人工智能的三个发展阶段
1. 计算智能
即特定领域中规则明确的数据快速处理智能,机器已经超越人类
2. 感知智能
让计算机具备视觉,听觉等智能,比如语音识别,人脸识别,已经取得进步
3. 认知智能
与人类语言,知识逻辑相关的智能,让机器掌握人类的语言和知识体系,理解逻辑
什么是知识图谱
本质上,是一种揭示实体之间关系的语义网络
信息是指外部的客观事实。举例:这里有一瓶水,它现在是7°。
知识是对外部客观规律的归纳和总结。举例:水在零度的时候会结冰。
也可以理解成知识是在信息的基础上建立实体间的联系
知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即,不要无意义的字符串,而是获取字符串背后隐含的对象或事物。
知识图谱是由一些相互连接的实体和他们的属性构成的。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。在知识图谱中,我们用RDF形式化地表示这种三元关系。RDF(Resource Description Framework),即资源描述框架,是W3C制定的,用于描述实体/资源的标准数据模型。RDF图中一共有三种类型,International Resource Identifiers(IRIs),blank nodes 和 literals。下面是SPO每个部分的类型约束:
00001. Subject可以是IRI或blank node。
00002. Predicate是IRI。
00003. Object三种类型都可以。
IRI我们可以看做是URI或者URL的泛化和推广,它在整个网络或者图中唯一定义了一个实体/资源,和我们的身份证号类似。
literal是字面量,我们可以把它看做是带有数据类型的纯文本,比如我们在第一个部分中提到的罗纳尔多原名可以表示为"Ronaldo Luís Nazário de Lima"^^xsd:string。
blank node简单来说就是没有IRI和literal的资源,或者说匿名资源。
那么“罗纳尔多的中文名是罗纳尔多·路易斯·纳扎里奥·达·利马”这样一个三元组用RDF形式来表示就是:
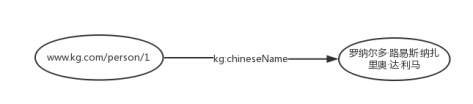
"www.kg.com/person/1"是一个IRI,用来唯一的表示“罗纳尔多”这个实体。"kg:chineseName"也是一个IRI,用来表示“中文名”这样一个属性。"kg:"是RDF文件中所定义的prefix,如下所示。
@prefix kg: <http://www.kg.com/ontology/>
即,kg:chineseName其实就是"http:// www.kg.com/ontology/chineseName"的缩写。
语义网络,语义网,链接数据和知识图谱
1. 语义网络
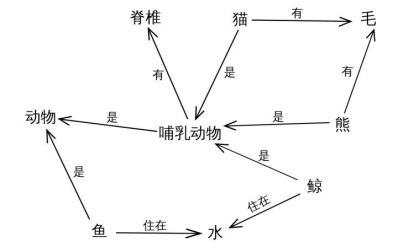
是知识表示的一种形式,知识表示具体可看下面
语义网络的优点:
1. 容易理解和展示。
2. 相关概念容易聚类。
语义网络的缺点:
1. 节点和边的值没有标准,完全是由用户自己定义。
2. 多源数据融合比较困难,因为没有标准。
3. 无法区分概念节点和对象节点。
4. 无法对节点和边的标签(label,我理解是schema层,后面会介绍)进行定义。
对于语义网络的缺点1和2,RDF提出在节点和边的取值上增加了约束,制定了统一的标准。为多源的数据融合提供了便利。(关于RDF,具体看下面)
比如:
猫 rdf:type 哺乳动物
熊 rdf:type 哺乳动物
那么对于缺点3,先解释一下,比如有两个语义网络,A中熊是哺乳动物的实例,B中熊是哺乳动物的子类(熊还可以分为很多类的熊)这样不仅会造成理解困难,还会在融合时造成数据冲突。解决方案是RDFS/OWL,来形式化的声明一个类
哺乳动物 rdf:type rdfs:Class
或者
哺乳动物 rdf:type owl:Class
通过RDFS也可以声明一个子类:
熊 rdf:type rdfs:Class
熊 rdfs:subClassOf 哺乳动物
或者声明一个实例
熊 rdf:type 哺乳动物
我们也可以把rdf:type用a代替,即:
熊 a 哺乳动物
2. 语义网和链接数据
都是和万维网有关的,语义网和链接数据倾向于描述万维网中资源、数据之间的关系。只不过是描述的角度不同,都是一系列的技术标准。比如,我们浏览一个网页,我们能够轻松理解网页上面的内容,而计算机只知道这是一个网页。网页里面有图片,有链接,但是计算机并不知道图片是关于什么的,也不清楚链接指向的页面和当前页面有何关系。语义网正是为了使得网络上的数据变得机器可读而提出的一个通用框架。“Semantic”就是用更丰富的方式来表达数据背后的含义,让机器能够理解数据。“Web”则是希望这些数据相互链接,组成一个庞大的信息网络,正如互联网中相互链接的网页,只不过基本单位变为粒度更小的数据,
