一、实验作业
1.全排列
设计思路
定义全局变量 a[10] 初始所有元素为1,数组 out[10] 储存要输出的数,cnt=0记录已排列的数字个数
a[i]==1 , 表示 i 还没排列
main():
输入m.
Arrange(m).
Arrange(int n):
for i=1 to m (从小到大寻找还没排列的数)
如果a[i]等于1
a[i]=0 , out[cnt]=i , cnt++.
如果cnt==m,按顺序输出 out 数组里的元素 , 否则继续排列 Arrange(n-1) .
当从某层函数中退出时,释放该层排列数为可用状态 a[ out[m-n] ]=1
同时这一层排列数恢复未排列状态 cnt--
end
end
代码截图

2.学生成绩管理系统.
函数模块图
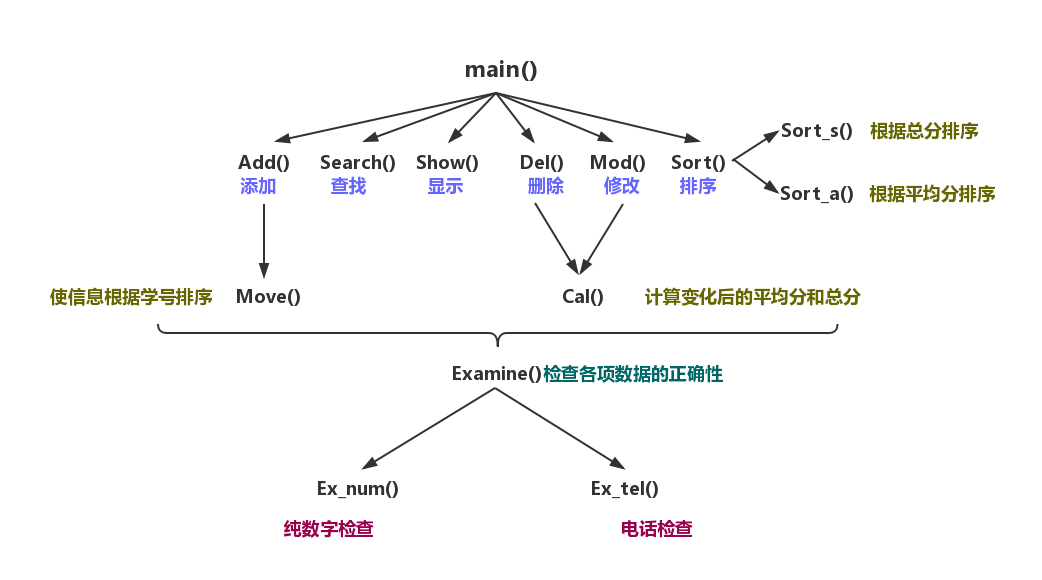
工程文件
- 总行数:437
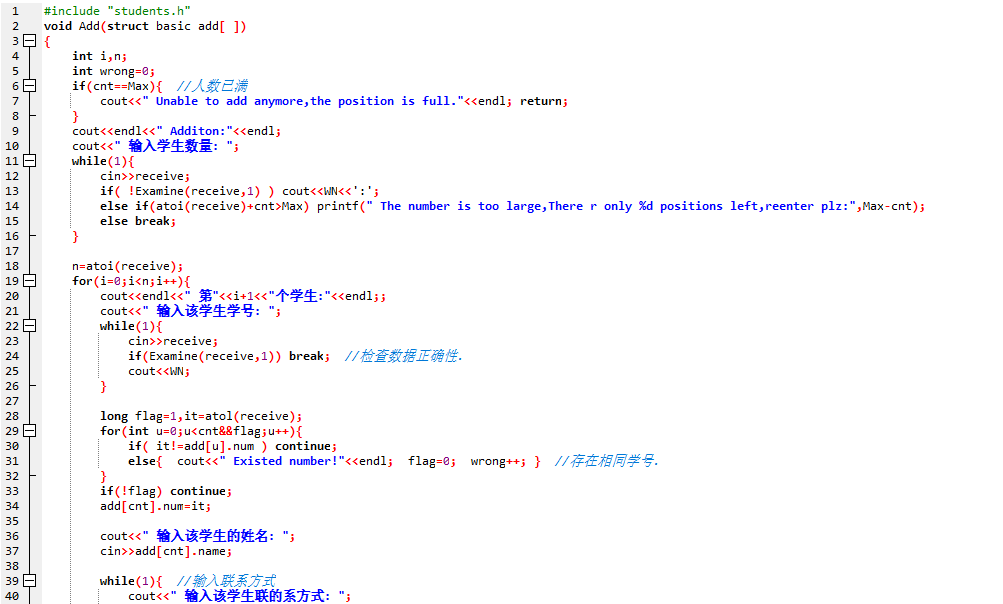
代码截图
头文件:

插入学生信息


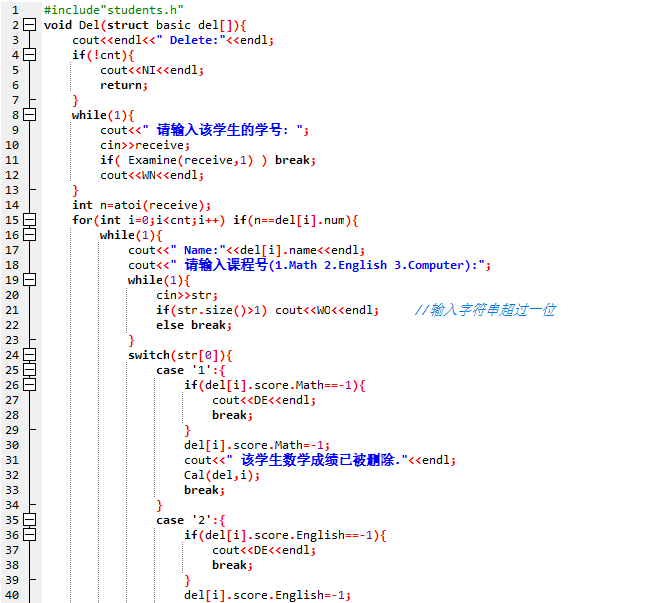
删除学生成绩信息代码

排序代码


调试结果展示
-
添加
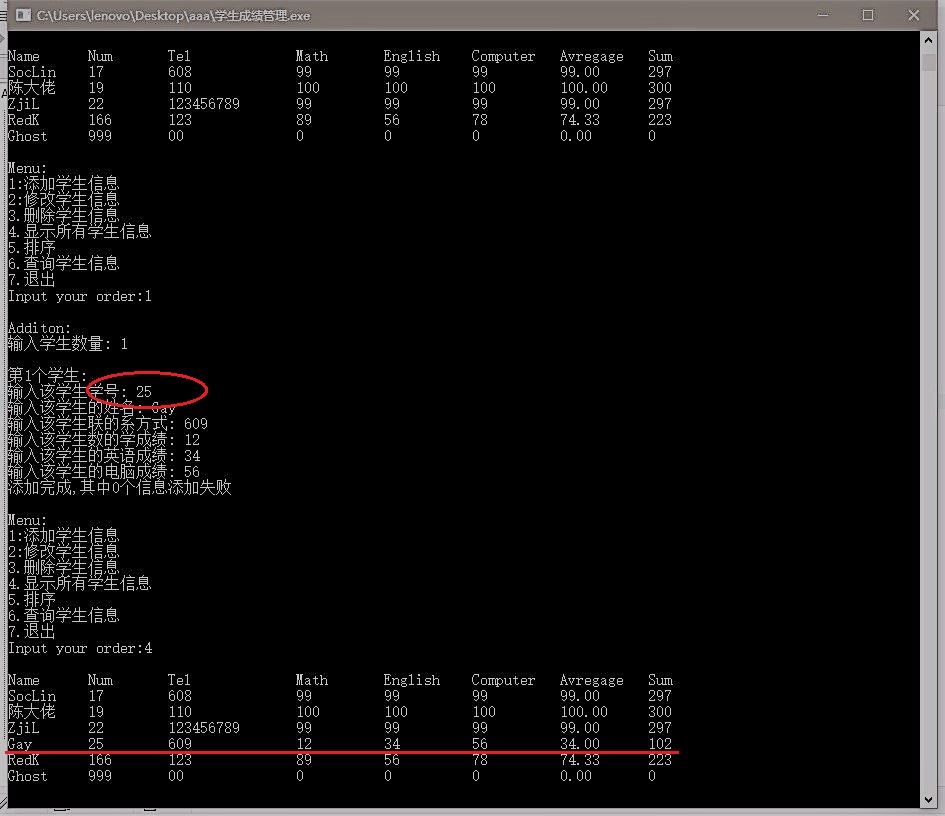
-
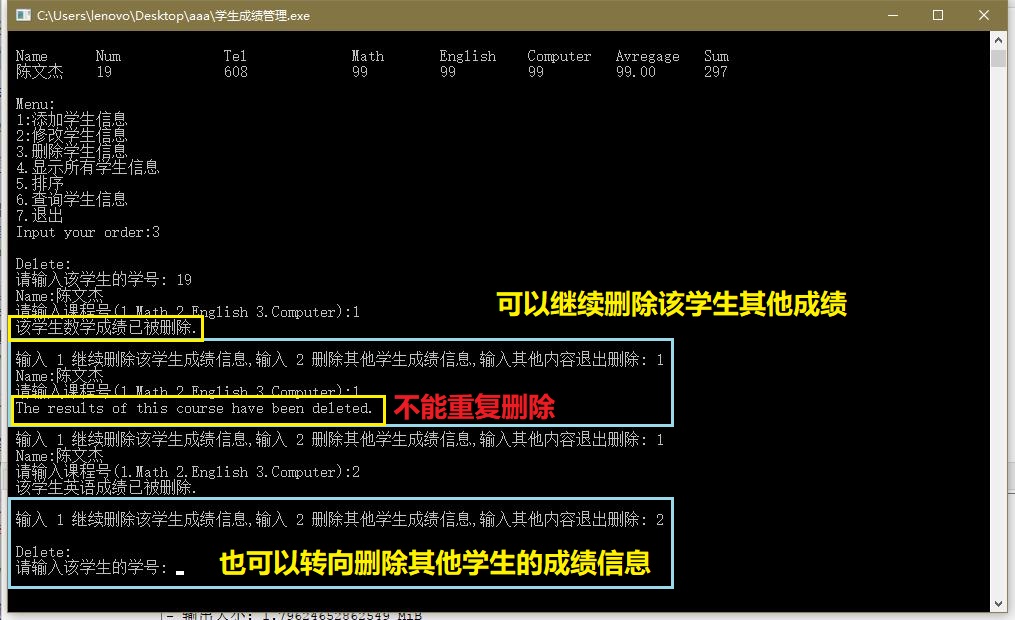
删除

-
