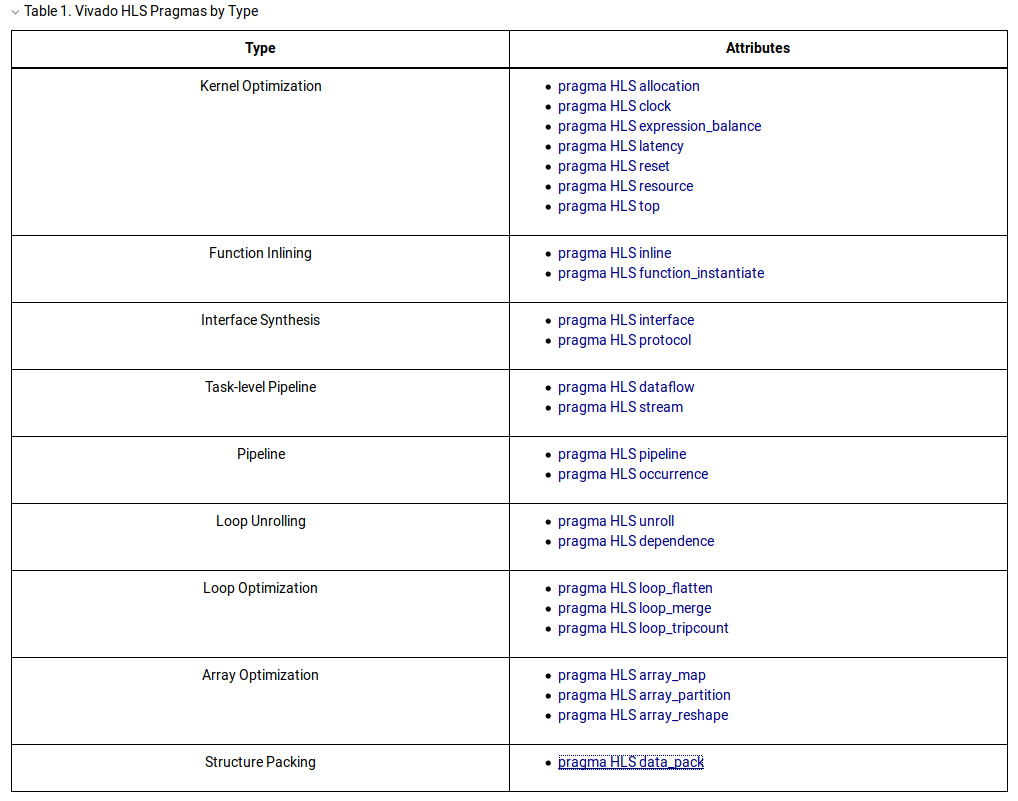

Using Vivado HLS, you can apply different optimization directives to the design, including:
• Instruct a task to execute in a pipeline, allowing the next execution of the task to begin
before the current execution is complete.
• Specify a latency for the completion of functions, loops, and regions.
• Specify a limit on the number of resources used.
• Override the inherent or implied dependencies in the code and permit specified
operations. For example, if it is acceptable to discard or ignore the initial data values,
such as in a video stream, allow a memory read before write if it results in better
performance.
• Select the I/O protocol to ensure the final design can be connected to other hardware
blocks with the same I/O protocol.
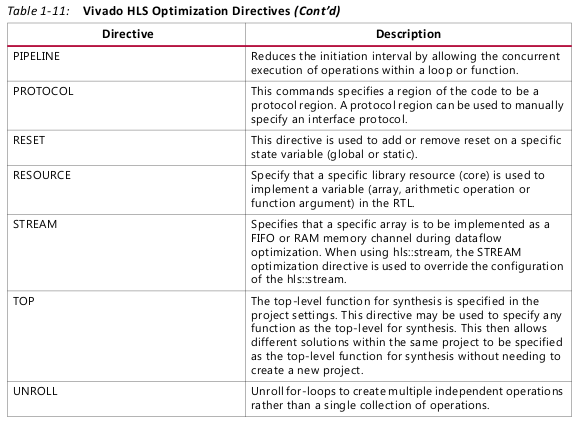
Function and Loop Pipelining
Pipelining allows operations to happen concurrently.
