typora-copy-images-to: upload
Python学习笔记 第十一章 操作系统
1.操作系统发展史
- 手工处理-卡片穿孔
- 用户独占全机,不回出现因资源已被其他用户占用而等待的现象,资源利用率低
- cpu等待手工操作,cpu利用不充分
- 批处理-磁带存储和批处理系统:加载在计算机上的一个系统软件,计算机能自动地成批的处理一个用户或多个用户的作业
- 多道程序系统:程序遇到IO就把cpu让给别人
- 程序
- 顺序的一个一个执行的思路变成
- 共同存在一台计算机中,其中一个程序和另一个程序轮流使用cpu,来提高cpu的效率
- 单纯切换也会占用一定的时间,因为需要复原切换前的状态
- 但是多道批操作系统的原理整体上还是节省了时间,提高了cpu的效率
- 出现时空复用的概念:在同一个时间点上,多个程序同时执行着,一块内存条上存储了
- 程序
- 分时系统:把时间分成很小很小的段,每一个时间都是一个时间片
- 每个程序轮流执行一个时间片的时间,自己的时间片到了就轮到下一个程序执行--时间片的轮转
- 没有提高cpu的利用率
- 提高了用户体验
- 实时系统
- 实时控制系统,当用于飞机飞行、导弹发射的自动控制,要求计算机尽快处理
- 实时信息处理系统,预定机票,或者银行系统、情报检索,要求及时予以回答
- 主要特点:
- 及时响应,必须在严格的时间限制内完成
- 高可靠性,采取冗余措施,双机系统前后台工作,也包括必要的保密措施
- 通用操作系统:具有多种类型操作特征的操作系统
I/O操作 是相对于内存来说的
计算机的工作分为两个状态:
- CPU工作:做计算(对内存中的数据进行操作)的时候工作
- CPU不工作:IO操作的时候
CPU的工作效率:5亿条指令/s = 50万条指令/ms
单核-1个cpu
- 先来先服务
- 短作业优先
- 分时操作系统:把时间分成很小的多
1.1操作系统的进一步发展
进入20世纪80年代,大规模集成电路工艺技术的飞跃发展,微处理机的出现和发展,掀起了计算机大发展大普及的浪潮。一方面迎来了个人计算机的时代,同时又向计算机网络、分布式处理、巨型计算机和智能化方向发展。于是,操作系统有了进一步的发展,如:个人计算机操作系统、网络操作系统、分布式操作系统等。
1.2个人计算机操作系统
个人计算机上的操作系统是联机交互的单用户操作系统,它提供的联机交互功能与通用分时系统提供的功能很相似。
由于是个人专用,因此一些功能会简单得多。然而,由于个人计算机的应用普及,对于提供更方便友好的用户接口和丰富功能的文件系统的要求会愈来愈迫切。
1.3网络操作系统
计算机网络:通过通信设施,将地理上分散的、具有自治功能的多个计算机系统互连起来,实现信息交换、资源共享、互操作和协作处理的系统。
网络操作系统:在原来各自计算机操作系统上,按照网络体系结构的各个协议标准增加网络管理模块,其中包括:通信、资源共享、系统安全和各种网络应用服务。
1.4分布式操作系统
把一个问题分解成小问题,把小任务发送到多台机器上计算,计算完再返回结果
表面上看,分布式系统与计算机网络系统没有多大区别。分布式操作系统也是通过通信网络,将地理上分散的具有自治功能的数据处理系统或计算机系统互连起来,实现信息交换和资源共享,协作完成任务。——硬件连接相同。
但有如下一些明显的区别:
(1)分布式系统要求一个统一的操作系统,实现系统操作的统一性。
(2)分布式操作系统管理分布式系统中的所有资源,它负责全系统的资源分配和调度、任务划分、信息传输和控制协调工作,并为用户提供一个统一的界面。
(3)用户通过这一界面,实现所需要的操作和使用系统资源,至于操作定在哪一台计算机上执行,或使用哪台计算机的资源,则是操作系统完成的,用户不必知道,此谓:系统的透明性。
(4)分布式系统更强调分布式计算和处理,因此对于多机合作和系统重构、坚强性和容错能力有更高的要求,希望系统有:更短的响应时间、高吞吐量和高可靠性。
分布式
- 操作系统
- 程序 、 插件
- celery python分布式框架
2.操作系统的作用
现代的计算机系统主要是由一个或者多个处理器,主存,硬盘,键盘,鼠标,显示器,打印机,网络接口及其他输入输出设备组成。
一般而言,现代计算机系统是一个复杂的系统。
其一:如果每位应用程序员都必须掌握该系统所有的细节,那就不可能再编写代码了(严重影响了程序员的开发效率:全部掌握这些细节可能需要一万年....)