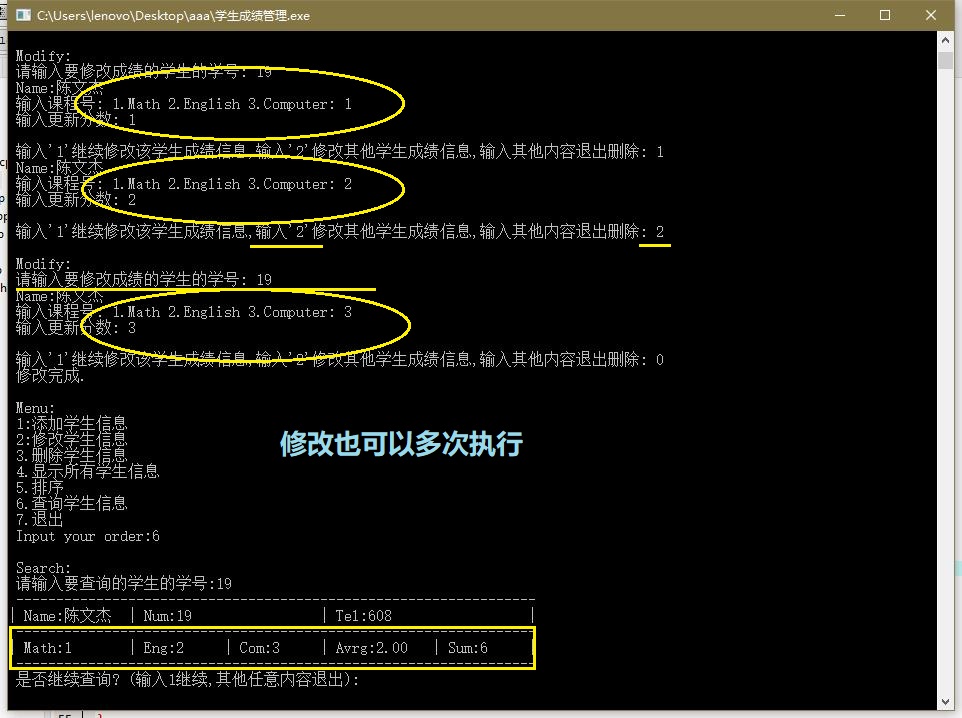
修改
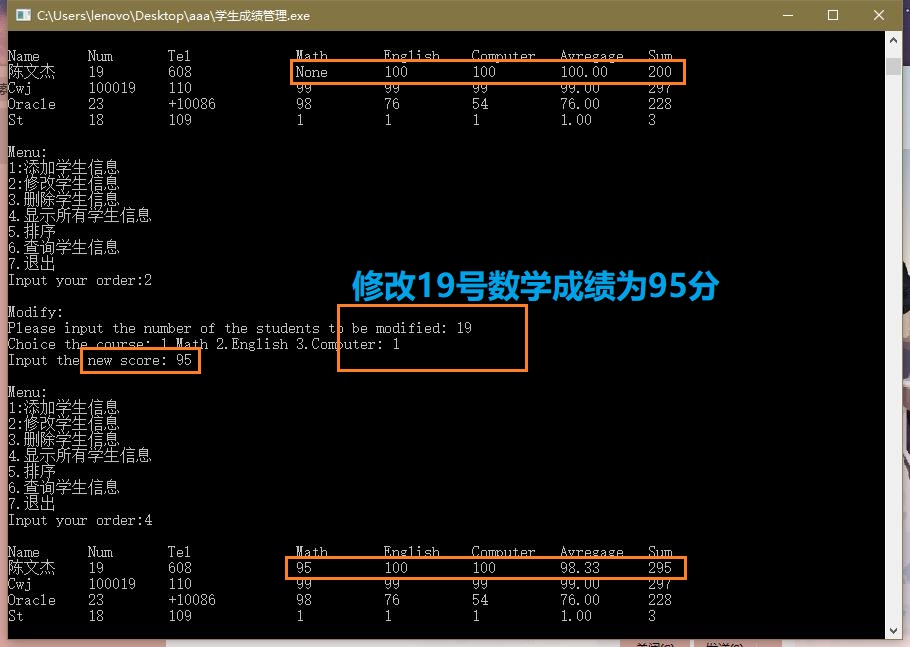
-
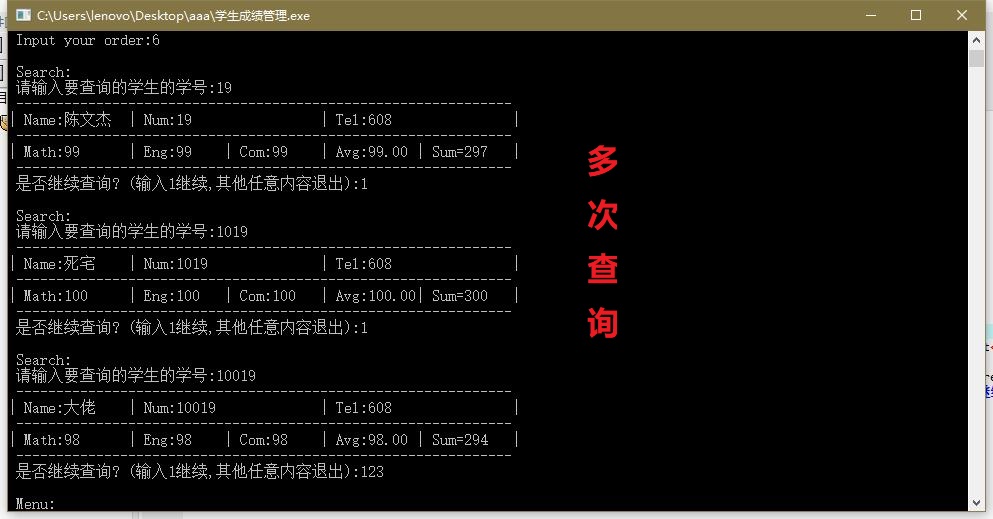
查询
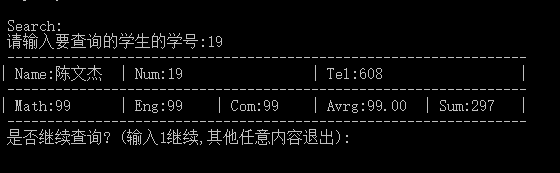
-
排序
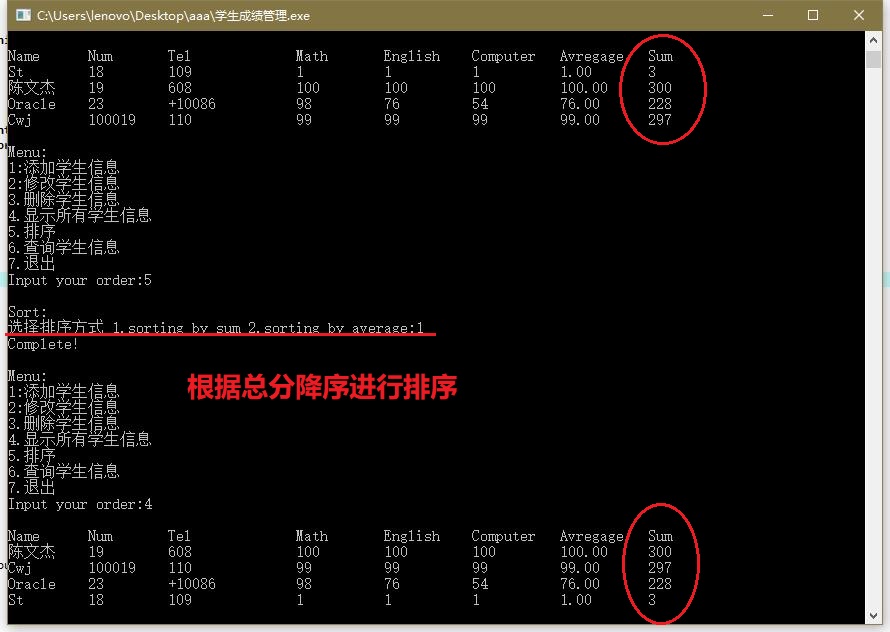
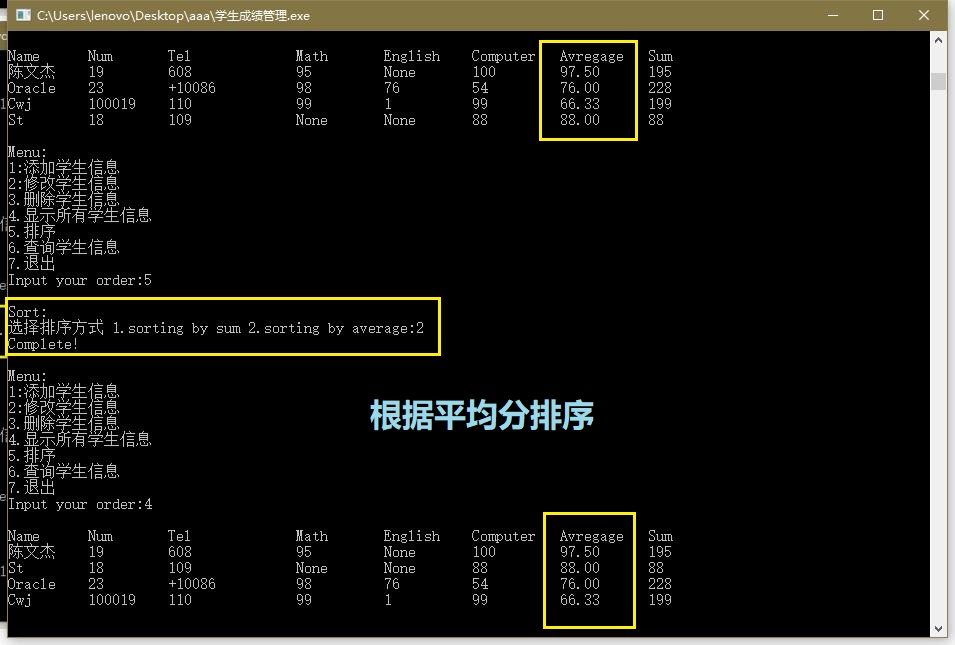
-
数据检查
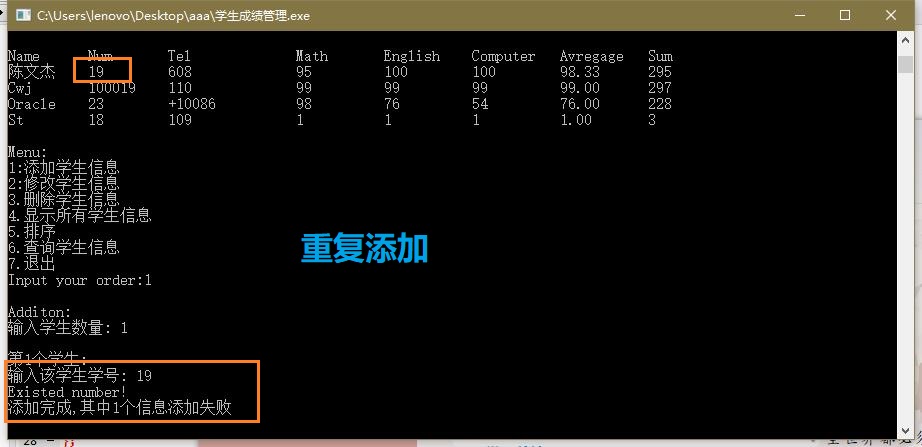