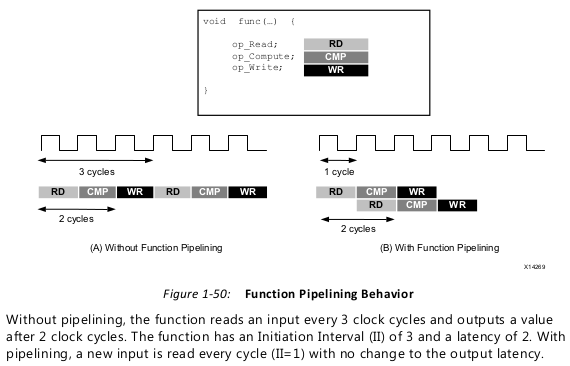
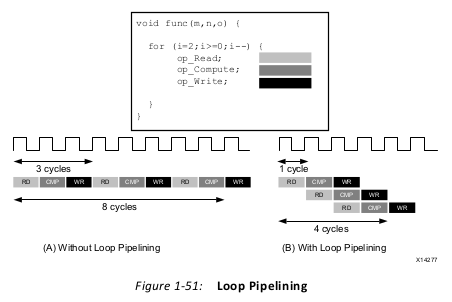
Functions or loops are pipelined using the PIPELINE directive. The directive is specified in
the region that constitutes the function or loop body. The initiation interval defaults to 1 if
not specified but may be explicitly specified.
Pipelining is applied only to the specified region and not to the hierarchy below: all loops
in the hierarchy below are automatically unrolled. Any sub-functions in the hierarchy below
the specified function must be pipelined individually. If the sub-functions are pipelined, the
pipelined functions above it can take advantage of the pipeline performance. Conversely,
any sub-function below the pipelined top-level function that is not pipelined, may be the
limiting factor in the performance of the pipeline.

There is a difference in how pipelined functions and loops behave.
• In the case of functions, the pipeline runs forever and never ends.
• In the case of loops, the pipeline executes until all iterations of the loop are completed.
Rewinding Pipelined Loops for Performance
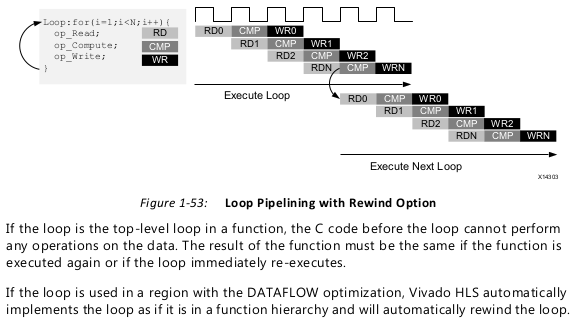
Loops which are the top-level loop in a function or are used in a region where the
DATAFLOW optimization is used can be made to continuously execute using the PIPELINE
directive with the rewind option.
Addressing Failure to Pipeline
When a function is pipelined, all loops in the hierarchy are automatically unrolled. This is a
requirement for pipelining to proceed. If a loop has variables bounds it cannot be unrolled.
This will prevent the function from being pipelined.

Partitioning Arrays to Improve Pipelining
A common issue when pipelining functions is the following message:
INFO: [SCHED 204-61] Pipelining loop 'SUM_LOOP'. WARNING: [SCHED 204-69] Unable to schedule 'load' operation ('mem_load_2', bottleneck.c:62) on array 'mem' due to limited memory ports. WARNING: [SCHED 204-69] The resource limit of core:RAM:mem:p0 is 1, current assignments: WARNING: [SCHED 204-69] 'load' operation ('mem_load', bottleneck.c:62) on array 'mem', WARNING: [SCHED 204-69] The resource limit of core:RAM:mem:p1 is 1, current assignments: WARNING: [SCHED 204-69] 'load' operation ('mem_load_1', bottleneck.c:62) on array 'mem', INFO: [SCHED 204-61] Pipelining result: Target II: 1, Final II: 2, Depth: 3.
This issue is typically caused by arrays. Arrays are implemented as block RAM which only
has a maximum of two data ports. This can limit the throughput of a read/write (or
load/store) intensive algorithm. The bandwidth can be improved by splitting the array (a
single block RAM resource) into multiple smaller arrays (multiple block RAMs), effectively
increasing the number of ports.