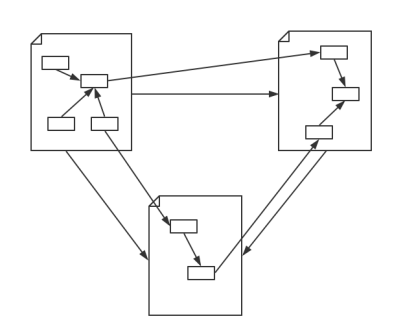
链接数据起初是用于定义如何利用语义网技术在网上发布数据,其强调在不同的数据集间创建链接。当它指语义网技术时,它更强调“Web”,弱化了“Semantic”的部分。对应到语义网技术栈,它倾向于使用RDF和SPARQL(RDF查询语言)技术,对于Schema层的技术,RDFS或者OWL,则很少使用。链接数据应该是最接近知识图谱的一个概念,从某种角度说,知识图谱是对链接数据这个概念的进一步包装。(其实不太懂这个,有点抽象了)
链接数据和知识图谱最大的区别在于:
1. 链接数据每一个圆圈代表一个独立存在和维护的知识图谱;链接数据更强调不同RDF数据集(知识图谱)的相互链接。
2. 知识图谱不一定要链接到外部的知识图谱(和企业内部数据通常也不会公开一个道理),更强调有一个本体层来定义实体的类型和实体之间的关系。另外,知识图谱数据质量要求比较高且容易访问,能够提供面向终端用户的信息服务(查询、问答等等)。
RDF,RDFS与OWL
你要把天下所有的信息以同一种方式描述了有什么好办法?
rdf就是以资源+属性的方式给了一种答案。属性嘛,包括属性名+值
rdf的一个原则是,用uri给资源和属性取名
从而保证语义的唯一性
RDF(Resource Description Framework),即资源描述框架
它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。
形式上是三元组
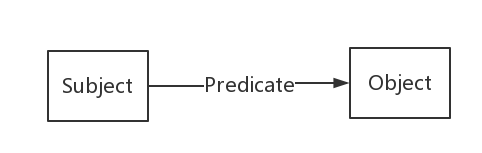
它受到元数据标准、框架系统、面向对象语言等多方面的影响,被用来描述各种网络资源,其出现为人们在Web上发布结构化数据提供一个标准的数据描述框架。
从内容上看三元组的结构为 “资源-属性-属性值” ,资源实体由URI表示,属性值可以是另一个资源实体的URI,也可以是某种数据类型的值,也称为literals(字面量)。
主语和宾语也可以由第三种结点类型空节点(blank nodes)表示。blank node简单来说就是没有IRI和literal的资源,或者说匿名资源。
RDF的序列化
就是我们怎么存储和传输RDF数据。目前,RDF序列化的方式主要有:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD等几种。
RDF/XML,顾名思义,就是用XML的格式来表示RDF数据。之所以提出这个方法,是因为XML的技术比较成熟,有许多现成的工具来存储和解析XML。然而,对于RDF来说,XML的格式太冗长,也不便于阅读,通常我们不会使用这种方式来处理RDF数据。
N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。开放领域知识图谱DBpedia通常是用这种格式来发布数据的。
Turtle, 应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好。
Rdfa, 即“The Resource Description Framework in Attributes”,是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将RDF数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息。
JSON-LD,即“JSON for Linking Data”,用键值对的方式来存储RDF数据。感兴趣的读者可以参考此网站。
Example1 N-Triples:
<http://www.kg.com/person/1> <http://www.kg.com/ontology/chineseName> "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/career> "足球运动员"^^string.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/fullName> "Ronaldo Luís Nazário de Lima"^^string.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/birthDate> "1976-09-18"^^date.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/height> "180"^^int.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/weight> "98"^^int.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/nationality> "巴西"^^string.