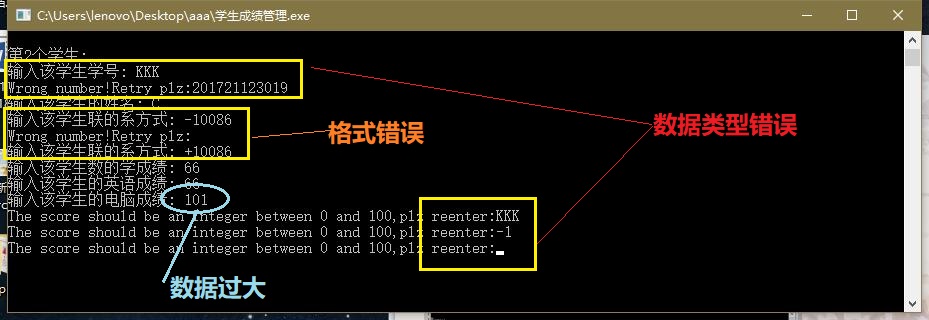


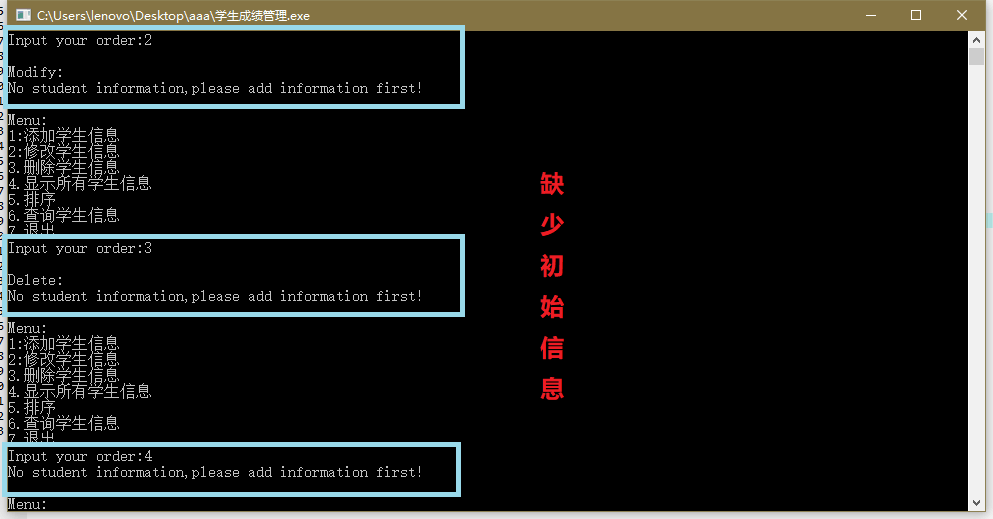
调试问题
- 在建立工程过程中,常会因为修改代码而导致代码无法运行和运行崩溃
没找到好的解决方法,只能将代码复制到新的工程中.
二、截图本周题目集的PTA最后排名。
三、阅读代码
角谷定理:
输入一个自然数,若为偶数,把它除以2,若为奇数,则把它乘以3加1。经过如此有限次运算后,总可以得到自然数值1。求多少次可得到1。
#include <stdio.h>
int f(int i)
{
printf("%d ", i);
if (i == 1) return 1;
if (i %2==1)
return f(i * 3 + 1) + 1;
else
return f(i / 2) + 1;
}
int main()
{
int i, w;
printf("请输入数字:");
scanf("%d", &i);
w = f(i);
printf("
STEP=%d
", w);
}
- 该代码利用递归不断追溯至 i =1,并利用返回值求步数,
整段代码很简洁,可以少定义一个step参数计算步骤
四、本周学习总结
本周学习内容
函数的嵌套使用
- 对于较大的程序,可对其进行模块化处理.
在一个函数内调用其他函数
本次工程作业中就要用到这种处理.
链表
- 链表是一种物理存储单元上非连续、非顺序的存储结构,通过指针的连接顺序实现.
- 对比数组
链表对于成员的插入删除十分方便,快捷
链表在访问成员时需要按节点顺序寻找,数组可以随机访问其中成员.
内存的分配的释放
- 在代码中,为了节约内存,可以动态生成数据.其利用的是malloc()函数,
而利用free()函数可以及时释放动态分配得来的空间.
使用这两种函数前都需要调用库函数 #include<stdlib.h>
宏定义
- 宏定义末尾不需要加分号
- 利用宏定义可以提高程序通用性和可读性
- 宏定义可以嵌套使用
- 宏定义的缺点:
无法对宏定义中的变量进行类型检查
宏定义时如果不对分量加括号,展开时的表达式往往不是想要的
如 #define MUL(A,B) A*B 调用 MUL(a+b,c) 时展开式为 a+b*c.
二级指针
- 指向指针的指针,称为二级指针,目的是获取这个地址,其表现形式是地址.
- 定义方式: (类型名) **(二级指针变量名) .
- 可以指向指针变量,也可以指向数组.
- 在A指向B、B指向C的指向关系中,如果A、B、C都是变量,即C是普通变量,B是一级指针变量,存放着C的地址,A是二级指针变量,其中存放着B的地址,则这3个变量分别在内存中占据各自的存储单元.
学习体会
- 接触并且第一次完成一个工程之后,感觉代码量大大提升,特别一旦对各个数据进行判断正确性,就要多出几行.整体下来就要多出许多代码.而如果要再多出更加细化的判断,代码量肯定会有更大的提升.不过这也能让我们对待自己的程序时能够更加严谨.