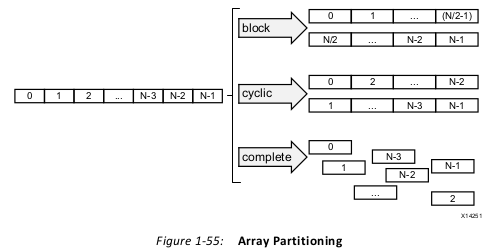
Arrays are partitioned using the ARRAY_PARTITION directive. Vivado HLS provides three
types of array partitioning, as shown in the following figure. The three styles of partitioning
are:
• block: The original array is split into equally sized blocks of consecutive elements of
the original array.
• cyclic: The original array is split into equally sized blocks interleaving the elements of
the original array.
• complete: The default operation is to split the array into its individual elements. This
corresponds to resolving a memory into registers.
For block and cyclic partitioning the factor option specifies the number of arrays that are
created. In the preceding figure, a factor of 2 is used, that is, the array is divided into two
smaller arrays. If the number of elements in the array is not an integer multiple of the factor,
the final array has fewer elements.
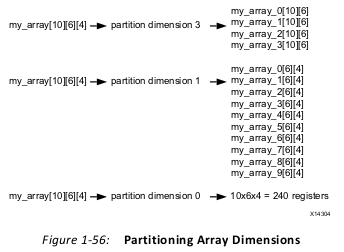
When partitioning multi-dimensional arrays, the dimension option is used to specify
which dimension is partitioned.The examples in the figure demonstrate how partitioning dimension 3 results in 4 separate
arrays and partitioning dimension 1 results in 10 separate arrays. If zero is specified as the
dimension, all dimensions are partitioned.
Dependencies with Vivado HLS
Removing False Dependencies to Improve Loop Pipelining
Optimal Loop Unrolling to Improve Pipelining
By default loops are kept rolled in Vivado HLS. That is to say that the loops are treated as a
single entity: all operations in the loop are implemented using the same hardware resources
for iteration of the loop.
Vivado HLS provides the ability to unroll or partially unroll for-loops using the UNROLL
directive.
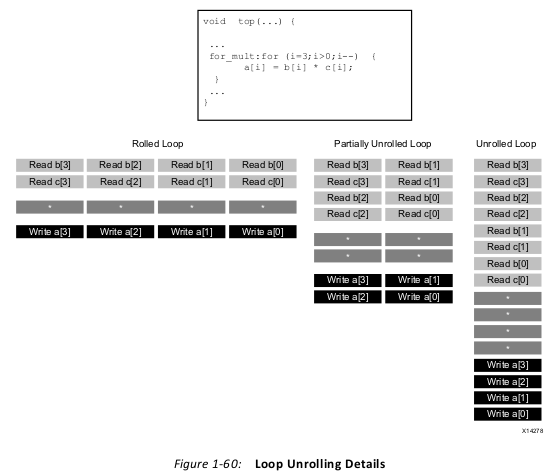
• Rolled Loop: When the loop is rolled, each iteration is performed in a separate clock
cycle. This implementation takes four clock cycles, only requires one multiplier and
each block RAM can be a single-port block RAM.
• Partially Unrolled Loop: In this example, the loop is partially unrolled by a factor of 2.
This implementation required two multipliers and dual-port RAMs to support two reads
or writes to each RAM in the same clock cycle. This implementation does however only
take 2 clock cycles to complete: half the initiation interval and half the latency of the
rolled loop version.
• Unrolled loop: In the fully unrolled version all loop operation can be performed in a
single clock cycle. This implementation however requires four multipliers. More
importantly, this implementation requires the ability to perform 4 reads and 4 write
operations in the same clock cycle. Because a block RAM only has a maximum of two
ports, this implementation requires the arrays be partitioned.

To perform loop unrolling, you can apply the UNROLL directives to individual loops in the
design. Alternatively, you can apply the UNROLL directive to a function, which unrolls all
loops within the scope of the function.
If a loop is completely unrolled, all operations will be performed in parallel: if data
dependencies allow. If operations in one iteration of the loop require the result from a
previous iteration, they cannot execute in parallel but will execute as soon as the data is
available. A completely unrolled loop will mean multiple copies of the logic in the loop
body.
Exploiting Task Level Parallelism: Dataflow Optimization
Dataflow Optimization Limitations
Configuring Dataflow Memory Channels
Specifying Arrays as Ping-Pong Buffers or FIFOs
Reference:
1.Xilinx UG902
2. https://japan.xilinx.com/html_docs/xilinx2017_4/sdaccel_doc/okr1504034364623.html