一. IO的分类
从数据来源或者说是操作对象角度看,IO 类可以分为:

1. 文件(file):FileInputStream、FileOutputStream、FileReader、FileWriter
2. 管道操作:PipedInputStream、PipedOutputStream、PipedReader、PipedWriter
3. 数组([]):
-
- 字节数组(byte[]):ByteArrayInputStream、ByteArrayOutputStream
- 字符数组(char[]):CharArrayReader、CharArrayWriter
4. 缓冲操作:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter
5. 基本数据类型:DataInputStream、DataOutputStream
6. 对象序列化反序列化:ObjectInputStream、ObjectOutputStream
7. 转换:InputStreamReader、OutputStreWriter
8. 打印:PrintStream、PrintWriter
数据源节点也可以再进行二次处理,使数据更加容易使用,所以还可以划分成节点流和处理流。
从数据传输方式或者说是运输方式角度看,可以将 IO 类分为:
1、字节流
2、字符流

字节流是以一个字节单位来运输的,比如一杯一杯的取水。而字符流是以多个字节来运输的,比如一桶一桶的取水,一桶水又可以分为几杯水。
字节流和字符流的区别:
字节流读取单个字节,字符流读取单个字符(一个字符根据编码的不同,对应的字节也不同,如 UTF-8 编码是 3 个字节,中文编码是 2 个字节。)字节流用来处理二进制文件(图片、MP3、视频文件),字符流用来处理文本文件(可以看做是特殊的二进制文件,使用了某种编码,人可以阅读)。简而言之,字节是个计算机看的,字符才是给人看的。
不可否认,Java IO 相关的类确实很多,但我们并不是所有的类都会用到,我们常用的也就是文件相关的几个类,如文件最基本的读写类 File 开头的、文件读写带缓冲区的类 Buffered 开头的类,对象序列化反序列化相关的类 Object 开头的类。
从流的流入和流出可分为:
1. 输入流
2. 输出流
这里暂时不做讲述
二. IO类和相关方法
IO 类虽然很多,但最基本的是 4 个抽象类:InputStream、OutputStream、Reader、Writer。最基本的方法也就是一个读 read() 方法、一个写 write() 方法。方法具体的实现还是要看继承这 4 个抽象类的子类,毕竟我们平时使用的也是子类对象。这些类中的一些方法都是(Native)本地方法、所以并没有 Java 源代码,这里给出笔者觉得不错的 Java IO 源码分析 传送门,按照上面这个思路看,先看子类基本方法,然后在看看子类中还新增了那些方法,相信你也可以看懂的,我这里就只对上后面说的常用的类进行总结。
先来看 InputStream 和 OutStream 中的方法简介,因为都是抽象类、大都是抽象方法、所以就不贴源码喽!注意这里的读取和写入,其实就是获取(输入)数据和输出数据。


