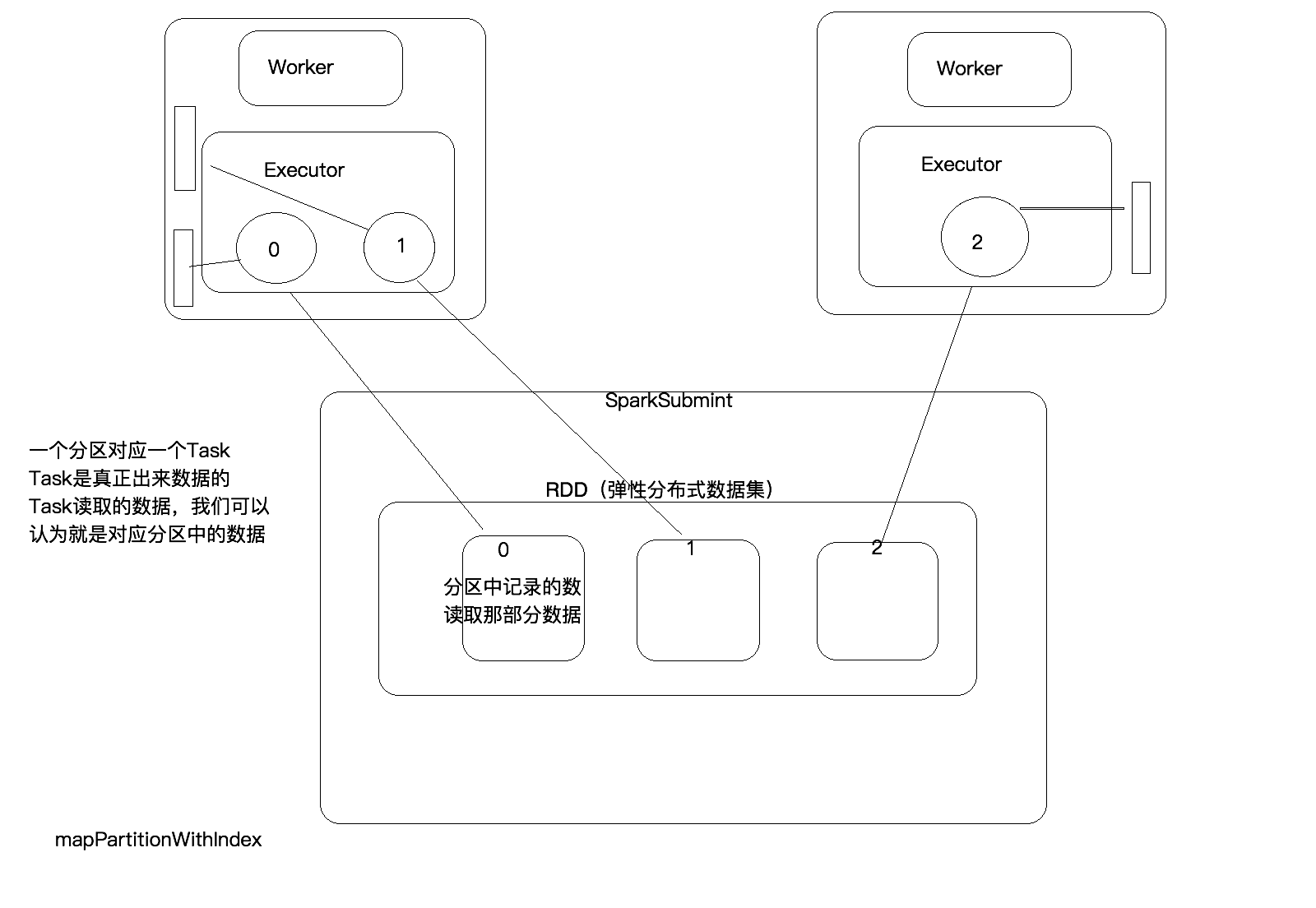
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,
他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据)
RDD是一个代理,你对代理进行操作,他会生成Task,帮你计算
你操作这个代理,就像操作本地集合一样,不用关心任务调度,容错等
RDD的属性
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”
val r1 = sc.textFile("hdfs://hdp-02:9000/wc")
r1.count //这样就统计出有多少行
创建RDD的方式
生成一个RDD
sc.textFile("hdfs://hdp-01:9000/wc")
源代码还是hadoop的API
RDD是一个基本的抽象
RDD的算子一类是Transformation(Lazy)
一种是Action(触发任务执行)
创建方式
1。通过外部的储存系统创建RDD
val rdd1 = sc.textFile("hdfs://hdp-01:9000/wc")
2.将Driver的scala集合通过并行化的方式编程RDD(学习,实验
val arr = Array(1,2,3,4,5,6)
val rdd2 = sc.parallelize(arr) //此时rdd2为集合转化成的一个RDD
3.条用一个已经存在的RDD的Transformation,生成一个新的RDD
val rdd3 = rdd.map(_ * 10))//这个rdd3就是通过rdd2转化而得到的
#RDD中的常用算子(方法)
#常用Transformation(即转换,延迟加载)
//特点是1.lazy
//2.生成新的RDD
#通过并行化scala集合创建RDD
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
#查看该rdd的分区数量
rdd1.partitions.length
val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))//把list转化成rdd
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x,true)//按照本身的数字排序
val rdd3 = rdd2.filter(_>10) //过滤出rdd2中大于10的
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x+"",true)//传进来的排序规则是按照字符串排序的,下同
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x.toString,true)
val rdd4 = sc.parallelize(Array("a b c", "d e f", "h i j"))
rdd4.flatMap(_.split(' ')).collect
val rdd5 = sc.parallelize(List(List("a b c", "a b b"),List("e f g", "a f g"), List("h i j", "a a b")))
List("a b c", "a b b") =List("a","b",))
rdd5.flatMap(_.flatMap(_.split(" "))).collect
#union求并集,注意类型要一致
val rdd6 = sc.parallelize(List(5,6,4,7))
val rdd7 = sc.parallelize(List(1,2,3,4))
val rdd8 = rdd6.union(rdd7)//将两个Rdd合成一个rdd 不去重
rdd8.distinct.sortBy(x=>x).collect
#intersection求交集
val rdd9 = rdd6.intersection(rdd7) //将两个rdd合成一个交集的rdd
#join(连接)
val rdd11 = sc.parallelize(List(("tom", 1), ("jerry", 2), ("kitty", 3)))
val rdd12 = sc.parallelize(List(("jerry", 9), ("tom", 8), ("shuke", 7), ("tom", 2)))
val rdd13 = rdd11.join(rdd12)
//结果为Array[(String, (Int, Int))] = Array((tom,(1,8)), (tom,(1,2)), (jerry,(2,9)))
