一. 介绍其他类型的运算符。
除了前面介绍的+,-,*,/,%,+连接符外,还有两种++,--。这算是一种快捷运算符,只是针对特殊情况使用,不能定义太多。
二. ++自增
定义:在原有数据的基础上加一,在赋给原有数据。将运算和幅值合并在一起。
对自增运算进行了演示,结果如下:对于++的使用方法还不熟悉。


除非是代码块的开头定义,否则只要是代码块里面的语句,都必须用分号隔开或结束。
注意:自增运算并不简单,相同的输出结果可以有两种书写方法。例如:写成a++,或者++a都是可以的。这后面存在着深刻的原理,并非看着那么简单。
这里面实际上就是一个优先级的问题。a++是a先参与左侧的运算,然后a再加一,而++a是不管左侧是什么,先进行a加一,再将a代入左侧的运算。++a显示出自增的优先级是高于算术运算符的。(后期对于运算符的种类要进行深究。)
例子:a=3; b=a++;过程是,b=a=3,然后a=a+1=4.
a=3; b=++a;过程是,a=a+1=4, 然后b=a=4;
b*a++ b*a a=a+1
b*++a a+1 b*a
无论是a++还是++a,a进行一次运算后都是加一,但是左侧的赋值对象的值会产生变化。
在视频的讲解中,我们对于变量的定义又有了新的认识。可以先不进行初始定值,只要在最后的输出中变量有一个具体的值即可。

还有哪怕我定义的变量不全,只要输出语句中,没有用到该变量,DOS也不会报错。如下:

三. 对a++进行底层的分析
以int a=3,b; b=a++; 为例,进行分析。开始,是这么描述的:a先进行其他的运算后(在这里就是先进行赋值),再进行自增。但是,就赋值语句来说,应该是先将右侧的计算结束,最终再进行赋值。看着前后貌似是矛盾,正确的底层运算是这样的,a在进行自增之前,原有的指先进行了保存,然后进行a的自增,接着计算机再将保存的原有a值赋给b。
下面的示例中,更能说明这样的问题底层运算的先后顺序问题。

注意:虽然这边正确的计算顺序,我们已经知道,但是计算机的底层运算为什么是这样的?目前所谈论的都是如何正确地做计算,并没有说这么做的原因。
四. 赋值运算符
前面我们见识过最简单的,就是=,其实还有很多扩展:+=,-=,*=,/=,%=。
举例来说明扩展运算符的功能,a+=2;这个意思就是a=a+2, 这是一个简写的符号。
之所以会有这些扩展的,赋值运算符的出现其实是有来源的,我们下面回顾下之前讲过的变量的运算。
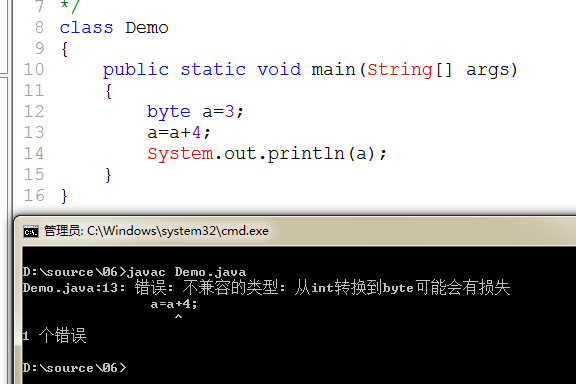
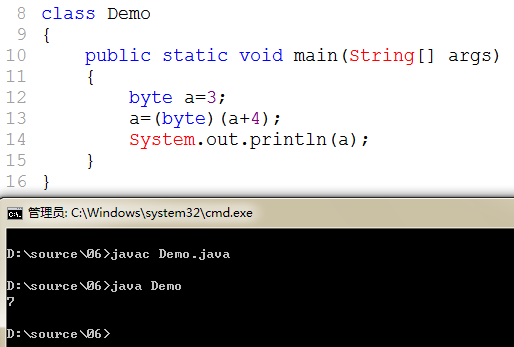
上面的java源程序中,我们从第一步进行分析。byte a=3; 这里3是int类型,将其赋值给byte类型的变量a,计算机会进行判断,看这个四个字节大小的常量,其真正的值是否在byte的范围内,如果在的话,进行强制类型转换,从而赋值给byte类型的变量a。a=a+4,这里将byte类型的变量和int类型的常量4进行相加,会自动提升类型到int型,且最终会得到一个结果,但这个结果是不确定的,可能大于byte的范围,也可能小于,所以强制将int类型的结果转为byte类型赋值,会有一个精度缺失的可能。
为了杜绝上面的这种精度缺失,扩展的,赋值运算符就是为了这个诞生的。
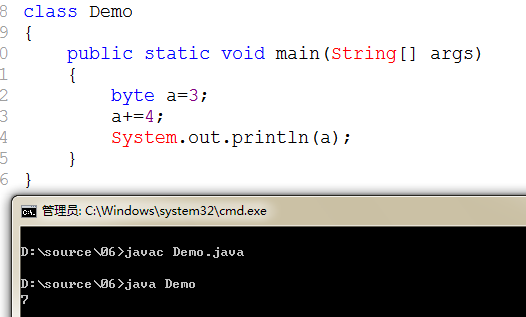
采用+=的形式,在这里就不会有精度的缺失。为什么 a+=4;和a=a+4的结果不一样?a+=4和a=3一样,是一个经过判断后的,系统自动进行强转赋值语句,是赋值运算所具备的特点。而a=a+4没有强转的过程,需要手动书写(byte)(a=a+4)才行,不能强转相当于将int输入给byte,这就是错误语句。验证结果如下所示: