最近学习的数据库自动定时备份的方法,从网上看的很多资料,大部分文章都是用的脚本之家的那个模板(原代码地址:https://www.jb51.net/article/99938.htm),但是都没有很详细的解释,作为小白自己弄懂如何实现还是要花一点功夫,所以记录一下自己的学习过程。本文大部分内容都是从多篇文章中把有用的知识点复制过来整合而成的。
在数据库的日常维护工作中,除了保证业务的正常运行以外,就是要对数据库进行备份,以免造成数据库的丢失,从而给企业带来重大经济损失。
通常备份可以按照备份时数据库状态分为热备和冷备,按照备份数据库文件的大小分为增量备份、差异备份和全量备份。
完整备份:每次都将所有数据(不管自第一次备份以来有没有修改过),进行一次完整的复制,备份后会清除文件的存档属性(存档属性可以理解为对文件修改并保存以后做的标记),方便日后增量备份或者差异备份进行版本比较。
特点:占用空间大,备份速度慢,但恢复时一次恢复到位,恢复速度快。
增量备份:在第一次完整备份之后,第二次开始每次都将添加了存档属性的文件进行备份,并且在备份之后再把这些存档属性清除。为什么要清除存档属性呢?这就是为了下一次备份的时候判断是否有文件变化,因为用户在每次备份以后修改这些被清除存档属性的文件,存档属性就会自动加上,相当于用户告诉系统,这些文件有变化,你下一次就备份这些文件,其他没有存档属性的就不需要备份,这就是增量备份的工作机制。
(相当于机器人把地板打扫干净了,你踩过,就会有脚印(增加标记),下次机器人就把脚印记录下来,并且把脚印打扫干净(清除标记),始终保持地板干净。机器人每次记录并打扫的脚印就相当于每次增量备份的内容)
特点:因每次仅备份自上一次备份(注意是上一次,不是第一次)以来有变化的文件,所 以备份体积小,备份速度快,但是恢复的时候,需要按备份时间顺序,逐个备份版本进行恢复,恢复时间长。
差异备份:在第一次完整备份之后,第二次开始每次都将所有文件与第一次完整备份的文件做比较,把自第一次完整备份以来所有修改过的文件进行备份,且以后每次备份都是和第一次完整备份进行比较(注意是第一次,不是上一次),备份自第一次完整备份以来所有的修改过的文件。因此,差异备份在备份完毕之后不需要清除文件的存档属性,因为这些文件和下一次备份没有什么关系,它仅仅和第一次完整备份的数据进行比较(第一次完整备份之后是清除存档属性的)。
(相当于第一次机器人把地板打扫干净了,你踩过,就会有脚印,机器人就把脚印记录下来,但不打扫,下次你又有踩脏的,机器人就把你这几次所有踩脏的地方都记录下来,始终不打扫,每次都这样。机器人每次记录的内容就相当于差异备份的内容)
特点:占用空间比增量备份大,比完整备份小,恢复时仅需要恢复第一个完整版本和最后一次的差异版本,恢复速度介于完整备份和增量备份之间。
简单的讲,完整备份就是不管三七二十一,每次都把指定的备份目录完整的复制一遍,不管目录下的文件有没有变化;增量备份就是每次将之前(第一次、第二次、直到前一次)做过备份之后有变化的文件进行备份;差异备份就是每次都将第一次完整备份以来有变化的文件进行备份。
所以一般数据库备份时间会选择在访问量很小的半夜,一星期完全备份一次,每天增量备份一次。这样既不会损耗太大的服务器性能,又可以确保数据安全,通过脚本定时执行的方法来完成夜间自动备份。
做这个之前需要开通vi /etc/my.conf 中添加log-bin日志
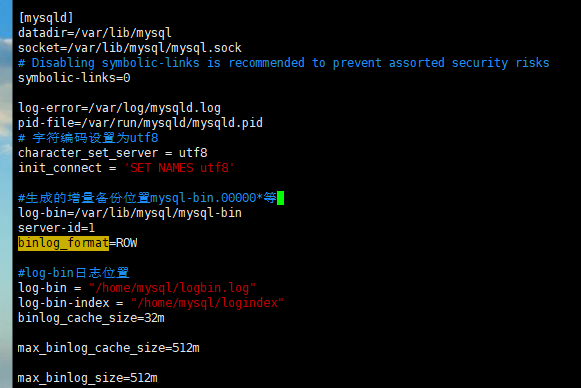
1.首先要在/home/mysql/目录下建立以下目录:
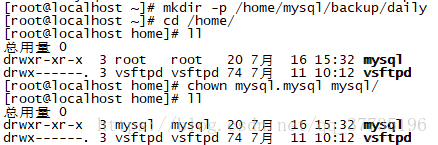
mkdir -p /home/mysql/backup/daily
2.然后把路径 /home/mysql的用户和组改成mysql,代码如下:
3.然后在/etc/my.cnf文件中加入以下代码:
log-bin = "/home/mysql/logbin.log" binlog-format = ROW log-bin-index = "/home/mysql/logindex" binlog_cache_size=32m max_binlog_cache_size=512m max_binlog_size=512m server-id=1
4.再使用service mysqld restart命令重启mysql(server-id=1在原教程中没有,但是不添加的话会出现这个错