val rdd13 = rdd11.leftOuterJoin(rdd12)
//结果为Array[(String, (Int, Option[Int]))] = Array((tom,(1,Some(8))), (tom,(1,Some(2))), (kitty,(3,None)), (jerry,(2,Some(9))))
val rdd13 = rdd11.rightOuterJoin(rdd12)
//结果为Array[(String, (Option[Int], Int))] = Array((tom,(Some(1),8)), (tom,(Some(1),2)), (shuke,(None,7)), (jerry,(Some(2),9)))
#groupByKey
val rdd3 = rdd1 union rdd2
rdd3.groupByKey
//Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(8, 2, 1)), (shuke,CompactBuffer(7)), (kitty,CompactBuffer(3)), (jerry,CompactBuffer(2, 9)))
rdd3.groupByKey.map(x=>(x._1,x._2.sum))//结果与下同
rdd3.groupByKey.mapValues(_.sum).collect
//Array[(String, Int)] = Array((tom,11), (shuke,7), (kitty,3), (jerry,11))
#WordCount
//reduceByKey是先局部聚合 然后shuffle,shuffle的次数少,然后groupByKey再map的话是要把很多(单词,1)shuffle到一台机器上再聚合,这样shuffle的次数会很多
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect
#cogroup
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//Array[(String, (Iterable[Int], Iterable[Int]))] = Array((tom,(CompactBuffer(1, 2),CompactBuffer(1))),
//(shuke,(CompactBuffer(),CompactBuffer(2))), (kitty,(CompactBuffer(2),CompactBuffer())), (jerry,(CompactBuffer(3),CompactBuffer(2))))
val rdd3 = rdd1.cogroup(rdd2)
val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum))
#cartesian笛卡尔积
val rdd1 = sc.parallelize(List("tom", "jerry"))
val rdd2 = sc.parallelize(List("tom", "kitty", "shuke"))
val rdd3 = rdd1.cartesian(rdd2)
###################################################################################################
#spark action
#后面2位一个分区
#创建几个分区就会生成几个task,这几个task会将数据进行处理然后写入到hdfs
#几个task就会生成几个文件
#如果没有指定的话,那么task的数据跟启动时设置的core的数量一样
#但并不是越多越好比如:你电脑上可以有8个线程同时运行,但你可以在你电脑上启动80个线程,他对于这80个线程是每8个线程作为一个批次进行切换的
val rdd1 = sc.parallelize(List(1,2,3,4,5), 2)
#collect
rdd1.collect
#reduce
val r = rdd1.reduce(_+_)
#count
rdd1.count
#top
rdd1.top(2)
#take
rdd1.take(2)
#first(similer to take(1))
rdd1.first
#takeOrdered
rdd1.takeOrdered(3)
#查看一个rdd有几个分区
rdd1.partitions.length
#rdd最小的分区数量是2
#这样会先把test下的左右文件大小加在一起, 然后再重新计算应该分区的大小
