函数调用:即调用函数调用被调用函数,调用函数压栈,被调用函数执行,调用函数出栈,调用函数继续执行的一个看似简单的过程,系统底层却做了大量操作。
操作:
1, 调用函数帧指针(函数参数,局部变量,栈帧状态值,函数返回地址)入栈,栈指针自减
2, 保存调用函数的状态数据入寄存器
3, 被调用函数帧指针入栈,执行当前的被调用函数
4, 被调用函数执行结束,退栈,返回到调用函数的帧指针,从寄存器中恢复当时状态数据
5, 继续执行调用函数,直至结束
即整个调用操作有一个压栈出栈,保存和恢复状态数据的过程。而系统栈内存是有默认的固有大小。有多少次函数调用就会分配多少栈帧。故,函数调用性能影响有如下因素:
1,函数递归层数;
2,参数个数(参数签名所占内存大小)
2.1同类型不同参数个数;
2.2同参数个数不同参数类型;
2.3同参数类型同参数个数,但参数类型所占内存大小不同;
3,函数栈大小,即函数局部变量所占栈大小。
为了测试C语言函数调用性能(时间消耗)因素,编写了一个简单程序运行在如下环境中:
Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz memery size:7833700 kB(7.47GB)
在函数调用的开始与结束处,用time.h中的clock()函数返回CPU时钟计时单位数(下表中的starttime和endtime),用durationtime=endtime-starttime表示函数调用的时间消耗。如下:
clock_t starttime=clock();
函数调用…
clock_t endtime=clock();
//除以CLOCKS_PER_SEC,得到以秒为单位的时间结果
double durationtime=(double)(endtime-starttime)/CLOCKS_PER_SEC;//表示函数调用占用cpu的时间,不包括子进程或者printf等的操作的时间
注:clock()记录的是进程占用cpu的时间,精确度为微秒;详细讲解clock()函数的网址:http://site.douban.com/199048/widget/notes/12005386/note/253542964/
一.函数递归层数(循环1000000次)
|
栈(字节) |
参数(字节) |
递归次数 |
总函数调用时间消耗(秒) |
每循环函数调用时间消耗(微秒) |
每次函数调用平均时间消耗(纳秒) |
|
1024 |
24 |
10 |
2.9 |
2.9 |
290 |
|
1024 |
24 |
20 |
5.713 |
5.713 |
285.65 |
|
1024 |
24 |
30 |
9.025 |
9.025 |
300.83 |
|
1024 |
24 |
50 |
16.0767 |