其二:并且管理这些部件并加以优化使用,是一件极富挑战性的工作,于是,计算安装了一层软件(系统软件),称为操作系统。它的任务就是为用户程序提供一个更好、更简单、更清晰的计算机模型,并管理刚才提到的所有设备。
总结:
程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作,这个繁琐的工作就是操作系统来干的,有了他,程序员就从这些繁琐的工作中解脱了出来,只需要考虑自己的应用软件的编写就可以了,应用软件直接使用操作系统提供的功能来间接使用硬件。
*精简的说的话,操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。操作系统所处的位置如图*
*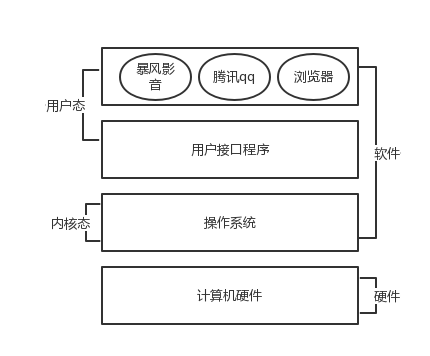 *
*
细说的话,操作系统应该分成两部分功能:
#一:隐藏了丑陋的硬件调用接口,为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。
例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节),
#二:将应用程序对硬件资源的竞态请求变得有序化
例如:很多应用软件其实是共享一套计算机硬件,比方说有可能有三个应用程序同时需要申请打印机来输出内容,那么a程序竞争到了打印机资源就打印,然后可能是b竞争到打印机资源,也可能是c,这就导致了无序,打印机可能打印一段a的内容然后又去打印c...,操作系统的一个功能就是将这种无序变得有序。
3.进程、线程、协程
进程:进行中的一个程序就是进程,占用资源,需要操作系统调用,pid:能唯一的标识一个进程,计算机中最小的资源分配单位
线程:线程是进程中的一个单位,不能脱离进程存在,是cpu进行调度的最小单位
并发:多个程序同时执行:只有一个cpu,多个程序轮流在一个cpu上运行
宏观上:多个程序在同时执行
微观上:多个程序轮流在一个cpu上执行,本质上还是串行
并行:多个程序同时执行,并且同时在多个cpu上执行
同步:在做A事的时候发起B事,必须等待B事件结束之后才能继续做A事(调用一个操作,要等待结果)
异步:在做A事的时候发起B事,不需要等待B事件结束就可以继续做A事(调用一个操作,不需要等待结果)
阻塞:如果CPU不工作,input accept recv recvfrom sleep connect
非阻塞:如果CPU工作
同步阻塞:调用一个函数需要等待这个函数的执行结果,且执行这个函数的过程中cpu不工作,input sleep recv recvfrom
同步非阻塞:调用一个函数需要等待这个函数的执行结果,但是cpu执行这个函数的过程中仍然在工作,如ret = func(1, 2) 需要等待func函数计算完(CPU一直工作)
异步非阻塞:调用一个函数不需要等待这个函数的执行结果,并且在执行这个函数的过程中cpu工作,start()
异步阻塞:调用一个函数不需要等待这个函数的执行结果,但是执行这个函数的过程cpu不工作,开启10个异步的进程,能获取这个进程的返回值,并且能够做到哪个进程先结束,就先获取谁的返回值
进程的三状态图:
- 就绪
- 运行
- 阻塞

从运行到阻塞的原因:等待I/O、申请缓冲区不能满足、等待信号
阻塞到就绪:I/O完成
进程的调度算法:
-
给所有的进程分配资源或者分配cpu使用全的一种方法(分时作业)
-
短作业优先
-
先来先服务
-
多级反馈算法
-
多个任务队列,优先级从高到低,新来的任务总是优先级最高的,每一个新任务几乎会立即获得一个时间片事件
-
执行玩一个时间片之后就会降到优先级低的队列,并且优先级越高时间片越短
-
前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。 而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。 (1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个队列的时间片要比第i个队列的时间片长一倍。 (2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。 (3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。如果处理机正在第i队列中为某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
-
进程的开启:
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4中形式创建新的进程:
1. 系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
2. 一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等)
3. 用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
4. 一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的。
进程的结束:
-
正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
-
出错退出(自愿,python a.py中a.py不存在)
-
严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
-
被其他进程杀死(非自愿,如kill -9)
Process类的一些方法和属性:
- name pid ident daemon
- terminate() is_alive()
- 守护进程:在start一个进程之前设置daemon = True 守护进程会等待主进程的代码结束后立即结束
# multiple 多元化的
# processing 进程
# import multiprocessing
from multiprocessing import Process
import os
import time
def func(name):
# 可以加入参数
print(os.getpid(), os.getppid()) # pid process id ppid parent process id
time.sleep(1)
print(name)
# 进程id 父进程id
if __name__ == '__main__': # 进程之间所有的内存是隔离的
# windows开启子进程会直接import父进程的文件,导入的时候不会执行name=main,所以也不会循环生成子进程
# 只会在主进程中执行的所有代码你写在name=main下
print('main:', os.getpid(), os.getppid()) # main: 11886 11671 作为子进程,父进程为pycharm
p = Process(target=func, args=('apple',)) # 传入参数需要以元组的形式
p.start() # 11888 11886 开启了一个子进程,作为一个父进程