#触发Action的时候才会指定有几个分区
sc.textFile("hdfs://hdp-01:9099/test)
mapPartitionsWithIndex
一次拿出一个分区(分区中并没有数据,而是记录尧都区那些数据,真正生成的Task弧度去多条数据)
,并且可以将分区的编号取出来,
功能:取出分区中对应的数据时,还可以将分区的编号取出来,知道数据是属于那个分区
//该函数的功能是将对应分区中的数据取出来,并且带上分区编号
val func = (index: Int, it: Iterator[Int]) => {
it.map(e => s"part: $index, ele: $e")
}
val rdd1 = rdd.mapPartitionsWithIndex(func)
aggregate方法
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
rdd1.aggregate(0)(_+_,_+_) //结果为45,第一个括号是初始值,第二个括号表达先是对每个分区的操作,再总的操作
//下面这个意思是先求出每个分区的最大值,然后加起来
rdd1.aggregate(0)(math.max(_,_), _+_)
#结果是25第一个分区1,2,3,和初始值比结果为5,第二个分区4,5,6,结果为6,第三个为9,这三个最大值加起来,再加上一个初始值
rdd1.aggregate(5)(math.max(_._), _+_)
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
}
pairRDD.mapPartitionsWithIndex(func2).collect
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
// Array[(String, Int)] = Array((dog,112), (cat,219), (mouse,206)) 因为cat在第一个分区加了100,在第二个分区也加了100,所以加了200,dog只在一个分区里出现,加了100
pairRDD.aggregateByKey(100)(_+_, _ + _).collect
collection.map
var rdd = sc.parallelize(List(("a",1), ("b",2)))
rdd.mapValues(_*100)
rdd.mapValues(_*100).collectAsMap
collect的执行过程
rdd执行action的方法之后,会从后往前推
知道找到一个数据源,有几个分区就会在driver端生成几个task ,然后发送给worker
worker会找到数据源,下载数据,边下载边计算,
计算完之后会发送给driver端(如果数据太大的话,不要把数据收集到driver端,在写入数据库啥的,这样driver是一个瓶颈,直接把计算结果写入到数据库或者啥的)
countByKey
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey //scala.collection.Map[String,Long] = Map(a -> 1, b -> 2, c -> 2)
rdd1.countByValue//scala.collection.Map[(String, Int),Long] = Map((b,2) -> 2, (c,2) -> 1, (c,1) -> 1, (a,1) -> 1)
filterByRange
val rdd1 = sc.parallelize(List(("e", 5),("b", 5),("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")//按照key在b,到d之间的范围取出
rdd2.colllect
flatMapValues
val a = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
rdd3.flatMapValues(_.split(" "))//把value进行flatmap,再和key结合
foreach
这是一个action,但不会发生在driver,会在executor执行,在driver端是看不到的
foreachPartition
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreachPartition(x => println(x.reduce(_ + _)))//一次拿出来一个分区,然后打印出每个分区中的数据进行聚合
#这说明任务执行的时候是在executor执行的
RDD的产生和分配