16.0767 |
321.534 |
|
1024 |
24 |
80 |
21.79 |
21.79 |
272.375 |
|
1024 |
24 |
100 |
30.73 |
30.73 |
307.3 |
|
1024 |
24 |
200 |
66.24 |
66.24 |
331.2 |
注:平均每次函数调用时间消耗=durationtime/调用层数/ 循环次数
每循环函数调用时间消耗=durationtime/ 循环次数
函数调用根据不同的调用层数不同的时间平均消耗,如下折线图:
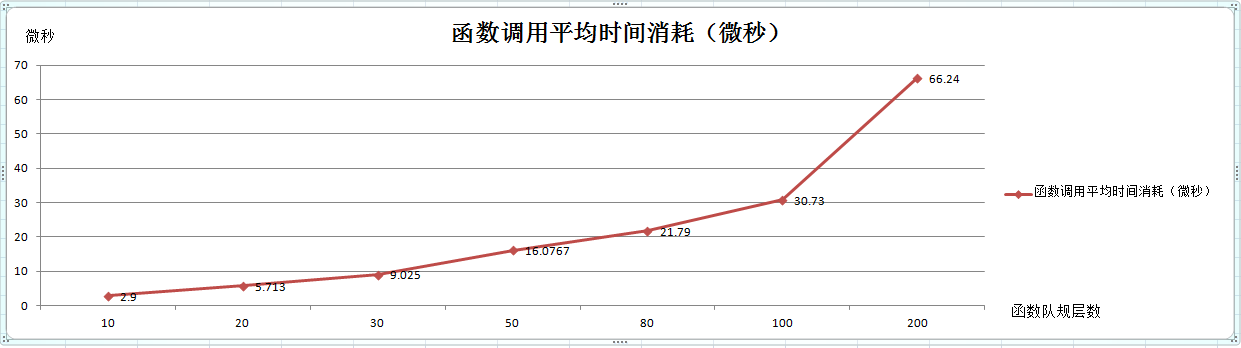
图1
每次函数调用平均时间消耗,如下折线图:
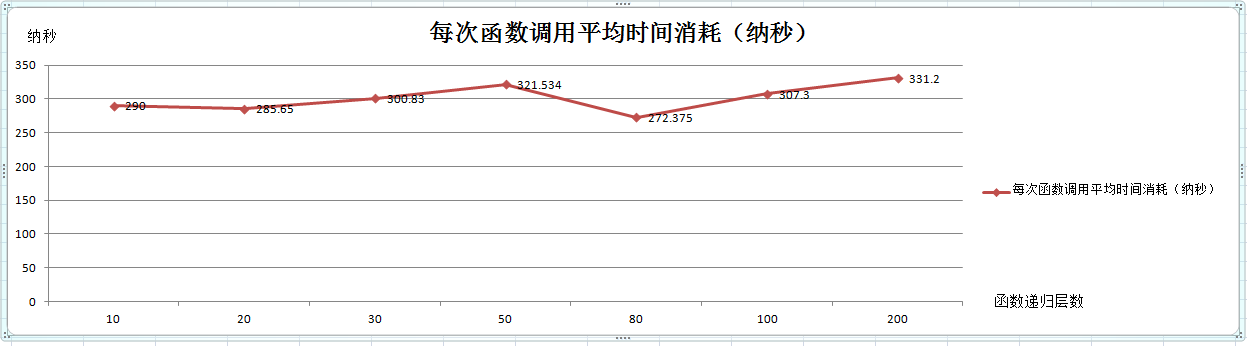
图2
结论:1,在参数所占内存相同和函数栈大小相同的情况下,函数调用的时间消耗随着函数调用层数增加而增加;如图1;
2,在参数所占内存相同和函数栈大小相同的情况下,每次函数调用的时间消耗大概在300纳秒左右;如图2;
二,函数栈大小
|
循环次数 |
栈(字节) |
参数 (字节) |
递归次数 |
总函数调用时间消耗(秒) |
每循环函数调用时间消耗(微秒) |
平均每次函数调用(纳秒) |
|
1000000 |
16 |
24 |
50 |
9.4 |
9.4 |
184 |
|
1000000 |
32 |
24 |
50 |
9.37 |
9.37 |
187.4 |
|
1000000 |
64 |
24 |
50 |
9.5 |
9.5 |
190 |
|
1000000 |
128 |
24 |
50 |
10.415 |
10.415 |
208.3 |
|
1000000 |
256 |
24 |
50 |
11.805 |
11.805 |
236.1 |
|
1000000 |
512 |
24 |
50 |
14 |
14 |
280 |
|
1000000 |
1024 |
24 |
50 |
16.0767 |
16.0767 |
321.534 |
|
1000000 |
2048 |
24 |
50 |
18.42 |
18.42 |
368.4 |
注:平均每次函数调用时间消耗=durationtime/调用层数/ 循环次数
每循环函数调用时间消耗=durationtime/ 循环次数
函数调用根据不同的调用层数不同的时间平均消耗,如下折线图:
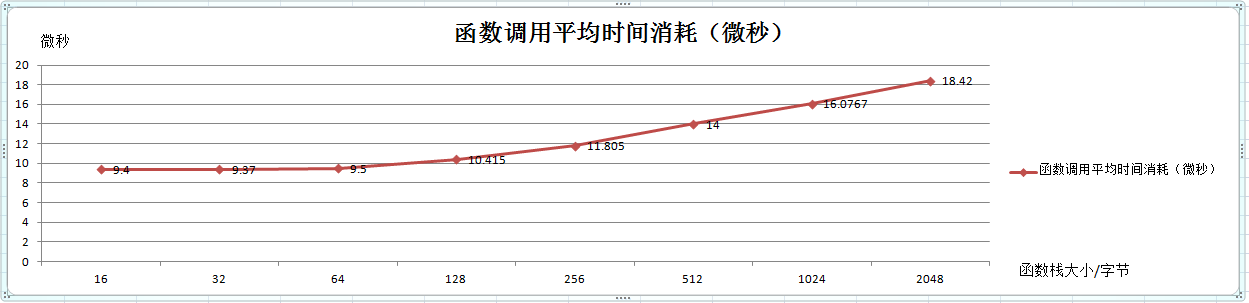
图3
每次函数调用平均时间消耗,如下折线图:
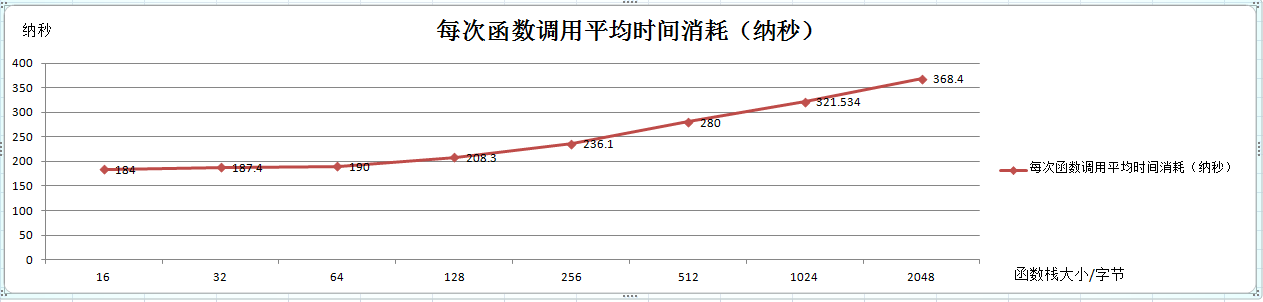
图4
结论:1,在函数参数相同和函数调用层数相同的情况下,函数调用时间消耗随函数栈大小的增加而增加;如图3;
