如何更好地并发编程
简介
python不仅内置了multiprocess模块,而且还内置了asyncio和concurrent模块。除了要分析这两个内置的,其实我们还要再下面另一个第三方joblib包。
我们经常喜欢单机处理数据,或者数据量一大就采用分布式的方式,其实并发编程是一个很好的选择。
- asyncio
- concurrent
- joblib
但是第一件事我们要知道采用进程的最终目的是什么?一般都是达到异步IO。那么异步IO是什么?
异步IO
异步IO是个好东西,在网络读写场景中可以大大提高程序的并发能力,比如爬虫、web服务等。这样的好东西自然也要在Python中可以使用。不过,在漫长的Python2时代,官方并没有推出一个自己的异步IO库,到了Python 3.4 才推出。
我们先从各种IO模型中去理解异步IO,那么IO可以分为几类呢?同步IO、异步IO、阻塞IO、非阻塞IO
- 同步是指代码调IO操作时,必须等待IO操作完成才返回的调用方式。
- 异步是指代码调用IO操作时,不必等IO操作完成就返回的调用方式。
- 阻塞是指调用函数时候当前线程被挂起。
- 阻塞是指调用函数时候当前线程不会被挂起,而是立即返回。
IO模型
- 阻塞IO模型
使用recv的默认参数一直等数据直到拷贝到用户空间,这段时间内进程始终阻塞。A同学用杯子装水,打开水龙头装满水然后离开。这一过程就可以看成是使用了阻塞IO模型,因为如果水龙头没有水,他也要等到有水并装满杯子才能离开去做别的事情。很显然,这种IO模型是同步的。
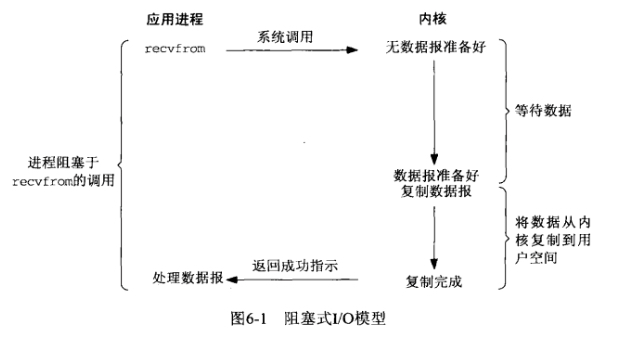
- 非阻塞IO模型
改变flags,让recv不管有没有获取到数据都返回,如果没有数据那么一段时间后再调用recv看看,如此循环。B同学也用杯子装水,打开水龙头后发现没有水,它离开了,过一会他又拿着杯子来看看……在中间离开的这些时间里,B同学离开了装水现场(回到用户进程空间),可以做他自己的事情。这就是非阻塞IO模型。但是它只有是检查无数据的时候是非阻塞的,在数据到达的时候依然要等待复制数据到用户空间(等着水将水杯装满),因此它还是同步IO。
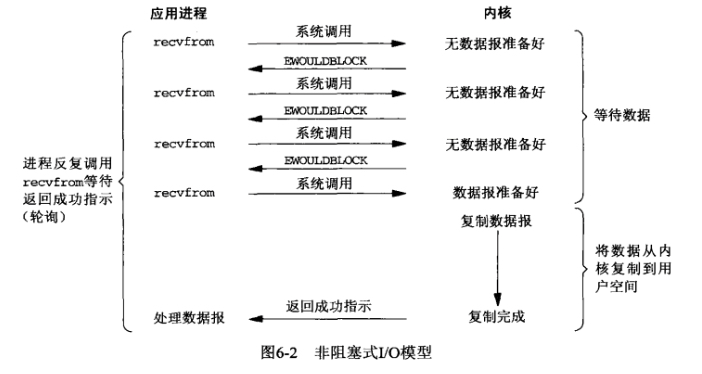
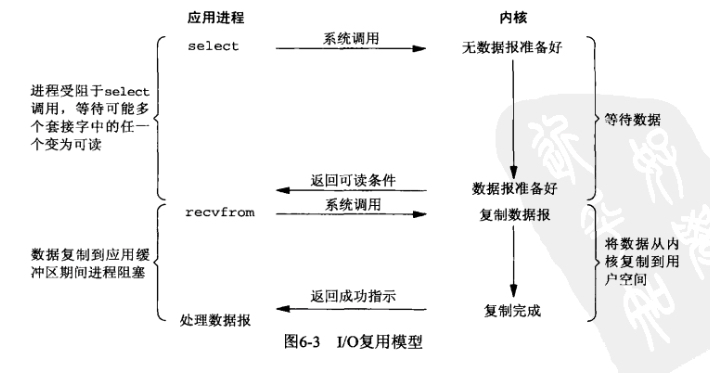
- IO复用模型