再来看 Reader 和 Writer 类中的方法,你会发现和上面两个抽象基类中的方法很像。


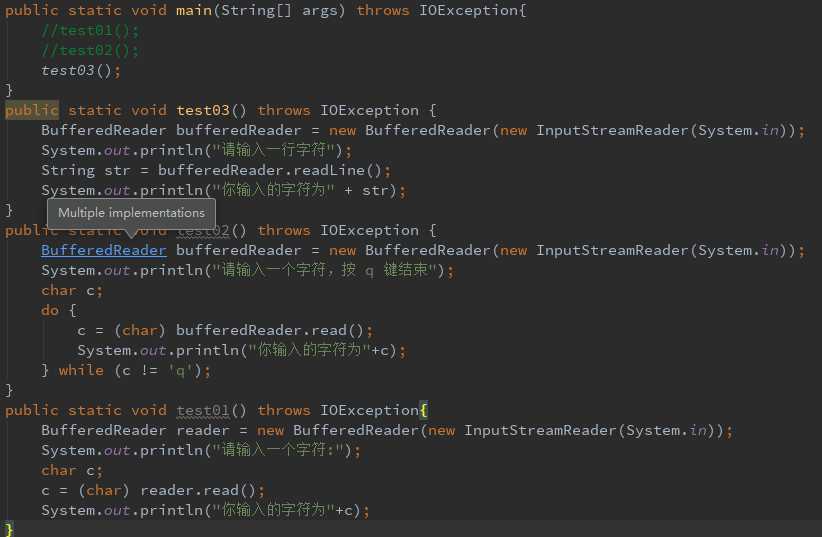
1、读取控制台中的输入
至于控制台的输出,我们其实一直都在使用呢,System.out.println() ,out 其实是 PrintStream 类对象的引用,PrintStream 类中当然也有 write() 方法,但是我们更常用 print() 方法和 println() 方法,因为这两个方法可以输出的内容种类更多,比如一个打印一个对象,实际调用的对象的 toString() 方法。
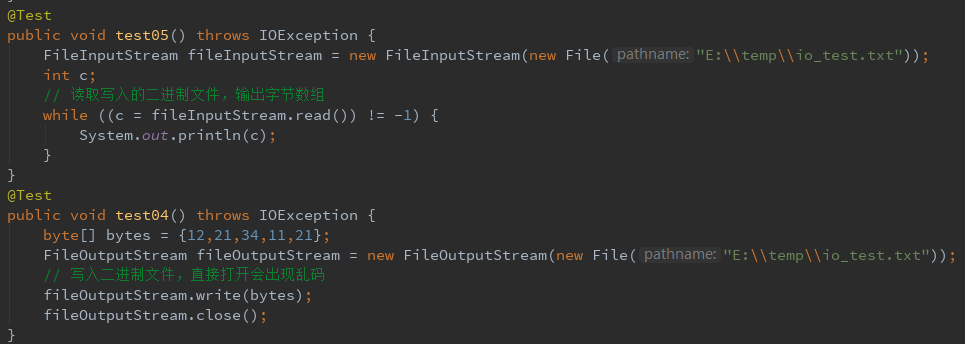
2、二进制文件的写入和读取
注意这里文件的路径,可以根据自己情况改一下,虽然这里的文件后缀是txt,但该文件却是一个二进制文件,并不能直接查看。
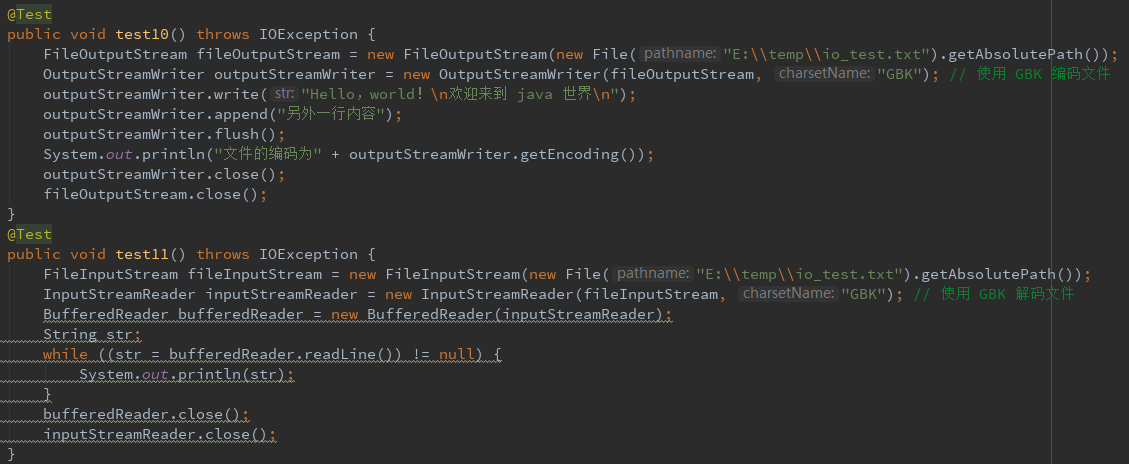
3、文本文件的写入和读取
write() 方法和 append() 方法并不是像方法名那样,一个是覆盖内容,一个是追加内容,append() 内部也是 write() 方法实现的,也非说区别,也就是 append() 方法可以直接写 null,而 write() 方法需要把 null 当成一个字符串写入,所以两者并无本质的区别。需要注意的是这里并没有指定文件编码,可能会出现乱码的问题。

使用字节流和字符流的转换类 InputStreamReader 和 OutputStreamWriter 可以指定文件的编码,使用 Buffer 相关的类来读取文件的每一行。
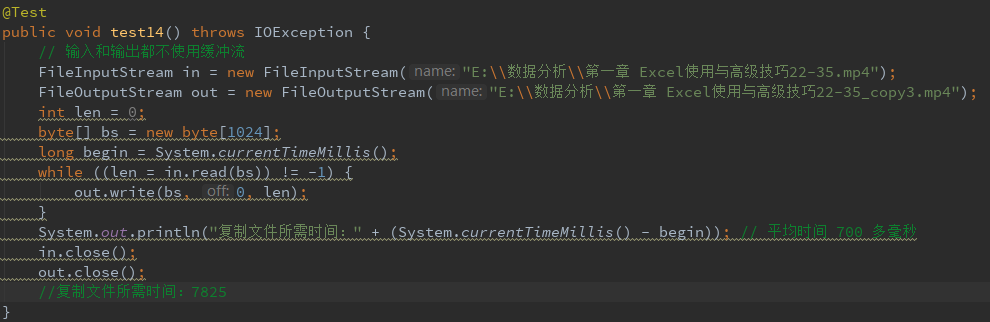
4、复制文件
不使用缓冲对文件复制时间的影响,文件的复制实质还是文件的读写。缓冲流是处理流,是对节点流的装饰。
注:这里的时间是在我的电脑上测试得到的,只是为了说明使用缓冲对文件的读写有好处。
输入输出都是用缓冲流:

只有输入使用缓冲流

输入和输出都不使用缓冲流
关于序列化和反序列化的内容,下节说