算法描述:
机器学习界的一个普通算法。
从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
算法涉及3个主要因素:
1) 训练数据集
2) 距离或相似度的计算衡量
3) k的大小
算法描述
1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中
2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类
3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别

概述:看离谁近,或长得像。
示例说明:
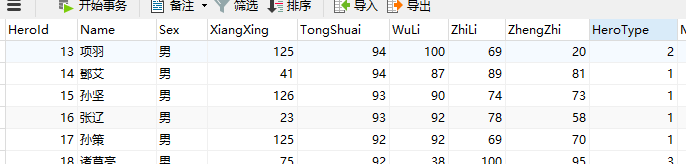
三国游戏数据,根据已有武将四围数据及类型,判断新武将的类型。
原始数据如下图:
代码如下:
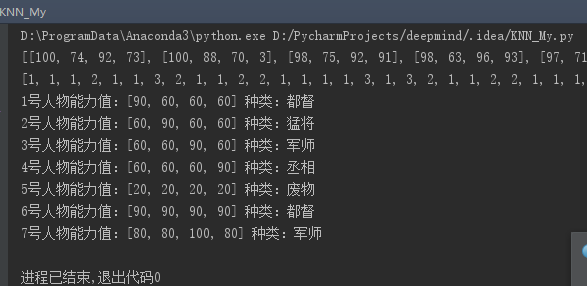
from sklearn import neighbors from sklearn import datasets import numpy import mysqlHelper dataArray = [] #四维数据集 typeArray = [] #类型数据集 labalNames = ['全能','都督','猛将','军师','丞相','废物'] #类型名称 db = mysqlHelper.DBHelp() #引用mysql操作类 list = db.getList('select HeroId,`Name`,TongShuai,WuLi,ZhiLi,ZhengZhi,HeroType from hero limit 0,700') #获取原始数据列表 for item in list: arr = [] arr.append(item[2]) #依次添加数值到新数组 arr.append(item[3]) arr.append(item[4]) arr.append(item[5]) dataArray.append(arr) typeArray.append(item[6]) print(dataArray) #显示四维数据集 print(typeArray) #显示类型数据集 knn = neighbors.KNeighborsClassifier() #引用KNN应用类 dataArray = numpy.array(dataArray) #转换python数组为numpy数组 typeArray = numpy.array(typeArray) model = knn.fit(dataArray,typeArray) #训练机器人 #添加测试数据 testArrays = [[90,60,60,60],[60,90,60,60],[60,60,90,60],[60,60,60,90],[20,20,20,20],[90,90,90,90],[80,80,100,80]] lables = knn.predict(testArrays) #测试并返回结果 for x in range(len(lables)): #打印结果 print(repr(x + 1) + '号人物' + "能力值:" + repr(testArrays[x]) + ' 种类:' + labalNames[lables[x]])
结果如下: