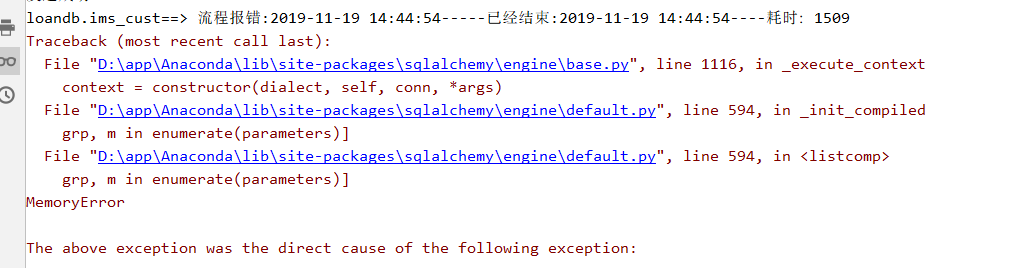
pandas中read_xxx的块读取功能
pandas设计时应该是早就考虑到了这些可能存在的问题,所以在read功能中设计了块读取的功能,也就是不会一次性把所有的数据都放到内存中来,而是分块读到内存中,最后再将块合并到一起,形成一个完整的DataFrame。
def read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None):

1.chunksize是在一个每一个chunk块中有多少行。
2.当chunksize是非None的时候read_xxx返回的是一个迭代器
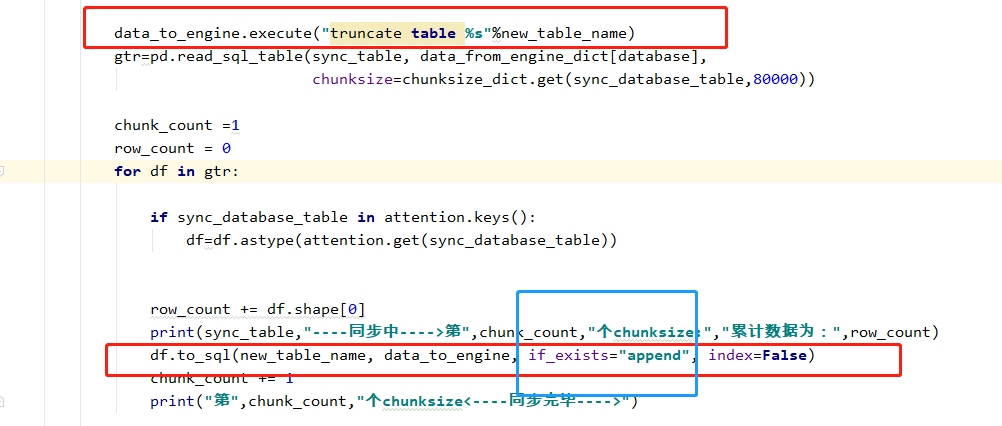
比如我自己的写的一个全量同步数据的代码如下:
gtr=pd.read_sql_table(sync_table, data_from_engine_dict[database],chunksize=20000) count=0 for df in gtr: if count==0: df.to_sql(database+"_"+sync_table, data_to_engine, if_exists="replace", index=False) else: df.to_sql(database + "_" + sync_table, data_to_engine, if_exists="append", index=False) count+=1
发现数据库中的表会被修改,我今天做了如下升级:
其他的read_xxx也有类似的参数
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)[source]
我们再介绍一个不用改的参数:
low_memory : bool, default True
Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
To ensure no mixed types either set False, or specify the type with the dtype parameter.
Note that the entire file is read into a single DataFrame regardless, use the chunksize or iterator parameter to return the data in chunks.
(Only valid with C parser).
low_memory 默认就是True,如果不小心改成了False,chunksize参数不生效。