)
5.接下来就可以写脚本了,先是增量备份的代码,
cd /home/mysql
vi binlogbak.sh
6.然后写入以下代码(要改的地方就是:mysqladmin -uroot -proot123 flush-logs;
-u+链接数据库的用户 -p+密码 ):
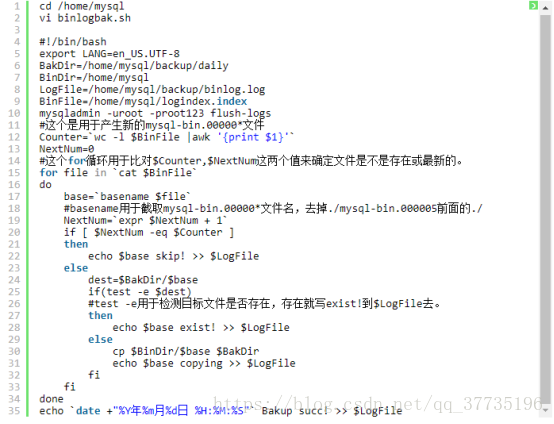
#!/bin/bash export LANG=en_US.UTF-8 BakDir=/home/mysql/backup/daily BinDir=/home/mysql LogFile=/home/mysql/backup/binlog.log BinFile=/home/mysql/logindex.index mysqladmin -uroot -proot123 flush-logs #这个是用于产生新的mysql-bin.00000*文件 Counter=`wc -l $BinFile |awk '{print $1}'` NextNum=0 #这个for循环用于比对$Counter,$NextNum这两个值来确定文件是不是存在或最新的。 for file in `cat $BinFile` do base=`basename $file` #basename用于截取mysql-bin.00000*文件名,去掉./mysql-bin.000005前面的./ NextNum=`expr $NextNum + 1` if [ $NextNum -eq $Counter ] then echo $base skip! >> $LogFile else dest=$BakDir/$base if(test -e $dest) #test -e用于检测目标文件是否存在,存在就写exist!到$LogFile去。 then echo $base exist! >> $LogFile else cp $BinDir/$base $BakDir echo $base copying >> $LogFile fi fi done echo `date +"%Y年%m月%d日 %H:%M:%S"` Bakup succ! >> $LogFile
7.接下来赋予binlogbak.sh执行权限:
chmod a+x /home/mysql/binlogbak.sh
8.再写全量备份的代码:
vi databak.sh
9.加入以下代码(要改的地方就是:mysqldump -uroot -proot123 --all-databases --flush-logs --delete-master-logs --single-transaction > $DumpFile;
-u+链接数据库的用户 -p+密码; --all-databases这句是指定完全备份哪个数据库,基本语法:

):
#!/bin/bash export LANG=en_US.UTF-8 BakDir=/home/mysql/backup LogFile=/home/mysql/backup/bak.log Date=`date +%Y%m%d` Begin=`date +"%Y年%m月%d日 %H:%M:%S"` cd $BakDir DumpFile=$Date.sql GZDumpFile=$Date.sql.tgz mysqldump -uroot -proot123 --all-databases --flush-logs --delete-master-logs --single-transaction > $DumpFile tar -czvf $GZDumpFile $DumpFile rm $DumpFile count=$(ls -l *.tgz |wc -l) if [ $count -ge 5 ] then file=$(ls -l *.tgz |awk '{print $9}'|awk 'NR==1') rm -f $file fi #只保留过去四周的数据库内容 Last=`date +"%Y年%m月%d日 %H:%M:%S"` echo 开始:$Begin 结束:$Last $GZDumpFile succ >> $LogFile cd $BakDir/daily rm -f *
10.赋予databak.sh 执行权限:
chmod a+x /home/mysql/databak.sh
11.开启定时任务
vi /etc/crontab
12.添加以下内容:
#每个星期日凌晨3:00执行完全备份脚本
0 3 * * 0 /home/mysql/databak.sh >/dev/null 2>&1
#周一到周六凌晨3:00做增量备份
0 3 * * 1-6 /home/mysql/binlogbak.sh >/dev/null 2>&1
(注:
crontab文件概要:
用户所建立的crontab文件中,每一行都代表一项任务,每行的每个字段代表一项设置,它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的命令段,格式如下:
minute hour day month week command
分 时 日 月 周 命令
其中:
minute: 表示分钟,可以是从0到59之间的任何整数。(每分钟可用*或者*/1表示)
hour:表示小时,可以是从0到23之间的任何整数。(0表示0点)
day:表示日期,可以是从1到31之间的任何整数。
month:表示月份,可以是从1到12之间的任何整数。
week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
在以上各个字段中,还可以使用以下特殊字符:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次

crontab 定时执行的日志记录在/var/spool/mail/root中,可用以下代码查看日志记录
vi /var/spool/mail/root
)
13.使上述定时任务生效
crontab /etc/crontab
14.查看定时任务
crontab -l
到此就完成了Mysql数据库的定时自动全备份和增量备份的功能了。下面记录一下运行的过程。
先说这两个脚本语言运行之前什么样,运行以后产生了什么结果(以下的Windows系统的mysql文件夹截图都是为了方便说明,我从linux上拷下来的)。
还没有运行之前,只是完成对上面的配置文件的修改以及创建目录,就只有logbin.000001。logbin.00000*的文件是在前面设置/etc/my.cnf时写了路径指到这里的,每当mysql有更新操作(删除、插入、修改)时,mysql都会自动把这些操作记录下来存到这个logbin.00000*文件里。

然后手动运行一遍增量备份。

Mysql文件夹下就变成这样:
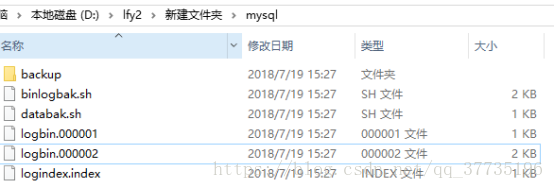

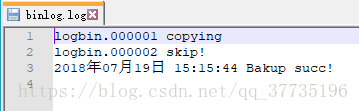

这时就产生了一个logbin.000002文件,logindex.index里面也添加了一条记录,binlog.log里面也有了记录,daily文件夹下把logbin.000001做了备份。
然后此时对数据库随便进行一个插入操作,你会发现mysql文件夹下的000001文件不再刷新修改日期了,而000002文件会同步刷新,这说明mysql会把数据库“增删改”操作记录到最新的一个00000*文件里,之前的就留着不动了。所以脚本程序做了一个将000001复制一份存到了daily里面的操作,就是000001,也就是第一天的增量备份。
然后再运行一遍增量备份
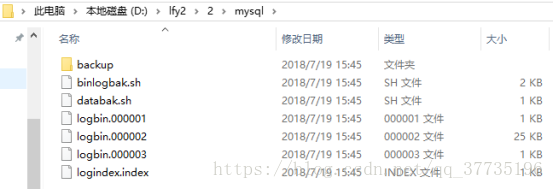
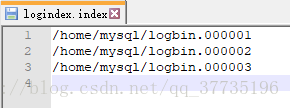

