在HQL中我经常使用开窗函数,后来做mysql(5.7)的数据处理,只能使用order等分组方式替代开窗函数。
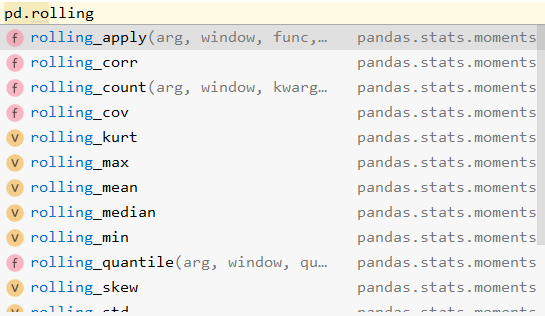
而pandas中带有各种移动窗口,它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能。
总共有3+1类。
主要有如下类:

还有pandas.rolling_xx方法
第一类 DataFrame的rolling
df.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
参数详解
window : int, or offset Size of the moving window. This is the number of observations used for calculating the statistic. Each window will be a fixed size. If its an offset then this will be the time period of each window. Each window will be a variable sized based on the observations included in the time-period. This is only valid for datetimelike indexes. This is new in 0.19.0 表示时间窗的大小,注意有两种形式(int or offset)。如果使用int,则数值表示计算统计量的观测值的数量即向前几个数据。如果是offset类型,表示时间窗的大小。pandas offset相关可以参考这里。 min_periods : int, default None Minimum number of observations in window required to have a value (otherwise result is NA). For a window that is specified by an offset, this will default to 1. 最少需要有值的观测点的数量,对于int类型,默认与window相等。对于offset类型,默认为1。
也开始这样理解:取窗口内非空的。超过这个限制就是带上空值计算 freq : string or DateOffset object, optional (default None) .. deprecated:: 0.18.0 Frequency to conform the data to before computing the statistic. Specified as a frequency string or DateOffset object. center : boolean, default False Set the labels at the center of the window. 是否使用window的中间值作为label,默认为false。只能在window是int时使用 win_type : string, default None Provide a window type. See the notes below. 窗口类型,默认为None一般不特殊指定,了解支持的其他窗口类型,参考这里。 on : string, optional For a DataFrame, column on which to calculate the rolling window, rather than the index 对于DataFrame如果不使用index(索引)作为rolling的列,那么用on来指定使用哪列。 closed : string, default None Make the interval closed on the 'right', 'left', 'both' or 'neither' endpoints. For offset-based windows, it defaults to 'right'. For fixed windows, defaults to 'both'. Remaining cases not implemented for fixed windows. 定义区间的开闭,曾经支持int类型的window,新版本已经不支持了。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left both等。 axis : int or string, default 0 方向(轴),一般都是0。
案例
案例一
min_periods参数
df = pd.DataFrame({'A': [0, 1, 2, np.nan, 3]})
df
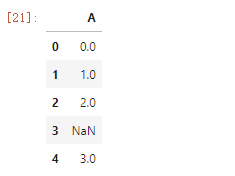
df.rolling(3).sum() df.rolling(3, min_periods=1).sum() df.rolling(3, min_periods=2).sum() df.rolling(3, min_periods=3).sum()
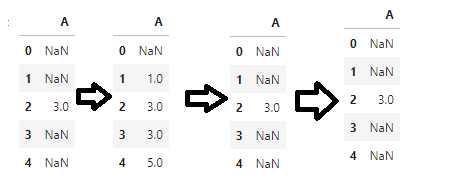
df.rolling(3, min_periods=1).sum() #m默认center=True df.rolling(3, min_periods=1,center=True).sum()
center参数
df.rolling(3, min_periods=1).sum() #m默认center=True df.rolling(3, min_periods=1,center=True).sum()
第二类pandas.core.groupby.rolling

案例
import pandas as pd # A地有两个仓库,都运往B。 df = pd.DataFrame({'1': ['A1', 'A2', 'A1', 'A2', 'A2', 'A1', 'A2'], '2': ['B1', 'B1', 'B1', 'B1', 'B1', 'B1', 'B1'], 'num': [1,2,1,3,4,2,1]}, index = [pd.Timestamp('20200101 09:00:00'), pd.Timestamp('20200101 09:00:01'), pd.Timestamp('20200101 09:00:02'), pd.Timestamp('20200101 09:00:03'), pd.Timestamp('20200101 09:00:04'), pd.Timestamp('20200101 09:00:05'), pd.Timestamp('20200101 09:00:06')]) df
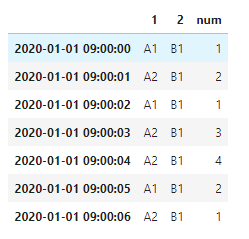
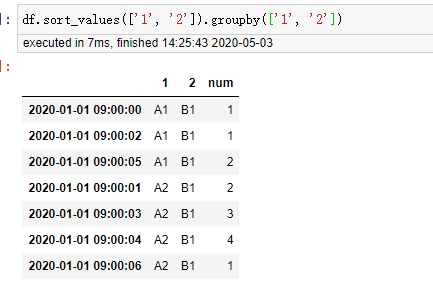
# 以9:00:04秒为例,由于时间窗是3s,默认的closed是right,所以我们相加04,03,02秒的num,共有4+3+0=7 df.groupby(['1', '2'])['num'].rolling('3s').sum()
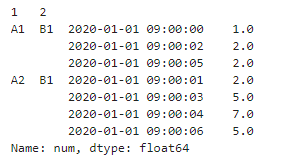
第三类略
不常用