这里在调用recv前先调用select或者poll,这2个系统调用都可以在内核准备好数据(网络数据到达内核)时告知用户进程,这个时候再调用recv一定是有数据的。因此这一过程中它是阻塞于select或poll,而没有阻塞于recv,有人将非阻塞IO定义成在读写操作时没有阻塞于系统调用的IO操作(不包括数据从内核复制到用户空间时的阻塞,因为这相对于网络IO来说确实很短暂),如果按这样理解,这种IO模型也能称之为非阻塞IO模型,但是按POSIX来看,它也是同步IO,那么也和楼上一样称之为同步非阻塞IO吧。
这种IO模型比较特别,分个段。因为它能同时监听多个文件描述符(fd)。这个时候C同学来装水,发现有一排水龙头,舍管阿姨告诉他这些水龙头都还没有水,等有水了告诉他。于是等啊等(select调用中),过了一会阿姨告诉他有水了,但不知道是哪个水龙头有水,自己看吧。于是C同学一个个打开,往杯子里装水(recv)。这里再顺便说说鼎鼎大名的epoll(高性能的代名词啊),epoll也属于IO复用模型,主要区别在于舍管阿姨会告诉C同学哪几个水龙头有水了,不需要一个个打开看(当然还有其它区别)。
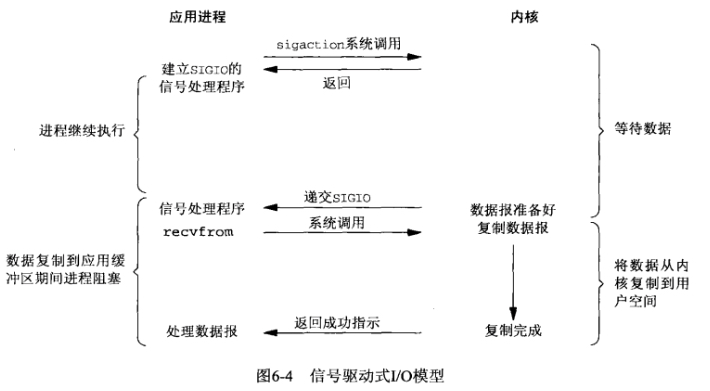
- 信号驱动IO模型
通过调用sigaction注册信号函数,等内核数据准备好的时候系统中断当前程序,执行信号函数(在这里面调用recv)。D同学让舍管阿姨等有水的时候通知他(注册信号函数),没多久D同学得知有水了,跑去装水。是不是很像异步IO?
很遗憾,它还是同步IO(省不了装水的时间啊)。
- 异步IO模型
调用aio_read,让内核等数据准备好,并且复制到用户进程空间后执行事先指定好的函数。E同学让舍管阿姨将杯子装满水后通知他。整个过程E同学都可以做别的事情(没有recv),这才是真正的异步IO。
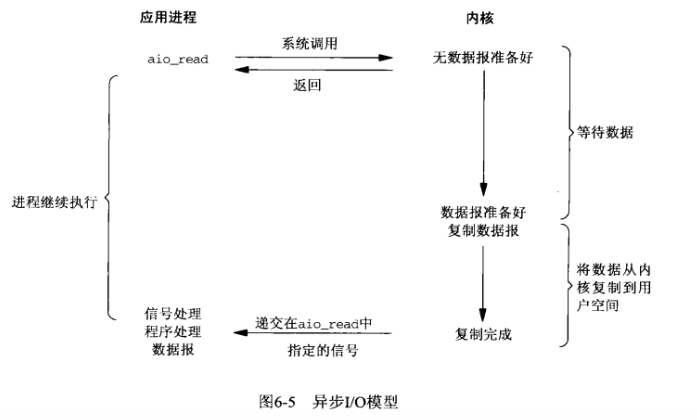
- 总结
一般来讲:阻塞IO模型、非阻塞IO模型、IO复用模型(select/poll/epoll)、信号驱动IO模型都属于同步IO,因为阶段2是阻塞的(尽管时间很短)。只有异步IO模型是符合POSIX异步IO操作含义的,不管在阶段1还是阶段2都可以干别的事。
- IO的拓展
其实整个IO过程再加上生成者就可以组建成生产消费模型。
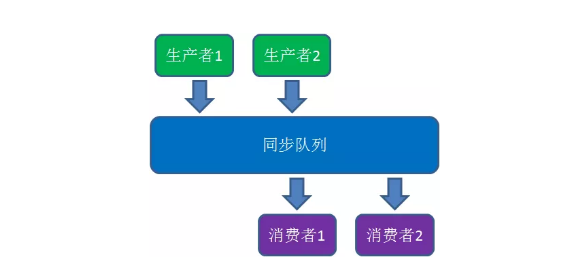
那我们在看看进程与线程在操作系统中所处的地位:
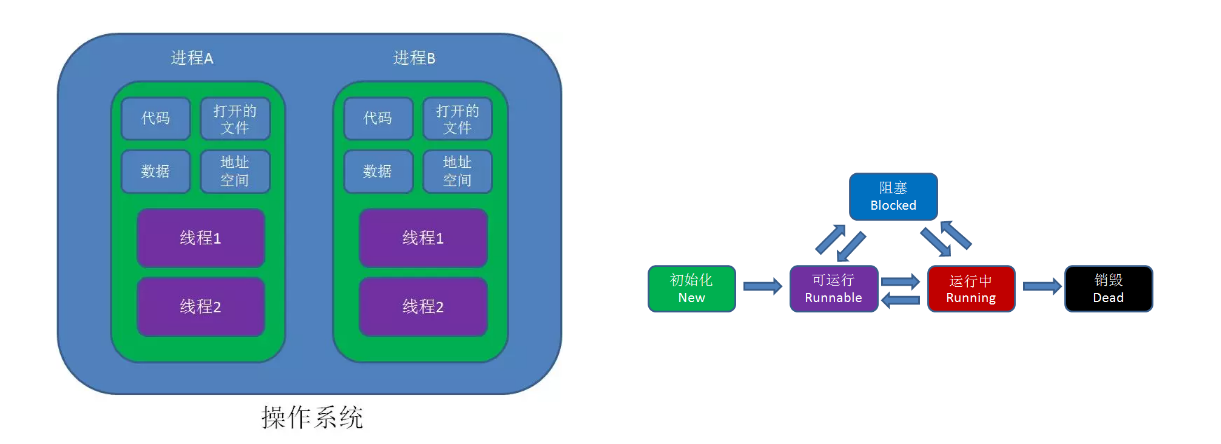