2,在函数参数相同和函数调用层数相同的情况下,每次函数调用时间消耗随函数栈大小的增加而增加;如图4;
三,参数个数
|
栈(字节) |
参数 (字节) |
递归次数 |
总函数调用时间消耗(秒) |
每循环函数调用时间消耗(微秒) |
平均每次函数调用(纳秒) |
|
1024 |
24 |
50 |
16.0767 |
16.0767 |
321.5 |
|
1024 |
36 |
50 |
16.245 |
16.245 |
324.9 |
|
1024 |
48 |
50 |
16.345 |
16.345 |
326.9 |
|
1024 |
60 |
50 |
15.915 |
15.915 |
318.3 |
|
1024 |
72 |
50 |
14.29 |
14.29 |
285.8 |
|
1024 |
84 |
50 |
15.76 |
15.76 |
315.2 |
|
1024 |
96 |
50 |
15.14 |
15.14 |
302.8 |
|
1024 |
108 |
50 |
13.975 |
13.975 |
279.5 |
|
1024 |
120 |
50 |
16.68 |
16.68 |
333.6 |
|
1024 |
144 |
50 |
15.37 |
15.37 |
307.4 |
|
1024 |
180 |
50 |
14.42 |
14.42 |
288.4 |
|
1024 |
192 |
50 |
14.62 |
14.62 |
292.4 |
注:平均每次函数调用时间消耗=durationtime/调用层数/ 循环次数
每循环函数调用时间消耗=durationtime/ 循环次数
函数调用根据不同的函数参数大小的时间平均消耗,如下折线图:

每次函数调用平均时间消耗,如下折线图:
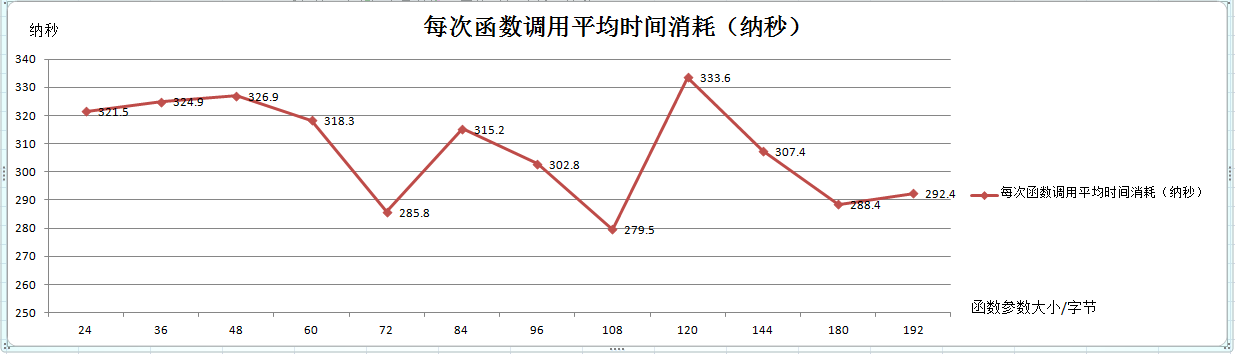
结论: 经过前几次的函数测试,虽然存在误差,但是仍然可以得出参数对于函数调用的时间消耗的影响,在于参数所占内存大小;函数传参存在两种方式:值传参和引用传参;两种方式在一般情况下,不会占用过多的内存;故,在一般情况下,参数对函数调用的时间消耗的影响不明显;
四,结论:
1,在函数参数大小为24字节和函数栈大小为1024字节的情况下,递归50次的函数时间消耗为16.0767微秒,可以粗略得出每次函数调用(压栈出栈)的时间消耗为320纳秒左右;
思路:1,函数参数大小:函数参数分为值传参和引用传参(参数的指针);一般值传参为常用的值类型,这样的参数一般不会占用过多的内存;引用参数是参数地址也不会占用过多内存;所以在一般情况下,函数参数对函数调用时间消耗影响不大;
2,计数:循环1000000次函数递归,是为了想提高数据的精确性和便于计算;1秒=1000000微秒;