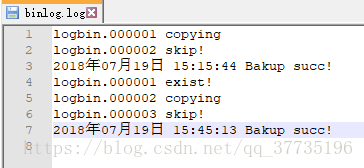
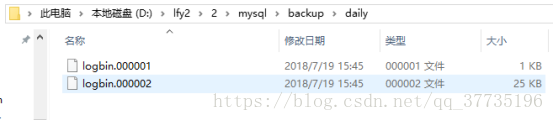
会出现一个000003文件,此时再对数据库进行修改,000001、000002都不会更改了。logindex里也多了一个000003的记录,binlog.log记录了000001已存在,000002复制,000003跳过。
daily里已经将000002也保存了一份,这是第二天的增量备份。
然后手动执行完全备份

mysql文件夹下变成了这样:

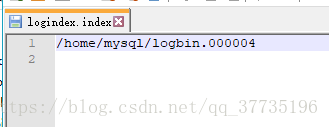
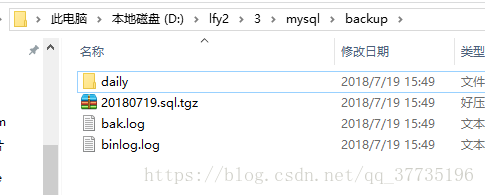

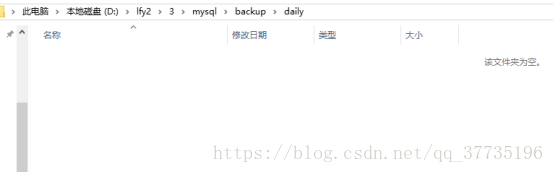

可以发现mysql和daily文件夹下000001、000002、000003都删掉了。mysql文件下留下了一个000004。index里只记录了000004,binlog.log没有变化,出现了一个bak.log记录了这次完全备份,还有一个jar包。
这就是整个过程的变化,下面就容易理解shell脚本语言执行的具体细节了,先把原代码贴上:
关于shell一些常见简单命令可以参考这里:
https://www.cnblogs.com/handongyu/p/7152028.html
第4行:符号#!用来告诉系统它后面的参数是用来执行该文件的程序。在这个例子中我们使用/bin/bash来执行程序。 Linux中有好多种不同的shell,但是通常我们使用bash (bourne again shell) 进行shell编程,因为bash是免费的并且很容易使用。
第6~9行:都是赋值语句,把创建的目录结构赋给定义的这些变量,后面可以通过$来取这些变量的值。
第10行:这一句就是产生新的00000*文件的句子,在mysql中flush logs操作会生成一个新的binlog文件。参考https://blog.csdn.net/imzoer/article/details/8277797

第12行:这一行的目的就是统计logindex.index这个文件夹里有多少个文件。
第15~17行:for循环,cat $binfile就是logindex.index里的全部文件,这里就是要把logindex.index里的每一个文件的名字赋给base;
第20~34行:判断if(NextNum == Counter);就是如果NextNum 等于了logindex.index里的文件数量,那就输出:logbin.00000* skip 到binlog.log里。不相等就查看当前base代表的文件在/home/mysql/backup/daily里面是否已有备份,如果有就写logbin.00000* exist!到binlog.log里,如果还没有那就复制一份到/home/mysql/backup/daily里。
第35行:写日期时间 Bakup succ! 到binlog.log里。
然后是完全备份:

第7行:当前的年月日。
第8行:开始备份之前的年月日、时、分、秒。
第9~11行:切换到/home/mysql/backup目录下,将日期.sql这个sql文件赋给DumpFile,将日期.sql.tgz这个压缩文件赋给GZDumpFile。
第12行:将所有数据库备份到DumpFile指向的sql文件。重新生成一个logbin.00000*。并且将之前的删除,单事务。

第13~14行:将DumpFile指向的文件压缩到GZDumpFile指向的压缩文件中,并且删掉DumpFile指向的文件。
第16~22行:就是压缩文件大于等于5个时就删掉最早的一个。
第24行:结束备份之后的年月日、时、分、秒。
第25行:将开始时间,结束时间,压缩的文件名备份成功记录到bak.log中。
第26~27行:删掉daily里面所有的文件。
到此处备份就全部结束了。相信结合代码、加运行的截图过程以及最开始对增量备份、全量备份的描述不难理解了。
备份恢复:
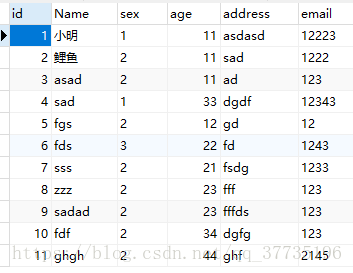
首先是完整备份以后有test这么一个数据库,tb_emp表数据如下:

然后,插入第10条和11条:
数据有“增删改”操作,增量备份会将操作记录在在logbin.00000*中,然后删掉test数据库。
此时先查看logbin.00000*中的记录,登录数据库用如下命令查看:
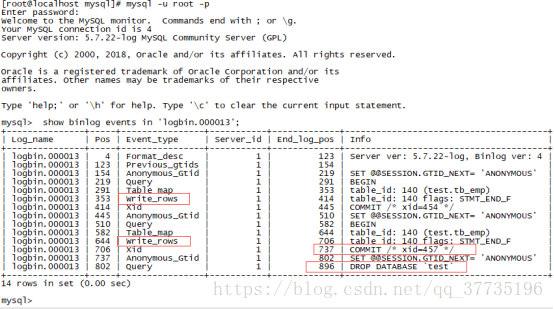
可以看到介于802~896 POS点区间的操作就是删除掉test数据库的操作,前面两条是插入记录,我们要恢复到最后一条插入数据的状态,有多种方法恢复,可以按时间,按日志区间(POS点)恢复,具体的可以参考这篇文章,讲得很详细https://blog.csdn.net/zxssoft/article/details/80115018
因为备份恢复的时候,mysql也会将恢复时的记录写入logbin.000000*,不方便找我们需要的日志,所以先把这个日志记录截屏保存下来,方便后面使用,或者直接在这个时候把mysql的日志记录功能关闭,不记录恢复时的日志
vi /etc/my.cnf
将后面的添加的部分注释掉
#log-bin = "/home/mysql/logbin.log" #binlog-format = ROW #log-bin-index = "/home/mysql/logindex" #binlog_cache_size=32m #max_binlog_cache_size=512m #max_binlog_size=512m #server-id=1
再保存退出,重启mysql服务:
service mysqld restart
此时就可以开始恢复了。先恢复最近一次的完整备份,切换到mysql目录下,解压完整备份:
cd /home/mysql/backup/
tar zxvf /home/mysql/backup/20180726.sql.tgz -C /home/mysql/backup
解压得到一个sql文件,输入以下命令然后要求输入数据库密码:
mysql -uroot -p -v < 20180726.sql
刷新数据库会发现test数据库又回来了,但是还没有后面插入的那两条数据。接下来就要恢复增量备份,结合上面的日志记录,要恢复到最后一条记录插入并且提交的时候,可以用737这个POS点作为结束点,命令如下:
/usr/bin/mysqlbinlog --stop-position=737 --database=test /home/mysql/logbin.000013 | /usr/bin/mysql -uroot -pmysql123 -v test
刷新数据库就会发现,数据已经和删除之前一模一样了。注意:这里如果使用的是706的话,第11条数据是没有恢复的。应该是提交以后才算是确认插入这条数据。
其实这个增量备份的恢复。就是把这些“增删改”操作重新运行一遍,所以如果有多天的增量备份。则需要在恢复最后一次完整的备份之后,按时间顺序,依次恢复每一个增量备份的操作,才能得到删除前的完整数据库。