<http://www.kg.com/person/1> <http://www.kg.com/ontology/hasBirthPlace> <http://www.kg.com/place/10086>.
<http://www.kg.com/place/10086> <http://www.kg.com/ontology/address> "里约热内卢"^^string.
<http://www.kg.com/place/10086> <http://www.kg.com/ontology/coordinate> "-22.908333, -43.196389"^^string.
Example2 Turtle:
@prefix person: <http://www.kg.com/person/> .
@prefix place: <http://www.kg.com/place/> .
@prefix : <http://www.kg.com/ontology/> .
person:1 :chineseName "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string;
:career "足球运动员"^^string;
:fullName "Ronaldo Luís Nazário de Lima"^^string;
:birthDate "1976-09-18"^^date;
:height "180"^^int;
:weight "98"^^int;
:nationality "巴西"^^string;
:hasBirthPlace place:10086.
place:10086 :address "里约热内卢"^^string;
:coordinate "-22.908333, -43.196389"^^string.
RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述。就以罗纳尔多这个知识图为例,RDF能够表达罗纳尔多和里约热内卢这两个实体具有哪些属性,以及它们之间的关系。但如果我们想定义罗纳尔多是人,里约热内卢是地点,并且人具有哪些属性,地点具有哪些属性,人和地点之间存在哪些关系,这个时候RDF就表示无能为力了。
RDFS和OWL这两种技术或者说模式语言/本体语言(schema/ontology language)解决了RDF表达能力有限的困境。
用过Mysql的读者应该知道,其database也被称作schema。这个schema和我们这里提到的schema language十分类似。我们可以认为数据库中的每一张表都是一个类(Class),表中的每一行都是该类的一个实例或者对象(学过java等面向对象的编程语言的读者很容易理解)。表中的每一列就是这个类所包含的属性。如果我们是在数据库中来表示人和地点这两个类别,那么为他们分别建一张表就行了;再用另外一张表来表示人和地点之间的关系。RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类似的类定义及其属性的定义。
### 这里我们用词汇rdfs:Class定义了“人”和“地点”这两个类。
:Person rdf:type rdfs:Class.
:Place rdf:type rdfs:Class.
### rdfs当中不区分数据属性和对象属性,词汇rdf:Property定义了属性,即RDF的“边”。
:chineseName rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:career rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:fullName rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
RDFS几个比较重要,常用的词汇:
1. rdfs:Class. 用于定义类。
2. rdfs:domain. 用于表示该属性属于哪个类别。
3. rdfs:range. 用于描述该属性的取值类型。
4. rdfs:subClassOf. 用于描述该类的父类。比如,我们可以定义一个运动员类,声明该类是人的子类。
5. rdfs:subProperty. 用于描述该属性的父属性。比如,我们可以定义一个名称属性,声明中文名称和全名是名称的子类。
其实rdf:Property和rdf:type也是RDFS的词汇,因为RDFS本质上就是RDF词汇的一个扩展。
RDFS本质上是RDF词汇的一个扩展。后来人们发现RDFS的表达能力还是相当有限,因此提出了OWL。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。
OWL有两个主要的功能:
1. 提供快速、灵活的数据建模能力。
2. 高效的自动推理。
### 这里我们用词汇owl:Class定义了“人”和“地点”这两个类。
:Person rdf:type owl:Class.