3,递归层数:选择可能常规下递归的层数(24--35)
4,函数栈大小:按照以太网的最大字节1500字节,选择在1024字节左右做以上实验;
代码:
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<string.h> 4 #include<time.h> 5 #define array_len 256 6 typedef struct { 7 int typeone; 8 int typetwo; 9 }struct_type; 10 long call_back(int call_num,int typeone,int typetwo,int typethree,long p_recorde) 11 { 12 if(call_num<=0)return p_recorde; 13 int i_rand[array_len]; 14 int i=0; 15 clock_t start_time,end_time; 16 start_time=clock(); 17 for(i=0;i<array_len;i++) 18 { 19 i_rand[i]=rand(); 20 } 21 end_time=clock(); 22 p_recorde+=(long)(end_time-start_time); 23 call_back(call_num-1,typeone,typetwo,typethree,p_recorde); 24 } 25 void main(int argc,char *argv[]) 26 { 27 int loop_num=atoi(argv[1]),call_num=atoi(argv[2]); 28 long p_recorde=0,sum=0; 29 clock_t start_time,end_time; 30 start_time=clock(); 31 int i; 32 for(i=0;i<loop_num;i++) 33 { 34 sum_loop+=call_back(call_num,0,0,0,p_recorde); 35 } 36 end_time=clock(); 37 double duration_time=(double)(end_time-start_time)/CLOCKS_PER_SEC-(double)sum_loop/CLOCKS_PER_SEC; 38 printf("sum=%f duration=%f ",sum_loop,duration_time); 39 }
代码思路:1,为了减少数据cache命中的影响,在每次函数调用中用了rand()获取随机数,并记录时间消耗a;
2,记录函数调用的时间总消耗b,b-a的差即为函数调用的时间总消耗;