Parquet
- Parquet is a columnar storage format for Hadoop.
- Parquet is designed to make the advantages of compressed, efficient colunmar data representation available to any project in the Hadoop ecosystem.
Physical Properties
- Some table storage formats provide parameters for enabling or disabling features and adjusting physical parameters.
- Now, parquet file provides the following physical properties.
- parquet.block.size: The block size is the size of a row group being buffered in memory. This limits the memory usage when writing. Larger values will improve the I/O when reading but consume more memory when writing. Default size is 134217728 bytes (= 128 * 1024 * 1024).
- parquet.page.size: The page size if for compression. When reading, each page is the smallest unit that must be read fully to access a single record. If the value is too small, the compression will deteriorate. Default size is 1048576 bytes (= 1 * 1024 * 1024).
- parquet.compression: The compression algorithm used to compress pages. It should be one of uncompressed, snappy, gzip, lzo. Default is uncompressed.
- parquet.enable.dictionary: The boolean value is to enable/disable dictionary encoding. It should be one of either true or false. Default is true.
Parquet Row Group Size
Row Group
- Even though Parquet is a column-orientied format, the largest sections of data are groups of row data rows.
- Records are organized into row groups so that the file is splittable and each split contains complete records.
- Here’s a simple picture of how data is stored for a simple schema with columns A, in green, and B, in blue:
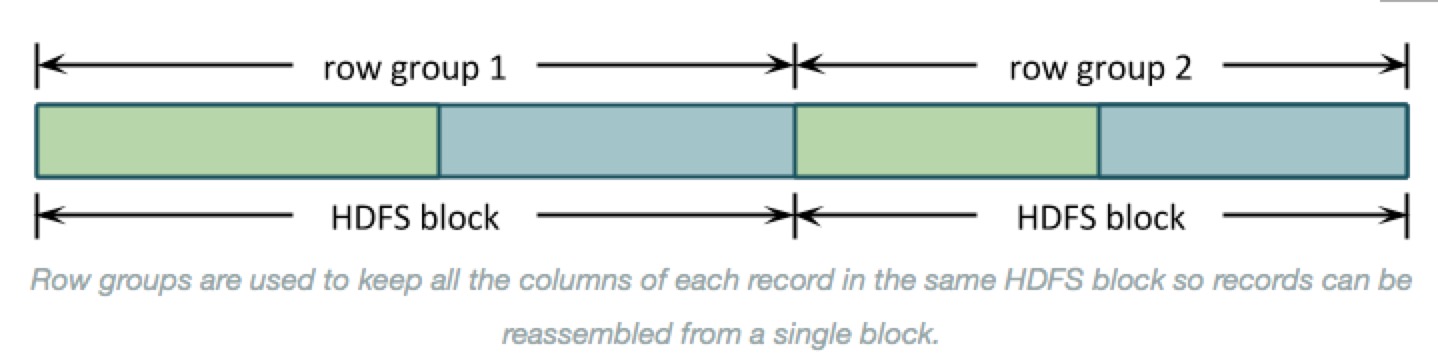
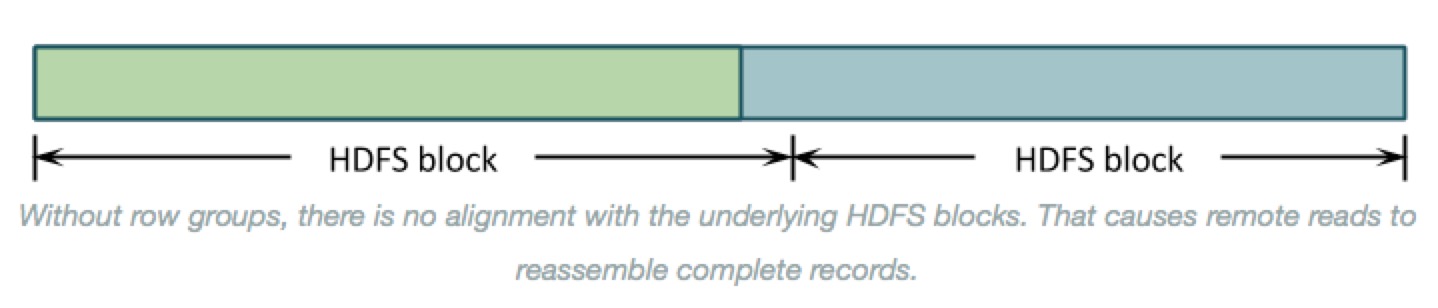
- Why row groups? --> If the entire file were organized by columns then the underlying HDFS blocks would contain just a column or two of each record. Reassembling those records to process them would require shuffling almost all of the data around to the right place. As below:
- There is another benefit to organizing data into row groups: memory consumption. Before Parquet can write the first data value in column B, it needs to write the last value of column A. All column-oriented formas need to buffer record data in memory until those records are written all at once.
- You can control row group size by setting parquet.block.size, in bytes(default: 128MB). Parquet buffers data in its final encoded and compressed form, which uses less memory and means that the amount of buffered data is the same sa the row group size on disk.
- That makes the row group size the most important setting. It controls both:
- The amount of memory consumed for each open Parquet file, and
- The layout of column data on disk.
The row group setting is a trade-off between these two. It is generally better to organize data into larger contiguous column chunks to get better I/O performance, but this comes at the cost of using more memory.
Column Chunks
- That leads to next level down in the Parquet file: column chunks.
- Row groups are divided into column chunkds. The benefits of Parquet come from this organization
- Stroing data by column lets Parquet use type-specific encodings and then compression to get more values in fewer bytes when writing, and skip data for columns u don's need when reading.
pics here - The total row group size is divided between the column chuhnks. Column chunk sizes also vary widely depending on how densely Parquet can store the values, so the portion used for each column is ususlly skewed.
Recommendations
- There’s no magic answer for setting the row group size, but this does all lead to a few best practices:
Know ur memory limits
- Total memory for writes is approximately the row group size times the number of open files. If this is too high, then processes die with OutOfMemoryExceptions.
- On the read side, memory consumption can be less by ingoring some columns, but this will usually still require half, a third, or some other constant times ur row group size.
Test with ur data
- Write a file or two using the defaults and use parquet-tools to see the size distributions for columns in ur data. Then, try to pick a value that puts the majority of those columns at a few megabytes in each row group.
Align with Hdfs Blocks
- Make sure some whole number of row groups make apprioxmately one Hdfs block. Each row group must be processed by a single task, so row groups larger than the HDFS block size will read a lot of data remotely. Row groups that spill over into adjacent blocks will have the same problem.
Using Parquet Tables in Impala
- Impala can create tables that use parquet data files, insert data into those tables, convert the data into Parquet format, and query Parquet data files produced by Impala or other components.
- The only syntax required is the STORED AS PARQUET clause on the CREATE TABLE statement. After that, all SELECT, INSERT, and other statements recognize the Parquet format automatically.
Insert
- Avoiding using the INSERT ... VALUES syntax, or partitioning the table at too granular a level, if that would produce a large number of small files that cannot use Parquet optimizations for large data chunks.
- Inserting data into a partitioned Impala table can be a memory-intensive operation, because each data file requires a memory buffer to hold the data before it is written.
- Such inserts can also exceed HDFS limits on simultaneous open files, because each node could potentially write to a separate data file for each partition, all at the same time.
- If capacity problems still occur, consider splitting insert operations into one INSERT statement per partition.
Query
- Impala can query Parquet files that use the PLAIN, PLAIN_DICTIONARY, BIT_PACKED, and RLE encodings. Currently, Impala does not support RLE_DICTIONARY encoding.