快速排序属性

上一篇文章介绍了 冒泡排序和它的优化。这次介绍的快速排序是冒泡排序演变而来的算法,比冒泡排序要高效的很多。
快速排序之所以快,是因为它使用了分治法。它虽然也是通过不断的比较和移动来实现排序的,只不过它的实现,增大了比较的距离和移动的距离。而冒泡排序只是相邻的比较和交换。
快速排序的思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
从字面上感觉不到它的好处,我们通过一个示例来理解基本的快速排序算法,假设当前数组元素是:5, 1, 9, 3, 7, 4, 8, 6, 2。
基本的快速排序算法
初始状态:5, 1, 9, 3, 7, 4, 8, 6, 2
选择5作为一个基准元素,然后从右向左移动hight下标,进行基准元素和下标为hight 的元素进行比较。
如果基准元素要大,则进行hight的左移一位;如果基准元素要小,则进行元素的交换。
在hight下标左移的过程中,我们目的是找出比基准元素小的,然后进行交换。
交换完之后,进行left的右移,找出比基准元素大的,找到则进行交换。
视频动画
Code

Result
发生交换 [2, 1, 9, 3, 7, 4, 8, 6, 5]
发生交换 [2, 1, 5, 3, 7, 4, 8, 6, 9]
发生交换 [2, 1, 4, 3, 7, 5, 8, 6, 9]
发生交换 [2, 1, 4, 3, 5, 7, 8, 6, 9]
算出枢轴值 5 和对应下标 4
发生交换 [1, 2, 4, 3, 5, 7, 8, 6, 9]
算出枢轴值 2 和对应下标 1
发生交换 [1, 2, 3, 4, 5, 7, 8, 6, 9]
算出枢轴值 4 和对应下标 3
发生交换 [1, 2, 3, 4, 5, 6, 8, 7, 9]
发生交换 [1, 2, 3, 4, 5, 6, 7, 8, 9]
算出枢轴值 7 和对应下标 6
算出枢轴值 8 和对应下标 7
优化枢轴的选取
举一个恰当的例子,假设数组元素是9,8,7,6,5,4,3,2,1。
进行hight左移的时候第一个就发生了交换,1,8,7,6,5,4,3,2,9。嗯看似效率蛮快,但是进行low右移的时候一个个做了不必要的计算,没有一个元素比枢轴值要大。和冒泡排序一样,这一趟进行了8次比较,时间复杂度达到最坏程度O(n^2)。和快排的O(nlongn)相悖。
那拿什么更好的方式选取枢轴值呢?
我看到网上都说是,随机选取一个数作为基准元素。嗯看似一个好的方法,但是和上面大概率出现的最坏情况还是有可能发生的。每次选取枢轴值都有可能是最大的或者最小的。如果是庞大的数据量第一个随机选到了最大的数,程序卡的半死不活的,只有kill掉再重新运行吗?
改进情况,取三数之中的中间数的一个数。什么意思呢?
就是在一组数中取三个关键数字,将中间数作为枢轴,一般可以取左端,右端和中间三个数,也可以随机选取。那你可能说了,要是三个数都是最小的或者都是最大的那什么办呢?
没错,这样选取还是会带来时间上的开销,并不证明选取到一个好的枢轴值。那要是取九数之中的中间数呢?
这当然不是采用随机取九个数然后再排序排一半取中间数那一个。
它是从数组中分三次取样,每次取三个数,三个样品中各取出中间数,然后在这三个中枢当中再取一个中间数作为枢轴。如果一次极端就算了,但是分三次取样还会碰到三次极端那显然是微乎其微的。这样的方法增加选到好的枢轴的概率。
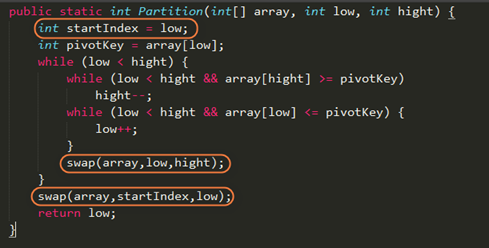
优化不必要的交换
回到基本的快速排序算法,回顾上面的视频动画。我们可以发现,这其中发生了不必要的移动方式。
我们最终要求一趟选的枢轴值,大的数在它的右边,小的数在它左边。但是这个枢轴值每次符合条件去了不该去的地方。我认为它前面的地方不要动,等一趟完了就去自己该去的地方,减少时间上的消耗。
视频动画
Code
Result
发生交换 [5, 1, 2, 3, 7, 4, 8, 6, 9]
发生交换 [5, 1, 2, 3, 4, 7, 8, 6, 9]
发生交换 [4, 1, 2, 3, 5, 7, 8, 6, 9]
算出枢轴值 5 和对应下标 4
发生交换 [3, 1, 2, 4, 5, 7, 8, 6, 9]
算出枢轴值 4 和对应下标 3
发生交换 [2, 1, 3, 4, 5, 7, 8, 6, 9]
算出枢轴值 3 和对应下标 2
发生交换 [1, 2, 3, 4, 5, 7, 8, 6, 9]
算出枢轴值 2 和对应下标 1
发生交换 [1, 2, 3, 4, 5, 7, 6, 8, 9]
发生交换 [1, 2, 3, 4, 5, 6, 7, 8, 9]
算出枢轴值 7 和对应下标 6
算出枢轴值 8 和对应下标 7
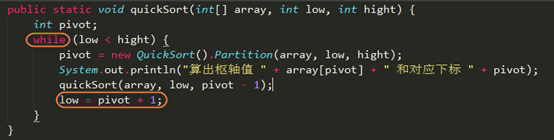
优化递归操作
我们都知道,递归对性能是有一定影响的,quickSort函数尾部有两次递归操作。如果待排序的序列极为极端不平衡,递归的深度几乎接近于n的高度(没有了二分法的优势)。这样的时间复杂度也是达到了最坏的程度O(n^2),而不是平衡时的O(nlogn)。
时间慢也就算了,但是栈的大小也是有限的,每次递归操作都消耗一定的栈空间,函数的参数越多,每次递归调用参数耗费的空间也是越多。
如果能减少递归,性能也因此大大提高。
那拿什么方式优化递归操作呢?
来看下面代码。
Code
Result
发生交换 [2, 1, 9, 3, 7, 4, 8, 6, 5]
发生交换 [2, 1, 5, 3, 7, 4, 8, 6, 9]
发生交换 [2, 1, 4, 3, 7, 5, 8, 6, 9]
发生交换 [2, 1, 4, 3, 5, 7, 8, 6, 9]
算出枢轴值 5 和对应下标 4
发生交换 [1, 2, 4, 3, 5, 7, 8, 6, 9]
算出枢轴值 2 和对应下标 1
发生交换 [1, 2, 3, 4, 5, 7, 8, 6, 9]
算出枢轴值 4 和对应下标 3
发生交换 [1, 2, 3, 4, 5, 6, 8, 7, 9]
发生交换 [1, 2, 3, 4, 5, 6, 7, 8, 9]
算出枢轴值 7 和对应下标 6
算出枢轴值 8 和对应下标 7
执行结果之后和前面两个结果无异。这是一个很好的方法。我们把if改成while,然后一次递归之后,low已经没有用处了,所以把pivot + 1赋值给low作为下一个参数。结果你也看到了,结果都相同。
因此采用迭代而不是递归的方法可以缩减堆栈深度,从而提高了整体性能。