zoukankan
html css js c++ java
爬虫基础总结1
html
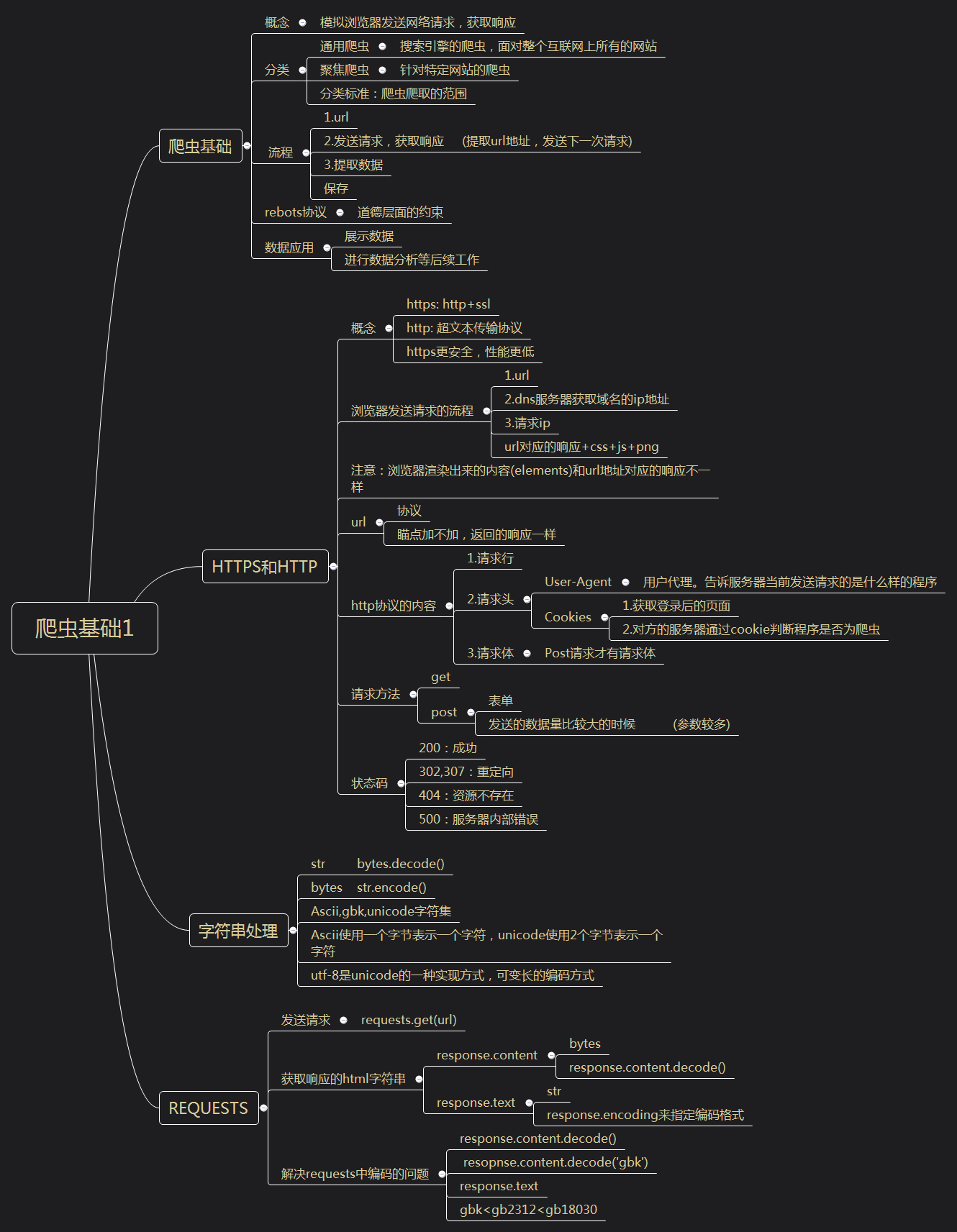
爬虫基础
概念
模拟浏览器发送网络请求,获取响应
分类
通用爬虫
搜索引擎的爬虫,面对整个互联网上所有的网站
聚焦爬虫
针对特定网站的爬虫
分类标准:爬虫爬取的范围
流程
1.url
2.发送请求,获取响应 (提取url地址,发送下一次请求)
3.提取数据
保存
rebots协议
道德层面的约束
数据应用
展示数据
进行数据分析等后续工作
HTTPS和HTTP
概念
https: http+ssl
http: 超文本传输协议
https更安全,性能更低
浏览器发送请求的流程
1.url
2.dns服务器获取域名的ip地址
3.请求ip
url对应的响应+css+js+png
注意:浏览器渲染出来的内容(elements)和url地址对应的响应不一样
url
协议
瞄点加不加,返回的响应一样
http协议的内容
1.请求行
2.请求头
User-Agent
用户代理。告诉服务器当前发送请求的是什么样的程序
Cookies
1.获取登录后的页面
2.对方的服务器通过cookie判断程序是否为爬虫
3.请求体
Post请求才有请求体
请求方法
get
post
表单
发送的数据量比较大的时候 (参数较多)
状态码
200:成功
302,307:重定向
404:资源不存在
500:服务器内部错误
字符串处理
str bytes.decode()
bytes str.encode()
Ascii,gbk,unicode字符集
Ascii使用一个字节表示一个字符,unicode使用2个字节表示一个字符
utf-8是unicode的一种实现方式,可变长的编码方式
requests
发送请求
requests.get(url)
获取响应的html字符串
response.content
bytes
response.content.decode()
response.text
str
response.encoding来指定编码格式
解决requests中编码的问题
response.content.decode()
resopnse.content.decode('gbk')
response.text
gbk<gb2312<gb18030
查看全文
相关阅读:
ssh -vT git@github.com get “ No such file or directory” 错误
提高Bash使用效率的方法
mybatis的update使用选择
Ping 的TTL理解
为什么要使用oath协议?
Rest Client插件简单介绍
idea中查看java类继承图
CSS单行文本溢出显示省略号
js里父页面与子页面的相互调用
css font的简写规则
原文地址:https://www.cnblogs.com/wsilj/p/12735281.html
最新文章
关于浏览器出现滚动条和消失页面不滚动的解决方案
HTML5可用的css reset
响应式布局(rem布局),使用JS动态设置fontsize
分离IE9以下浏览器
《转》'autocomplete="off"'在Chrome中不起作用解决方案
整屏滚动,滚轮/键盘控制
html页面导入文件 使用include后多出一空白行的解决
对话iSpeak许旭东:购酷6股份和雷军周鸿祎无关
游戏语音软件iSpeak,是雷军与周鸿祎“友爱过”的一桩证明
is大战YY的故事
热门文章
iSpeak
IS语音
YY语言
web
网络站点
外存===内存
外存
GitHub学习三-远程版本库更新与提交
GitHub学习二-将本地Git库与Github上的Git库相关联
Github的gitignore
Copyright © 2011-2022 走看看