p = Process(target=func, args=('banana',)) # 传入参数需要以元组的形式
p.start() # 11889 11886 开启了一个子进程,作为一个父进程
"""
#可以使用for循环
arg_lst = [('apple', ), ('banana', ), ('pen', )]
for arg in arg_lst:
p = Process(target=func, args=arg)
p.start()
"""
# 为什么换成linux或者mac不需要name=main也不回报错
# linux-fork 是直接把父进程的内存copy一份,但是内存之间是隔离开的,不需要import
# 能不能获取子进程的返回值 不能
# start()就是一个异步非阻塞,会先打印pid和ppid,后一起打印出apple 和 banana
进程的开启和关闭
- 父进程开启子进程
- 父进程要负责给子子进程 回收子进程结束之后的资源
join
import os
import time
import random
from multiprocessing import Process
def func(name, age):
print('给%s岁的%s发送一封邮件' %(name, age))
time.sleep(random.random())
# 邮件发送的时间随机
print('发送完毕')
if __name__ == '__main__':
"""
p = Process(target=func, args=('apple', '18', ))
p.start()
p.join()
p1 = Process(target=func, args=('banana', '28', ))
p1.start()
p1.join() # 同步阻塞
print('全部发送完毕')
"""
arg_lst = [('apple', '18'), ('banana', '22'), ('pen', '44')]
tmp = [] # 用来存放子进程
for arg in arg_lst: # 所有的子进程都开启了
p = Process(target=func, args=arg)
p.start() # start就是一个异步非阻塞,各个子进程之间不回相互影响
tmp.append(p)
for p in tmp: # 同步阻塞,只有每个子进程的程序完成了才会执行下面的语句
p.join()
print('全部发送完毕')
多进程之间的数据隔离
from multiprocessing import Process
n = 0
def func():
global n
n += 1
if __name__ == '__main__':
p_lst = []
for i in range(100):
p = Process(target=func)
p.start()
p_lst.append(p)
for p in p_lst:
p.join()
print(n) # 0 父进程的数据不回被改变,子进程中的n全部都是1
多进程实现并发的socketserver
server.py
import socket
from multiprocessing import Process
#创建多进程实现socketserver
def func(conn):
while True:
msg = conn.recv(1024)
print(msg)
conn.send(b'bye')
conn.close()
if __name__ == '__main__':
sk = socket.socket()
sk.bind(('127.0.0.1', 8001))
sk.listen()
while True:
conn, addr = sk.accept()
Process(target=func, args=(conn, )).start()
sk.close()
client.py
import socket
import time
sk = socket.socket()
sk.connect(('127.0.0.1', 8001))
while True:
sk.send(b'hello')
msg = sk.recv(1024)
print(msg)
time.sleep(0.5)
sk.close()
开启进程的另一种方法:
from multiprocessing import Process
import os
class MyProcess(Process):
def run(self):
print(os.getppid(), os.getpid())
if __name__ == '__main__':
print('父进程pid:%s'%(os.getpid()))
p = MyProcess()
p.start()
"""
父进程pid:14899
14899 14901
"""
传递参数:
from multiprocessing import Process
import os
class MyProcess(Process):
def __init__(self, a, b):
super().__init__() # 不使用父类的init会报AttributeError
self.a = a
self.b = b
def run(self):
print(os.getppid(), os.getpid(), self.a, self.b)
if __name__ == '__main__':
print('父进程pid:%s'%(os.getpid()))
p = MyProcess(1, 2)
p.start()
"""
父进程pid:14899
14899 14901
"""
Process类的其他方法
from multiprocessing import Process
import os
import time
class MyProcess(Process):
def __init__(self, a, b):
super().__init__() # 不使用父类的init会报AttributeError
self.a = a
self.b = b
def run(self):
print(os.getppid(), os.getpid(), self.a, self.b)
if __name__ == '__main__':
print('父进程pid:%s'%(os.getpid()))
p = MyProcess(1, 2)
p.start()
print(p.pid, p.ident) # 进程的id
print(p.name) # 进程的名字 MyProcess-1
print(p.is_alive()) # 判断进程是否活着 True
p.terminate() # 强制结束一个子进程 异步非阻塞
print(p.is_alive()) # 判断进程是否活着 True
time.sleep(0.01)
print(p.is_alive()) # 判断进程是否活着 False
4.守护进程
在start一个进程之前设置daemon = True
守护进程会等待主进程的代码结束就立即结束
为什么守护进程只守护主进程的代码?而不是等待主进程结束之后才结束?
