
网络爬虫是从web中发现,下载以及存储内容,是搜索引擎的核心部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
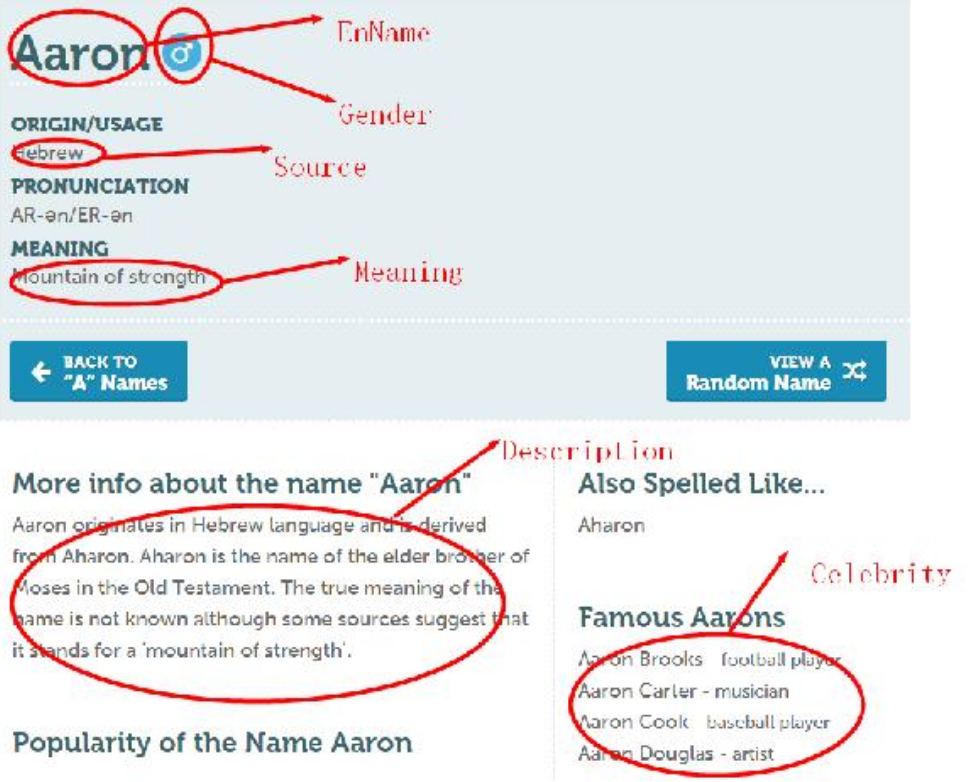
获取A-Z每个名字的姓名(Ename)、ORIGIN/USAGE、SOURCE、MEANING,More info about the name等,并存入csv中。
调试过程中遇到的问题
(1)只能爬取A姓名字第一页
解决方案:用一个for循环来获取A姓名字的所有页