:Place rdf:type owl:Class.
### owl区分数据属性和对象属性(对象属性表示实体和实体之间的关系)。词汇owl:DatatypeProperty定义了数据属性,owl:ObjectProperty定义了对象属性。
:chineseName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:birthDate rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:date .
:hasBirthPlace rdf:type owl:ObjectProperty;
rdfs:domain :Person;
rdfs:range :Place .
描述属性特征的词汇
1. owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
2. owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
3. owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
4. owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
1. owl:equivalentClass. 表示某个类和另一个类是相同的。
2. owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
3. owl:sameAs. 表示两个实体是同一个实体。
本体映射主要用在融合多个独立的Ontology(Schema)。举个例子,张三自己构建了一个本体结构,其中定义了Person这样一个类来表示人;李四则在自己构建的本体中定义Human这个类来表示人。当我们融合这两个本体的时候,就可以用到OWL的本体映射词汇。回想我们在第二篇文章中提到的Linked Open Data,如果没有OWL,我们将无法融合这些知识图谱。
<http://www.zhangsan.com/ontology/Person> rdf:type owl:Class .
<http://www.lisi.com/ontology/Human> rdf:type owl:Class .
<http://www.zhangsan.com/ontology/Person> owl:equivalentClass <http://www.lisi.com/ontology
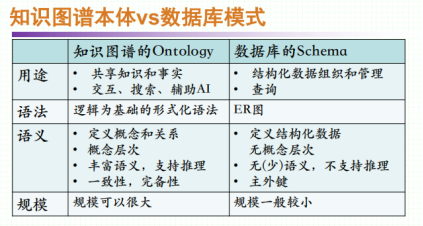
知识图谱的构建
1. 自顶向下
指的是先定义好本体和数据模式,再将实体加入到数据库需要利用一些现有的结构化的知识库作为基础知识库。
2. 自底向上
从一些开放的链接数据中提取出实体,选择其中置信度较高的加入到知识库,再构建实体与实体之间的联系。
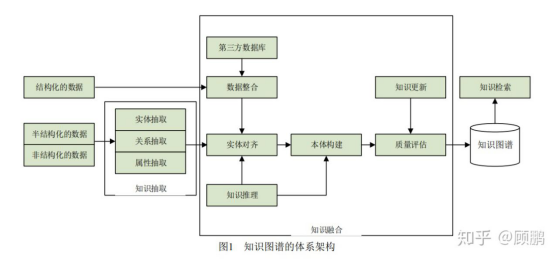
知识图谱的体系架构
1. 逻辑结构
(1) 数据层
数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的 Neo4j、Twitter 的 FlockDB、JanusGraph 等。
(2) 模式层
在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,
2. 体系架构
什么是机器学习,深度学习
机器学习
机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术。研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务;相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。这里有三个重要的信息:1、“机器学习”是“模拟、延伸和扩展人的智能”的一条路径,所以是人工智能的一个子集;2、“机器学习”是要基于大量数据的,也就是说它的“智能”是用大量数据喂出来的;3、正是因为要处理海量数据,所以大数据技术尤为重要;“机器学习”只是大数据技术上的一个应用。常用的10大机器学习算法有:决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔科夫。