- 因为主进程要最后结束,为了给守护进程回收资源
守护进程会等待其他子进程结束吗?不会
from multiprocessing import Process
import time
def son1():
while True:
print('in son1')
time.sleep(1)
def son2():
for i in range(10):
print('in son2')
time.sleep(1)
# 主进程会等待所有的子进程结束,是为了回收子进程的资源
if __name__ == '__main__':
p1 = Process(target=son1)
p1.daemon = True # 表示设置p1是一个守护进程
p1.start()
p2 = Process(target=son2)
p2.start()
time.sleep(3)
# p2.join() # 使得程序的执行顺序变为:p2进程结束 -》 主进程的代码结束 -》 p1进程结束 -》 主进程结束
print('in main')
# 守护进程会等待主进程的代码执行结束之后再结束,而不是等待整个主进程的结束
# 主进程的代码什么时候结束,守护进程就什么时候结束,与其他子进程无关
5.进程同步 - 锁
进程之间的数据安全问题
锁:会降低程序的运行效率,保证数据安全
抢票的例子
import json
from multiprocessing import Process, Lock
import time
"""
lock = Lock()
lock.acquire() #拿钥匙
#被锁起来的代码
lock.release() #还钥匙
#更简单的代码
with lock:
#被锁起来的代码,这段代码执行错误仍然会还钥匙
"""
def search(i):
with open('ticket', encoding='utf-8') as f:
ticket = json.load(f)
print('%s查询余票是%s'%(i, ticket['count']))
def buy_ticket(i):
with open('ticket', encoding='utf-8') as f:
ticket = json.load(f)
if ticket['count'] > 0:
ticket['count'] -= 1
print('%s买到票了'%(i))
time.sleep(0.1)
with open('ticket', mode='w', encoding='utf-8') as f:
json.dump(ticket, f)
def get_ticket(i, lock):
search(i)
with lock: # 代替acquire和release 并在此基础上做一些异常处理,保证即便一个进程出现问题,也会归还钥匙
buy_ticket(i)
if __name__ == '__main__':
# 主进程共用一把锁和一把钥匙
lock = Lock()
for i in range(10):
p = Process(target=get_ticket, args=(i, lock)).start()
互斥锁
- 不能在同一个进程中连续acquire多次
6.进程之间的通信 - 队列
进程之间的通信 Inter Process communication
-
基于文件:同一台机器上的多进程之间通信
- Queue
- 基于socket、pickle、Lock的文件级别的通信来完成数据通信的
from multiprocessing import Queue,Process def son(q): q.put('hello') if __name__ == '__main__': q = Queue() # 共享的 Process(target=son, args=(q, )).start() print(q.get())- pipe管道 基于socket、pickle实现的,没有锁数据不安全
-
基于网络:同一台机器或者多台机器上的进程之间的通信
- 第三方工具(消息中间件)
- memcache
- redis
- rabbitmq
- kafka
- 第三方工具(消息中间件)
生产者消费者模型
- 爬虫的时候
- 分布式操作:celery
- 本质:让生产数据和消费数据的效率达到平衡并且达到最大化的效率
from multiprocessing import Queue,Process
import random
import time
def consumer(q, ): # 消费者:通常取到数据之后还要进行某些操作
while True:
food = q.get()
if food:
print(food)
else:
break
def producer(q, ): # 生产者:通常在放数据之前需要通过某些代码来获取数据
for i in range(10):
time.sleep(random.random())
print(q.put(i))
if __name__ == '__main__':
q = Queue()
c1 = Process(target=consumer, args=(q, ))
p1 = Process(target=producer, args=(q, ))
p2 = Process(target=producer, args=(q, ))
c1.start()
p1.start()
p2.start()
p1.join()
p2.join()
q.put(None)
生产者消费者模型
- 把原本获取数据处理数据的完整过程进行了解耦
- 拆分的很清楚的程序(松耦合)
- 把生产数据和消费数据分开,根据生活生产和消费效率不同,来规划生产者和消费者的个数
- 让程序的执行效率达到平衡
如果你写了一个程序所有的功能和代码放在一起,不分函数不分类也不分文件(紧耦合)
异步阻塞
import requests
from multiprocessing import Process, Queue
url_lst = [
'https://www.cnblogs.com',
'https://www.baidu.com',
'https://gitee.com'
]
def producer(index, url, q):
res = requests.get(url)
q.put((index, res.status_code))
if __name__ == '__main__':
q = Queue()
for index, url in enumerate(url_lst):
Process(target=producer, args=(index, url, q)).start()
for i in range(len(url_lst)): # 异步阻塞, 并没有按照顺序等待结果,而是所有的任务都在异步执行这,但是等结果又不知道谁的结果先来
print(q.get())
"""
(1, 200)
(0, 200)
(2, 200)
"""
同步阻塞:调用函数必须等待结果,cpu没工作 input sleep recv connect get
同步非阻塞:调用函数必须等待结果,cpu工作-调用一个高计算的函数strip max sum eval('1+2+3') sorted
异步阻塞:调用函数不需要立即获取结果,而是做其他的事情,在获取结果的时候不知道先获取谁的,但是总之需要等(阻塞)
异步非阻塞:调用函数不需要立即获取结果,也不需要等start() terminate()
7.进程之间的数据共享 -Manager
存在安全隐患
from multiprocessing import Process, Manager, Lock
def change_dic(dic, lock): # 数据共享需要加锁才安全
with lock:
dic['count'] -= 1
if __name__ == '__main__':
m = Manager() #with Manager() as m : 需要统一缩进
lock = Lock()
dic = m.dict({'count':100})
p_l = []
for i in range(100):
p = Process(target=change_dic, args=(dic, lock))
p.start()
p_l.append(p)
for p in p_l: p.join()
print(dic) # {'count': 0}
8.线程
回顾进程:数据隔离,资源分配的最小单位,可以利用多核,操作系统调度
-
multiprocessing 如何开启进程 start join
-
进程有数据不安全的问题 Lock
-
进程之间可以进行通信ipc
- Queue队列(安全)pipe管道(不安全)
- 第三方工具:
-
进程之间可以通过Manager类实现数据共享
-
生产者消费者模型
-
开启关闭切换时间开销大
-
一般情况下我们开启的进程数不回超过cpu个数的两倍
线程:
- 什么事线程:能被操作系统调度的最小单位(给cpu执行)
- 同一个进程中的多个线程同时可被cpu执行
- 数据共享,操作系统调度的最小单位,可以利用多核,也有数据不安全
- 开启关闭切换时间开销小
CPython中的多线程 - 节省io操作的时间
- gc 垃圾回收机制 线程
- 引用计数 + 分代回收
- 全局解释器锁:主要为了完成gc的回收机制,对不同线程的引用技术的变化记录的更加精准
- 全局解释器锁:GIL (global interpreter lock)
- 导致同一个进程中的多个线程只能有一个线程真正被cpu执行
- 节省的事io操作的时间,而不是cpu计算的时间,因为cpu计算速度非常快,大部分情况下,我们没有办法把一条进程中所有的io操作都规避
pypy gc 不能利用多核
jpython 能利用多核
from threading import Thread, current_thread, active_count, enumerate
import time
import os
def func(i):
print('start%s'%(i))
print(current_thread().ident) # 在线程运行时获取线程的id
time.sleep(1)
print('end%s'%(i))
if __name__ == '__main__':
t1 = []
for i in range(10):
t = Thread(target=func, args=(i,))
t.start()
print(t.ident, os.getpid())
print(active_count()) # 数字 活着的线程数
print(enumerate())
t1.append(t)
for t in t1:
t.join()
print('所有线程都完成了')
# 线程是不能从外部terminate
# 所有的子进程只能是自己执行完代码之后就关闭
# 进程id都一样,线程id不一样
# current_thread 获取当前所在线程的对象 current_thread().ident 通过ident可以获取线程id
# enumerate 列表 存储了所有活着的线程对象,包括主线程
# active_count 活着的线程数
#面向对象的方式起线程
from threading import Thread
class MyThread(Thread):
def __init__(self, a, b):
self.a = a
self.b = b
super().__init__()
def run(self):
print(self.ident)
t = MyThread(1, 2)
t.start()
线程之间的数据共享
from threading import Thread
n = 100
def func():
global n
n -= 1
t_l = []
for i in range(100):
t = Thread(target=func)
t.start()
t_l.append(t)
for t in t_l:
t.join()
print(n) # 0
# 线程之间的数据是共享的
主线程会等待子线程结束之后才结束
- 为什么:主线程结束进程就会结束
守护线程:守护主线程,随着主线程的结束而结束
- 会在主线程的代码结束之后继续守护其他的子线程
守护进程:会随着主进程的代码结束而结束,如果主进程代码结束之后还有其他子进程在运行,守护进程不守护
为什么?守护进程和守护线程不同
- 守护进程和守护线程的原理不同
- 守护进程需要主进程来回收资源
- 守护线程是随着进程的结束才结束的
- 其他子线程-》主线程结束-〉主进程结束-》整个进程中所有的资源都被回收-〉守护线程也会被回收
- 补充:进程是资源分配单位,子进程都需要它的父进程来回收资源,线程是进程中的资源,所有的线程都会随着进程的结束而被回收
- 主线程没有必要回收子线程的资源
9.线程锁
线程之间也存在数据不安全
+= -= *= /= while if 数据不安全 +和复制是分开的两个操作
append和pop 数据安全 列表中的方法活着字典中的方法操作全局变量
if not n:
time.sleep(0.00001)
n.pop()
#while 和 if都不是原子操作
#很可能在进行if判断后,pop操作还没执行,另一个线程就又进程if判断,导致出现pop两次
单例模式的补充
import time
from threading import Thread
class A:
from threading import Lock
lock = Lock()
