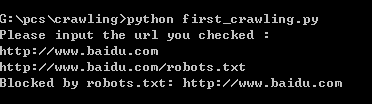
小白新手完全不懂的什么,还有一个robots.txt限制文件,稀里糊涂的 还是百度 可以看一下:http://www.baidu.com/robots.txt
里面会有一些限制,常见的一些配置:
1. 允许所有的robot访问
User-agent: *
Allow: / #(允许根目录==所有目录)
或者
User-agent: *
Disallow: #(注意:Disallow是空的。没有限制==所有)
2. 禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: / #(注意:Disallow是限制根目录==所有目录)
3. 仅禁止Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
4. 仅允许Baiduspider访问您的网站
User-agent: Baiduspider
Disallow:
5. 禁止spider访问特定目录
User-agent: *
Disallow: /cgi-bin/
6. 允许访问特定目录中的部分url
User-agent: *
Allow: /cgi-bin/see
Disallow: /~joe/
验证用户的代码:
agent = 用户名
rp = robotparser.RobotFileParser()
url = 'http://www.baidu.com'
robots_url = 'http://www.baidu.com/robots.txt'
rp.set_url(robots_url)
rp.read()
if rp.can_fetch(agent, url):
#如果用户被robots.txt允许 返回true
#如果用户不被robots.txt允许 返回false
根据这个robot.txt文件的内容,编写爬虫时,去匹配一下,是否有权限
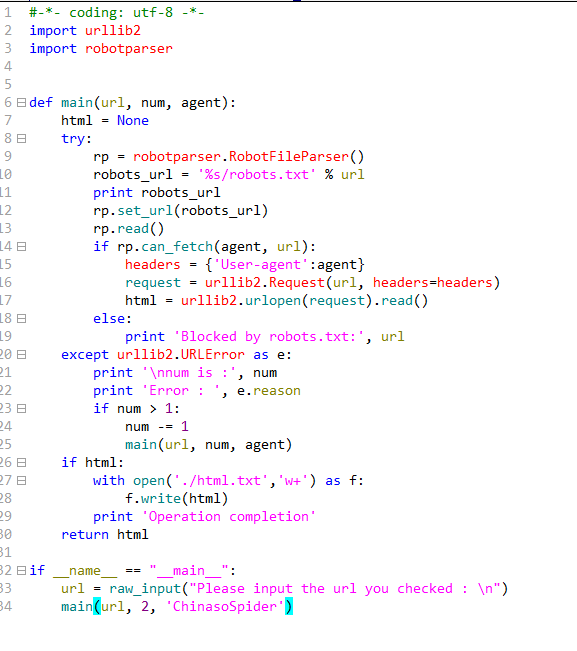
百度允许的用户:ChinasoSpider(在百度的robot.txt中),去验证
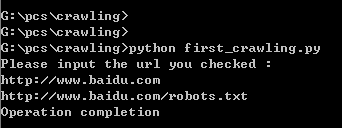
自己随便写的用户:zzf,去验证