从学习方法上来分,机器学习算法可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习。
深度学习
深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。最显著的应用是计算机视觉和自然语言处理(NLP)领域。显然,“深度学习”是与机器学习中的“神经网络”是强相关,“神经网络”也是其主要的算法和手段;或者我们可以将“深度学习”称之为“改良版的神经网络”算法。深度学习又分为卷积神经网络(Convolutional neural networks,简称CNN)和深度置信网(Deep Belief Nets,简称DBN)。其主要的思想就是模拟人的神经元,每个神经元接受到信息,处理完后传递给与之相邻的所有神经元即可。
神经网络的计算量非常大,而GPU的出现让深度学习快速发展。
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
深度学习和知识图谱
深度学习在一个领域/任务是否成功主要由能否提供的信息量来决定,而信息量则有数据条目和每条数据特征个数两个维度来共同决定。
图,是描述对象与对象之间最有效的形式。如果深度学习想要进行进一步的突破,学习理解图,或者寻求一种和图进行结合的手段是取得突破的最重要的方式,尤其是在像反欺诈,反洗钱,社交网络分析等场景
知识图谱则是图的升级,它利用了图的结构,将事物背后更高层的背景知识串联在了一起,使得图不光光可以进行直接联系的描述,同时也描述了隐藏在背景知识下的隐藏的联系。
简单来说,加入用购物场景来打比方,图可以通过A用户购买了商品1和商品2去创建一种直接的关系。而知识图谱所创建的是商品1和商品2直接的隐藏的背景知识关系,例如商品1和商品2的颜色是一样的,商品1属于奢侈品而商品2同样属于奶制品中的较为昂贵的产品
知识图谱为深度学习提供了最重要的两样东西,一种是联系的描述,一种则是背景知识的描述
深度学习为知识图谱带来了什么
1、知识获取
知识图谱的构建依赖于大量的知识,而大部分的信息都是非机构化的,利用深度学习技术是解决知识获取的重要手段。
2、表示学习与图谱推理
尽管现在大规模知识图谱层出不穷,但依然面临严重的知识不全的问题,补全知识图谱的一种方式是从已有的知识中推理出新的知识,补全缺失的连接,知识图谱表示学习可被用来解决这一问题。
知识图谱表示学习将知识图谱中的元素映射到向量空间,为它们学习向量空间的表示,并借由向量空间表示之间的计算来拟合三元组的真值,从而达到补全知识图谱的目的。
知识图谱和传统知识库,数据库关系
知识图谱是在传统知识库的基础发展而来,优势是包含语义关系,可以进行一系列的推理。但是缺乏直接的有效处理工具,大规模的图谱数据往往需要借助数据库的技术。
知识表示
将关于世界的信息表示为符合机器处理的模式,用于模拟人对世界的认识和推理。已解决人工智能中的复杂任务。
许多的智能系统对于问题的求解都是基于对解答的一种搜索。
不过,对于搜索之前,要想办法吧这个问题用某种方法表示出来可能涉及状态空间、问题归约、语义网络、框架或谓词公式,或者把问题表示为一条要证明的定理,或者采用结构化方法等。
对于传统人工智能问题,任何比较复杂的求解技术都离不开两方面的内容一一表示与搜索。对于同一问题可以有多种不同的表示方法,这些表示具有不同的表示空间。问题表示的优劣,对求解结果及求解效率影响甚大。
1. 语义网络
有节点:表示各种食物,概念,情况,属性等,每个节点有若干属性
边:表示一种语义联系
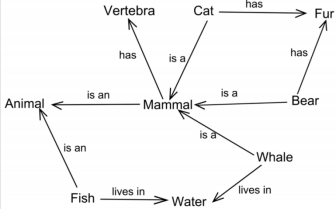
2. 产生式系统
是行为规则的集合
一条规则包括前提(if)和动作(then)

3. 框架系统