__instance = None
def __new__(cls, *args, **kwargs):
with cls.lock:
if not cls.__instance:
time.sleep(0.001) # cpu轮转
cls.__instance = super().__new__(cls)
return cls.__instance
def func():
a = A()
print(a)
for i in range(10):
Thread(target=func).start()
线程安全:
- 不要操作全局变量,不要在类里操作静态变量
- += -= *= /= if while 数据不安全
- a = a.strip() 带返回值的都是先计算后赋值 数据不安全
- queue logging 数据安全的
递归锁
在同一个线程中可以被acquire多次
release归还
from threading import Thread, RLock
# Lock 互斥锁
# RLock 递归锁(recursion)
rl = RLock()
rl.acquire()
rl.acquire()
print('被锁住的代码') # acquire多少次便需要release多少次才能正确归还钥匙
rl.release()
rl.release()
互斥锁能完成的,递归锁也能完成
互斥锁效率高,递归锁效率低
死锁的现象是怎么产生的:
- 多把锁,并且在多个线程中交叉使用
- fork_lock.acquire() noodle_lock.acquire()
- fork_lock.release() noodle_lock.release()
- 如果是互斥锁,出现了死锁现象,最快速的解决方法是把所有的互斥锁改为一把递归锁
- 程序的效率会降低
- 如果可以找到多把锁的问题,可以把多把锁改为一把互斥锁效率更高
10.队列
队列:线程之间数据安全的容器队列 get put get_nowait put_nowait
原理:加锁 + 链表
- 先进先出 Queue
- 后进先出 LifoQueue 栈
- 优先级队列 PriorityQueue 根据放入数据的ascii码从小到大进行输出
import queue
q = queue.Queue(4) # fifo 先进先出 4表示只能put四个,如果第五个put需要先get取出一个
q.put(1)
# q.put_nowait()
q.get()
try:
q.get_nowait()
except queue.Empty: # 不是内置的错误类型,而是queue模块中的错误
print('队列为空')
from queue import LifoQueue # last in first out 栈
lq = LifoQueue()
lq.put(1)
lq.get()
from queue import PriorityQueue # 优先级队列
priq = PriorityQueue()
priq.put((2, 'apple'))
priq.put((1, 'banana'))
priq.put((3, 'pen'))
print(priq.get())
print(priq.get())
print(priq.get())
"""
(1, 'banana')
(2, 'apple')
(3, 'pen')
"""
11.池
concurrent.futrues
- 线程池
- 进程池
什么是池:
- 要在程序开始的时候,还没提交任务先创建几个线程或者进程
- 放在一个池子里,这就是池
为什么要用池:
- 如果先开好进程/线程,那么有任务之后就可以直接使用这个池中的数据
- 并且开好的线程或者进程会一直在池中,可以被多个任务反复利用
- 这样极大减少了开启、关闭、调度线程/进程的时间开销
- 池中的线程/进程个数控制了操作系统需要调度的任务个数,控制池中的单位
- 有利于提高操作系统的效率,减轻操作系统负担
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from threading import current_thread
import time
import random
def func(a, b):
print(current_thread().ident, 'start', a, b)
time.sleep(random.randint(1, 4))
print(current_thread().ident, 'end')
return a * b
# 实例化池
tp = ThreadPoolExecutor(4) # 使用的时候只会使用开启的四个线程
future_l = {}
# 向池中提交任务 submit 传参数(按照位置传,按照关键字传)
for i in range(20):
#提交任务的过程是异步非阻塞的
ret = tp.submit(func, i, b=i + 1) # 把任务提交给池 #第一个参数是处理的任务,后两个参数是传给任务的参数,可以按位置或关键字传参
# 获取任务结果
future_l[i] = ret
#print(ret.result()) # Future对象 这里为了获取结果会进行等待,变成同步
for key in future_l: # 同步的 阻塞的
print(key, future_l[key].result()) # 获取到进程的结果
#map 只适合传递简单的参数,且必须是一个可迭代的类型作为参数
import os
import time, random
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def func1(a):
b = a + 1
print(os.getpid(), 'start', a, b)
time.sleep(random.randint(1,4))
print(os.getpid(), 'end')
return a * b
if __name__ == '__main__':
tp = ProcessPoolExecutor(4)
ret = tp.map(func, range(20)) # 缺点:不好传入多个参数
# ret = tp.map(func, ((i, i + 1) for i in range(20))) #传入可迭代的元组
for key in ret:
print(key)
# 回调函数 : 效率最高的
import time, random
from threading import current_thread
from concurrent.futures import ThreadPoolExecutor
def func(a, b):
print(current_thread().ident, 'start', a, b)