(2)只能爬取A姓所有名字,不能爬取 A-Z所有名字
解决方案:嵌套一个for循环,遍历A-Z

(3)不知道如何获取名字的性别
解决方案:发现他隐含在标签中,先获取他的标签,再用正则表达式

(4)爬取时间太长
解决方案:添加headers,分别写入两个文件,然后写入读取
(5)写入csv的问题
解决方案:写入csv的方法有很多,我选择了pandas模块中的方法。因为考虑到有不少列表需要写入,为了表格的美观,选择了具有二维数组特征的Dataframe来直接写入csv。
代码
#获取所有BabyNames
import requests from bs4 import BeautifulSoup import re import io import sys import pandas as pd import time sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') url_base="https://babynames.net/all/starts-with/" names_list = [] headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': '__gads=ID=393fb892132ab899:T=1575784353:S=ALNI_Mb1L-D-T9C5w-Xf-Q2Qx2cWkHuyXQ; __utmc=162764335; __utmz=162764335.1575784365.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; __utma=162764335.357337691.1575784352.1575784352.1575784352.1; __utmb=162764335.1.10.1575784365; _omappvp=OclocO2kUZEzf0PDHSVwl1dU5Aqr14TLWMKmLL5D0FwX7E6cWz1zX7SgHo3Flip2e0WsWWtGEXa3T14HpH4yiJVdahVerZBL; _omappvs=1575784367123; __atuvc=1%7C50; __atuvs=5dec8fad55e05242000' } for i in range(ord("A"),ord("Z")+1): url1 = url_base+str.lower(chr(i)) for j in range(2): url1_new = url1+'?page='+str(j+1) r=requests.get(url1_new,headers=headers) time.sleep(1) demo=r.text soup=BeautifulSoup(demo,"html.parser") Ename=soup.find_all(attrs={'class': 'result-name'}) aa = Ename[:] bb = [str(i) for i in aa] cc = ''.join(bb) pattern = re.compile('class="result-name">(.*?)</span>', re.S) results = re.findall(pattern, cc) #print("has scaped:",url1_new) for result in results: names_list.append(result) f=open("wt.txt","w+") f.write(str(names_list)) f.close() print(names_list)
所有BabyNames的信息,并存入csv中
import requests from bs4 import BeautifulSoup import re import pandas as pd import time headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': '__gads=ID=393fb892132ab899:T=1575784353:S=ALNI_Mb1L-D-T9C5w-Xf-Q2Qx2cWkHuyXQ; __utmc=162764335; __utmz=162764335.1575784365.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; __utma=162764335.357337691.1575784352.1575784352.1575784352.1; __utmb=162764335.1.10.1575784365; _omappvp=OclocO2kUZEzf0PDHSVwl1dU5Aqr14TLWMKmLL5D0FwX7E6cWz1zX7SgHo3Flip2e0WsWWtGEXa3T14HpH4yiJVdahVerZBL; _omappvs=1575784367123; __atuvc=1%7C50; __atuvs=5dec8fad55e05242000' } with open('wt.txt') as f: names_list_1 = list(f) names_list_2=' '.join(names_list_1) names_list=eval(names_list_2) url_intro = 'https://babynames.net/names/' orgin_list = [] sex_list = [] intro_list = [] for i in names_list: url_In = url_intro+str.lower(i) res = requests.get(url_In,headers=headers).text time.sleep(1) soup=BeautifulSoup(res,"html.parser") res1 = soup.body cop3 = re.compile(r'<span class="result-gender (.*?)"></span>') sex = re.findall(cop3,str(res1)) sex_1=' '.join(sex) sex_list.append(sex_1) cop = re.compile(r'<dd>(.*?)</dd>') orgin = re.findall(cop,str(res1)) orgin_1=' '.join(orgin) orgin_list.append(orgin_1) cop1 = re.compile(r'<p>(.*?)</p>') intro = re.findall(cop1,str(res1)) intro_1=' '.join(intro) intro_list.append(intro_1) print("has got:",i) print("scrapy ended!") print("starting write in frame...") data = { 'EnName': names_list, 'Gender':sex_list, 'ORIGIN/USAGE PRONUNCIATION MEANING':orgin_list, 'Description':intro_list } frame = pd.DataFrame(data) frame.to_csv('wt2.csv') print('Completed!!!')
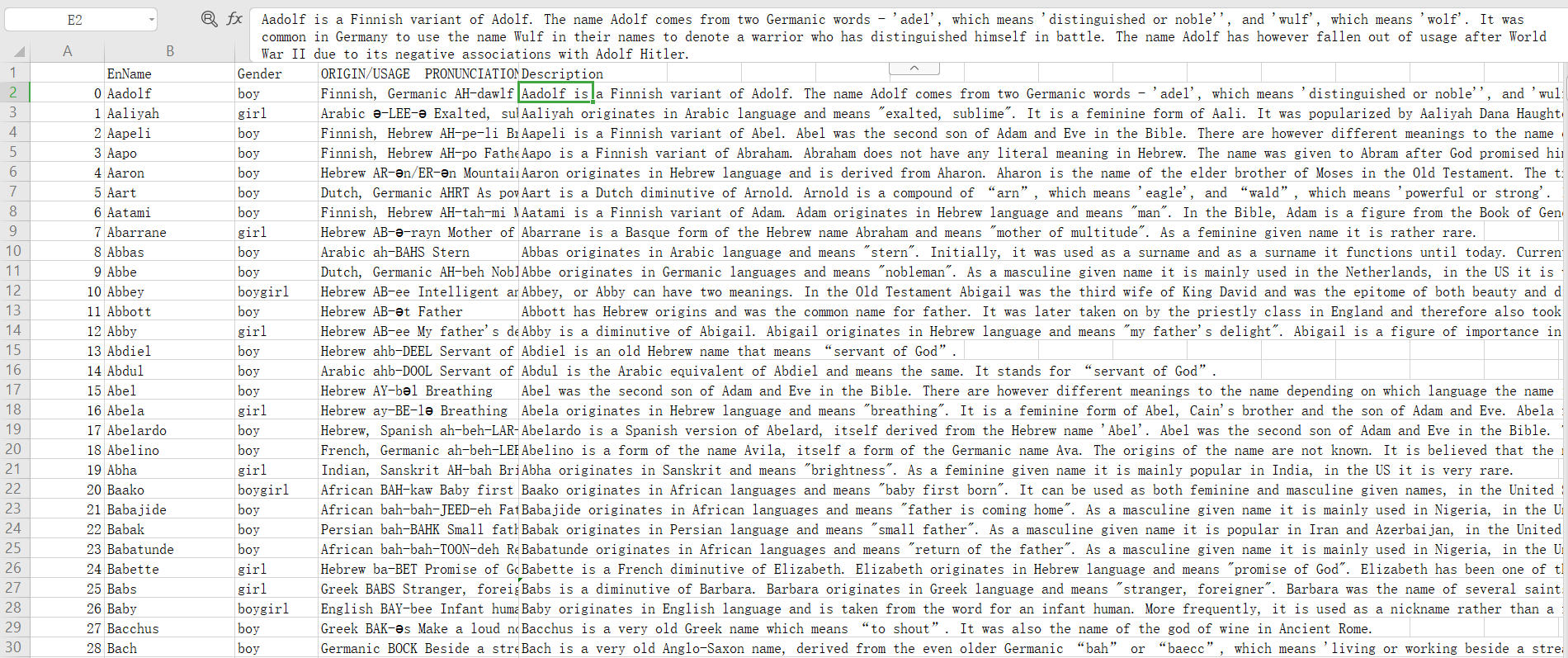
运行结果
总结:
其实本质上来说爬虫就是一段程序代码。任何程序语言都可以做爬虫,只是繁简程度不同而已。从定义上来说,爬虫就是模拟用户自动浏览并且保存网络数据的程序,当然,大部分的爬虫都是爬取网页信息(文本,图片,媒体流)。但是人家维护网站的人也不是傻的,大量的用户访问请求可以视为对服务器的攻击,这时候就要采取一些反爬机制来及时阻止人们的不知道是善意的还是恶意的大量访问请求。