心理学的研究结果表明,在人类日常的思维和理解活动中,当分析和解释遇到新情况时,要使用过去经验积累的知识。这些知识规模巨大而且以很好的组织形式保留在人们的记忆中。例如,当走进一家从未来过的饭店时,根据以往的经验,可以预见在这家饭店将会看到菜单、桌子、服务员等。当走进教室时,可以预见在教室里可以看到椅子、黑板等。
人们试图用以往的经验来分析解释当前所遇到的情况,但无法把过去的经验一一都存在脑子里,而只能以一个通用的数据结构的形式存储以往的经验。这样的数据结构称为框架( frame)。框架提供了一个结构,一种组织。在这个结构或组织中,新的资料可以用经验中得到的概念来分析和解释。因此,框架也是一种结构化表示法。

感觉就是一张表。。
4. 概念图
有数学逻辑支撑的知识表示
以谓词形式来表示动作的主体、客体,是一种叙述性知识表示方法。利用逻辑公式,人们能描述对象、性质、状况和关系。它主要用于自动定理的证明。逻辑表示法主要分为命题逻辑和谓词逻辑。
逻辑表示研究的是假设与结论之间的蕴涵关系,即用逻辑方法推理的规律。它可以看成自然语言的一种简化形式,由于它精确、无二义性,容易为计算机理解和操作,同时又与自然语言相似。
命题逻辑是数理逻辑的一种,数理逻辑是用形式化语言(逻辑符号语言)进行精确(没有歧义)的描述,用数学的方式进行研究。我们最熟悉的是数学中的设未知数表示。例:用命题逻辑表示下列知识:
如果a 是偶数,那么a2 是偶数。
解:定义命题如下:P:a 是偶数;Q: a2 是偶数,则:原知识表示为:P→Q
谓词逻辑相当于数学中的函数表示。例:用谓词逻辑表示知识:自然数都是大于等于零的整数
解:定义谓词如下:N(x):x 是自然数;I(x):x 是整数;GZ(x):x 是大于等于零的数。所以原知识表示为:(∀x)(N(x)(GZ(x)∧I(x)),∀(x)是全称量词。
对于描述逻辑ALC的推理Tableau算法原理:利用逻辑中的转化规则不断的将原始问题展开树结构,直至能判断命题的成立为止。是一个深度优先算法,总是先扩展左分枝,在完成态存在一个无冲突分治,表示推理结论一致
知识建模
本体的概念:
在计算机科学和信息科学中,本体是知识的一种形式表示,它是一个领域内的一组概念以及这些概念之间的关系。
它用于推理该域内的实体,也可以用于描述该域。
本体是组织信息的结构框架,用于人工智能
语义Web、系统工程、软件工程、生物医学信息学、图书馆学、企业书签和作为世界或世界的一部分知识表示形式的信息架构。
中文的“苹果”,英文的“apple”和“苹果的图片”都可以让人知道是在表示苹果这样东西。那么在哲学层面,苹果这样东西就是亚里士多德口中的“实体”,巴门尼德口中的“存在”,和本体论中所说的“本体”。而“苹果”,“apple”和“苹果的图片”就统统是描述这个“本体”的符号。
本体”这个概念在哲学层面上是形而上的,是只可意会不可言传的,因为所有的描述都成为了“本体”的外在符号,我们世界上的所有图像、语言、我们看到的、听到的、感受到的,都成为符号到本体的某种映射。
既然我们都已经理解了哲学层面上所有的符号到本体存在映射,那么语义层面就很好理解了,我们的主要目的就是要建立这样一种映射,举个简单的例子,我们就是希望把
{“THU”,"Tsinghua", "Tsinghua University","清华","清华大学"}
这个符号集都映射到“清华大学”这个“本体”上来。再深一层,我们建立了本体的集合,就可以去发掘本体之间深层的关系,有可能是“属性-本体”的关系,有可能是“子类-本体”的关系,也有可能是“本体-本体”的对立或者是近似关系。描述语义层面的本体关系的语言就是RDF和OWL等。
再深一层的话,在建立好本体之间的关系之后能干什么呢?我们就可以进行语义层面上的推理了啊,推理的结果可以映射回语言层面形成新的组合。举个例子:
1.我们把各民族表示苹果的语言都映射到“苹果”这个本体上,这是第一步本体映射;
2.苹果这个“本体”可以跟“名词主体”建立隶属关系,这是第二步建立本体之间的逻辑关系;
3.“名词主体”可以跟在“动词主体”之后,形成动宾结构,我们在这个动宾结构之上,经过反映射,就可以实现各语种之间的翻译,这是逻辑推理和实际应用。
其实不仅限于语义Web,很多机器学习、自然语言处理和人工智能的方法都在做本体映射和推理,只是表现的形式不同罢了,所以也建议IT狗们能读一读“本体论”,“认识论”的书籍,说不定能有更深的认识。