time.sleep(random.randint(1,4))
print(current_thread().ident)
def print_func(ret): # 异步阻塞的
print(ret.result())
if __name__ == '__main__':
tp = ThreadPoolExecutor(4)
future_l = {}
for i in range(20): # 异步非阻塞的
ret = tp.submit(func, i, i + 1)
ret.add_done_callback(print_func) # 异步阻塞 回调函数 给ret对象绑定一个回调函数,等ret对应的任务有了结果立即调用print_func
# 这样可以对结果立即处理,而不用按照顺序接收结果处理结果
#ret 这个任务会在执行完毕的瞬间触发print_func函数,并且把任务的返回值对象传递到print_func做参数
# future_l[i] = ret
# for key in future_l: # 同步阻塞的
# print(key, future_l[key].result())
要求:会起池、会提交任务,会获取返回值、会用回调函数
进程池:高计算的场景,没有io操作(没有文件操作|没有数据库操作|没有网络操作|没有input):>cpu_count *1 <cpu_count * 2
线程池:一般根据io的比例定制,cpu_count * 5
12.协程
进程:数据隔离 数据不安全 操作系统级别的 开销非常大 能利用多核
线程:数据共享 数据不安全(有非原子性的操作) 操作系统级别的 开销小 一些和文件操作相关的io只有操作系统能感知到
正常的开发语言,多线程可以利用多核,cpython解释器下多个线程不能利用多核,规避所有io的单线程
协程:数据共享 数据安全 用户级别 更小 不能利用多核 协程的所有切换都基于用户,那么只有用户级别能够感知到的io操作,才会用协程模块做切换来规避(socket,请求网页)
用户级别的好处:减轻了操作系统的负担,一条线程开了多个协程,那么给操作系统的印象是线程很忙这样能争取一些时间片来被cpu执行,程序的效率就提高了
- 是操作系统不可见的
- 协程的本质就是一条线程 多个任务在一条线程上来回切换
- 利用写成的概念实现的内容:来规避io操作,就达到完美一条线程中的io操作降到最低的目的
4cpu:
进程:5个进程
线程:20个
协程:500个
共可以50000个并发
切换并规避io的两个模块
gevent 第三方模块 利用 greenlet (c语言) 底层模块完成的切换 + 自动规避io的功能
- 会用,能处理一些基础的网络操作
asyncio 内置模块 利用 yield 底层语法完成的切换 + 自动规避io的功能
tornado异步的web框架 用yield,发现asyncio也能使用yield完成,再后面出现yield from 更好的实现协程 send也是为了更好实现协程
特殊的在python中提供协程功能的关键字:aysnc await
py3.4之后 底层的协程模块 要求了解async和await两个关键字
- aiohttp模块 并发的爬虫
- flask轻量级的web框架/sanic异步的轻量级的web框架
- async
- await
协程的例子
# from gevent import monkey
# monkey.patch_all()
# import time #这样也能使用time.sleep() 而不用gevent.sleep()
# import socket
import gevent
def func(): # 带有io操作的内容写在函数里,然后提交func给gevent
# request.get/conn.recv
print('start func')
gevent.sleep(1)
print('end func')
#开启一个协程
g1 = gevent.spawn(func)
g2 = gevent.spawn(func)
g3 = gevent.spawn(func)
gevent.joinall([g1, g2, g3])
"""
start func
start func
start func
end func
end func
end func
"""
#g1.join() # 阻塞 直到协程g1任务执行结束
#g2.join() # 阻塞 直到协程g1任务执行结束
#g3.join() # 阻塞 直到协程g1任务执行结束
基于协程的server
from gevent import monkey
monkey.patch_all()
import socket
import gevent
def func(conn):
while True:
msg = conn.recv(1024).decode('utf-8') # 看是否有新的消息来,没有则阻塞,切换到accept等待新的客户端连接
MSG = msg.upper()
conn.send(MSG.encode('utf-8'))
sk = socket.socket()
sk.bind(('127.0.0.1', 8001))
sk.listen()
while True:
conn, addr = sk.accept() # 看是否有新的客户端来,没有则切换到recv接收消息
gevent.spawn(func, conn)
# conn.close()
#sk.close()
基于协程的client
import socket
import time
from threading import Thread
def client():
sk = socket.socket()
sk.connect(('127.0.0.1', 8001))
while True:
sk.send(b'hello')
msg = sk.recv(1024)
print(msg)
time.sleep(0.5)
#sk.close()
for i in range(500):
Thread(target=client).start() # 起500个客户端
gevent只能规避一些io操作,在patch_all参数显示为True则为可以规避的,有一些是不能实现的
def patch_all(socket=True, dns=True, time=True, select=True, thread=True, os=True, ssl=True,
subprocess=True, sys=False, aggressive=True, Event=True,
builtins=True, signal=True,
queue=True, contextvars=True,
**kwargs):
如何检测gevent是否能规避某个模块的io操作呢?
在patch_all()之前打印一次,在patch_all()之后打印一次,如果两次结果不一样,那么就说明能够规避io操作
asyncio模块
import asyncio
async def func(name):
print('strat', name)
# await 会阻塞的函数或者方法
# await 关键字必须写在一个async函数里
await asyncio.sleep(1)
print('end')
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([func('apple'), func('pen')])) # 异步
asyncio原理
import time
def sleep(n):
print('start sleep')
yield time.time() + n
print('end sleep')
def func(n):
print(123)
g = sleep(n)
yield from g
print(456)
n = 1
g1 = func(1)
g2 = func(1.1)
ret1 = next(g1)
ret2 = next(g2)
time_dic = {ret1:g1, ret2:g2}
while time_dic:
min_time = min(time_dic)
time.sleep(min_time-time.time())
try:
next(time_dic[min_time])
except StopIteration:
pass
del time_dic[min_time]
13.内容回顾
14.内容回顾
(1)清聊聊进程队列的特点和实现原理:
特点:
- 进程之间通信
- 数据安全
- 先进先出
实现原理:
- 基于管道+锁
- 管道基于文件级别的socket + pickle实现的
(2)你了解生产者消费者模型吗?如何实现
了解,为什么了解?工作经历:采集图片/采集音乐:由于要爬取大量的数据,想要提高爬取效率
有用过一个生产者消费者模型,这个模型是我自己写的,消息中间件用的是redis
获取网页的过程作为生产者,分析网页,获取所有歌曲链接作为消费者
自己写监控活着是自己写邮件报警系统,监控程序作为生产者,一旦发现了
有问题的程序就需要发送的邮件信息交给消息中间件redis
消费者就从中间件中取值,然后来处理发邮件的逻辑
什么时候用过?项目或者例子
在python中实现生产者消费者模型可以用哪些机制:消息中间件、celery:定时发短信的任务
(3)从你的角度说说进程在计算机中扮演什么角色
- 资源分配的最小单位
- 进程与进程之间内存隔离
- 进程是由操作系统负责调度的,并且多个进程之间是一种竞争关系
- 所以我们应对进程的三状态时刻关注,尽量减少进程中的io操作,或者在进程里开线程来规避io
- 让我们写的程序在运行的时候能够更多的占用cpu资源
(4)线程之间数据安全吗
- 线程之间数据共享
- 多线程的情况下
- 如果在计算某一个变量的时候,还要进行赋值操作,这个过程不是由一条完整的cpu指令完成的
- 如果在判断某个bool表达式之后,再做某些操作,这个过程不是由一条完整的cpu指令完成的
- 在中间发生了GIL锁的切换(时间片轮转),可能会导致数据不安全
- 判断数据是否安全:
- 是否数据共享,是同步还是异步(数据共享并且异步)
- += -= *= /= 赋值 = 计算之后,数据不安全
- if while 条件 这两个判断是由多个线程完成的,数据不安全
(5)池 concurrent.futures
- 进程池 p = ProcessPoolExecutor(n)
- 线程池 p = ProcessPoolExecutor(n)
- future = submit 提交任务
- future.result() 获取结果
- map 循环提交任务
- add_done_callback 回调函数
(6)协程:本质是一个线程,能够在一个线程内的多个任务之间来回切换
特点:数据安全,用户级别,开销小,不能利用多核,能识别的io操作少
gevent
- 第三方模块 完成并发的socket server
- 协程对象.spawn(func,参数)
- 能识别的io操作也是有限的
- 并且想要让gevent能够识别一些导入的模块中的io操作
- from gevent import monkey
- monkey.patch_all()
asyncio
- 内置模块
- await 写好的asyncio中的阻塞方法
- async 标识一个函数时协程函数,await语法必须用在async函数中
import asyncio
async def func():
print('asdfa')
await asyncio.sleep(1)
print('agsg')
loop = asyncio.get_event_loop()
loop.run_until_complete(func())
#loop.run_until_complete(asyncio.wait([func(), func()]))
(7)思维导图-并发
进程:特点,操作模块 基础方法和特点
线程:GIL
协程:在爬虫的时候学到的模块都是基于协程实现的,flask框架/sanic框架 gevent asyncio 能够识别的大部分io在网络
其他概念:同步阻塞 异步非阻塞 并发并行 调度算法 擦做系统的发展