在上卷中我说出两种方法进行数据去重自增,第一种就是在数据库的字段中设置唯一字段,二是在脚本语言中设置重复判断再添加(建议,二者同时使用,真正开发中就会用到)
话不多说先上代码
第一步:
确定那一字段的数据为不可重复数据,我在这个测试表中希望worknum的数据为不可重复数据,现在看下表中数据:

第二步:
测试查询语句:

可以看出查询语句以字符串的形式存在于方法中结果如下:
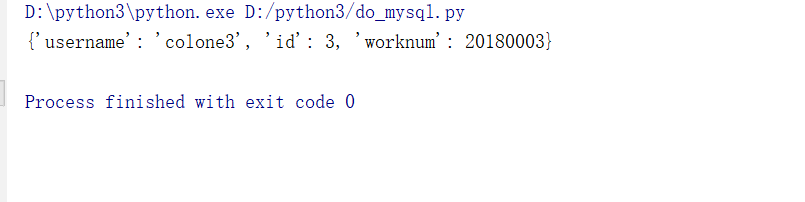
可以看出数据可以正常查询
第三步:
模拟数据演练,进行判断
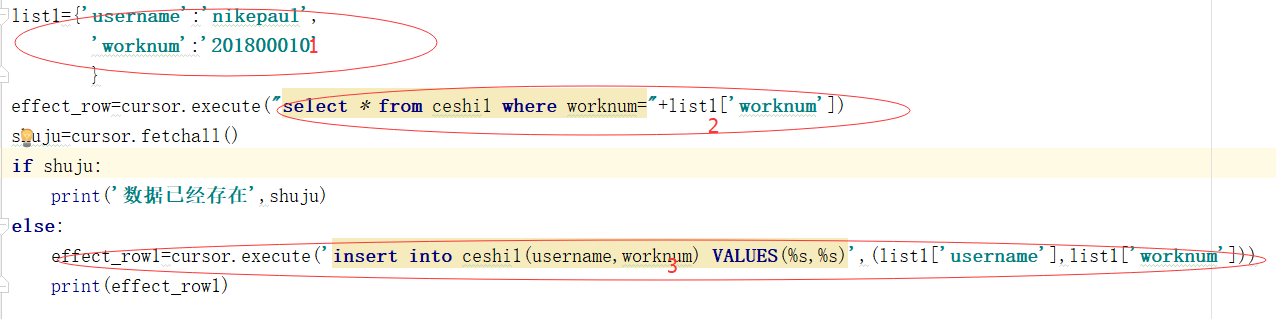
我在1处做了组测试数据,可以看到list1里的worknum数据在数据表中已经存在,在2处进行判断,如果存在则告知数据,已存在,否则插入数据,由于LIST1中数据存在所以打印结果如下:


没有新数据添加进来
现在我改一下list1的内容

我改了下worknum的值,结果如下:
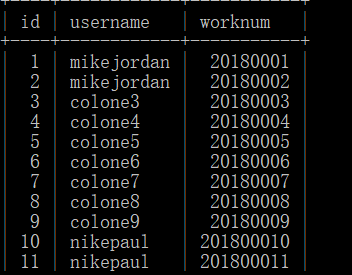

数据表内增加了新的值,依此类推到数据自增,爬虫的时候如何拒绝爬取重复数据,明白了吧