https://www.zhihu.com/question/19558514
本体手动构建工程
1. 确定本体的领域和范围
2. 考虑重用现有本体
3. 列出本体中的重要术语
4. 定义类和类的继承
5. 定义类的属性和关系
6. 定义属性的限制
7. 创建实例
本体自红构建
1. 基于规则的本体学习
2. 基于机器学习的本体学习
将本体学习转化为机器学习中的分类和序列标注问题
选取特征和学习模型,进行训练,学习得到本体

知识抽取
对于开放的链接数据(通常需要爬虫等技术获取),通过自动化技术抽取出可用的知识单元,主要是下面三个方面
知识抽取基本都是建立在信息抽取的基础之上的,都普遍利用自然语言处理技术,基于规则的包装器,机器学习等。
对不同知识的知识抽取
1. 对于结构化数据的知识抽取
这个简单,一般都是直接从数据库里面直接转化抽取就可以
抽取的原理是
表-类
列-属性
行-资源/实例
单元-属性值
外键-指代(Reference)
虽然转换规则简单,但是语义信息不足
2. 对于半结构化数据的知识抽取
比如说wiki百科知识,可以先通过爬虫啥的转化成结构化数据再进一步知识抽取。
3. 对于无结构化数据的知识抽取
即通过NLP技术进行实体抽取,关系抽取和属性抽取,事件抽取。
1. 实体抽取,抽取出知识图谱中最基本的元素实体,在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。
2. 关系抽取,解决实体间语义链接
3. 属性抽取,主要是对实体的属性进行完整勾画。
4. 事件抽取,事件就是具有时间,地点,参与者等基本元素,可由某个动作触发或者状态改变而发生图结构知识片段。把事件从数据中抽取出来并结构化或者语义化展示。
实体识别
就是对于非结构化数据(txt这样的)识别出人名,地名,组织名
基于规则和词典的实体识别
基于机器学习的实体识别
目前上述的方法是一个也看不懂QAQ
基于半监督学习的实体识别
基于迁移学习的实体识别
基于预训练的实体识别
......
关系抽取
看不懂啊
事件抽取
知识融合
由于是多数据源的,不同数据源存在知识重复,知识间的关联不明确,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
知识融合的解决思路
1. 本体匹配
本体匹配流程
(1) 预处理:解析,数据清洗,构造基础数据
(2) 匹配计算,构造匹配线索,相似度计算
匹配的方法
(1) 基础匹配器
(2) 文本匹配器
(3) 结构匹配器
(4) 知识表示学习方法
原理:利用机器学习中的学习技术,将知识图谱中的实体和关系都映射成地位向量空间,直接用数学表达式来计算各个实体之间的相似度。
(3) 后处理,匹配结果抽取,匹配调谐
匹配结果抽取:不同匹配的结果通常表示为一个相似矩阵,如何从中得到最终的匹配结果通常使用稳定婚姻算法,其他启发式算法。
2. 实例匹配
看不懂了。。。
知识表示学习
基本概念
表示学习:将研究对象的语义信息表示为稠密低纬的实值向量
研究对象:文字,图片,语音等
将知识库的实体和关系表示为稠密低纬的实值向量
以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。
简单说就是让把知识变成机器可以理解的东西
知识表示中的问题
基于图结构的知识表示虽然简洁直观,但是需要专门的算法(复杂度高,可扩展性差)
数据稀疏问题
长尾分布,长尾上的实体和关系的语义难以捕获。
独热表示(one-hot representation)
假设所有研究对象都是独立的,将研究对象表示为向量,只有某一维非零,其余维度上的值均为0。显然不符合实际情况,导致丢失大量信息。
例子:苹果(0,1,0,0,0,0,0),香蕉(0,0,0,1,0,0,0)
知识表示的意义
低维向量提高计算效率
稠密向量缓解数据稀疏
多源的异质信息表示形式统一,便于迁移和融合
知识表示学习代表模型
基于距离的模型
基于翻译的模型
语义匹配模型
融合多源信息的模型
知识推理
大部分的知识图谱都是半自动的方式构建,知识推理就是利用现有的显性知识来预测知识图谱的隐性知识