那么为什么我们还要引入另一种更细小的程序(操作程序)的单位?
我们先看在定义生产与消费模型中,我们必须要做些什么
- 定义了生产者与消费者。
- 生产者生产数据,向同步队列当中插入数据。
- 消费者循环监听同步队列,当队列有数据时拉取数据。
- 如果队列满了(达到n个元素),生产者阻塞。
- 如果队列空了,消费者阻塞。
上面的方法正确地实现了生产者/消费者模式,但是却并不是一个高性能的实现。
为什么性能不高呢?因为我们不可避免涉及了如下操作:
- 涉及到同步锁。
- 涉及到线程阻塞状态和可运行状态之间的切换。
- 涉及到线程上下文的切换。
同时因为GIL锁的存在,python是无法做到几个线程在一个CPU单核中“异步“并发。
所以往往python高并编程中,协程是不可缺少的存在,那我们就不得不学习一下协程。
了解协程
协程,英文Coroutines、又称微线程,纤程,是一种比线程更加轻量级的存在。
正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程,所以可以实现单线程下的并发,
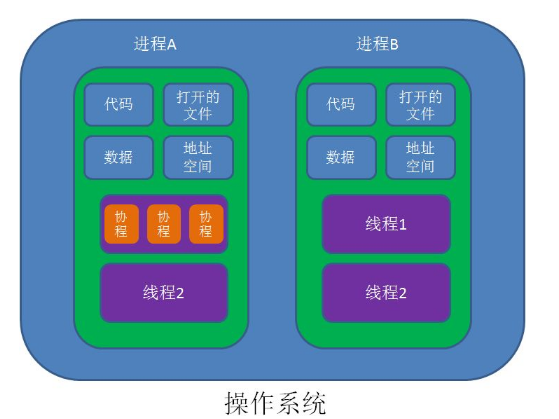
特点如下:
1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
python中异步IO发展史
Python 2 时代
官方并没有异步IO的支持,但是有几个第三方库通过事件或事件循环(Event Loop)实现了异步IO,它们是:
- twisted: 是事件驱动的网络库
- gevent: greenlet + libevent(后来是libev或libuv)。通过协程(greenlet)和事件循环库(libev,libuv)实现的gevent使用很广泛。
- tornado: 支持异步IO的web框架。自己实现了IOLOOP。
Python 3时代
异步io的好处在于避免的线程的开销和切换,而且我们都知道python其实是没有多线程的,只是通过底层线层锁实现的多线程。另一个好处在于避免io操作(包含网络传输)的堵塞时间。
Python 3.4 加入了asyncio 库,使得Python有了支持异步IO的官方库。这个库,底层是事件循环(EventLoop),上层是协程和任务。
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。