一:什么是全文检索
数据分类
结构化数据:有固定的格式和有限的长度,比如Oracle和mysql数据库中的数据,可以利用sql语句查询,如果查询的数据量大时,可以在数据库中创建索引,但是此时不支持模糊查询
非结构化数据:没有固定的的格式和长度,比如磁盘上的文件如txt,pdf等,)顺序扫描法(Serial Scanning),全文检索(Full-text Search)
对数据源创建索引,在索引库中搜索
二:如何实现全文检索
使用Lucene
三:什么是Lucene
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包
四:Lucene实现流程
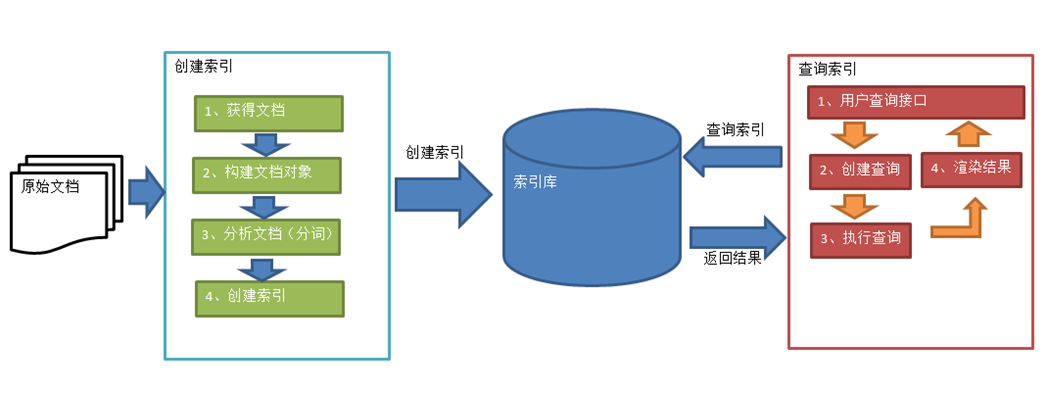

获得文档对象:
应用场景:站内搜索,通过IO流
构建文档对象:
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下图:
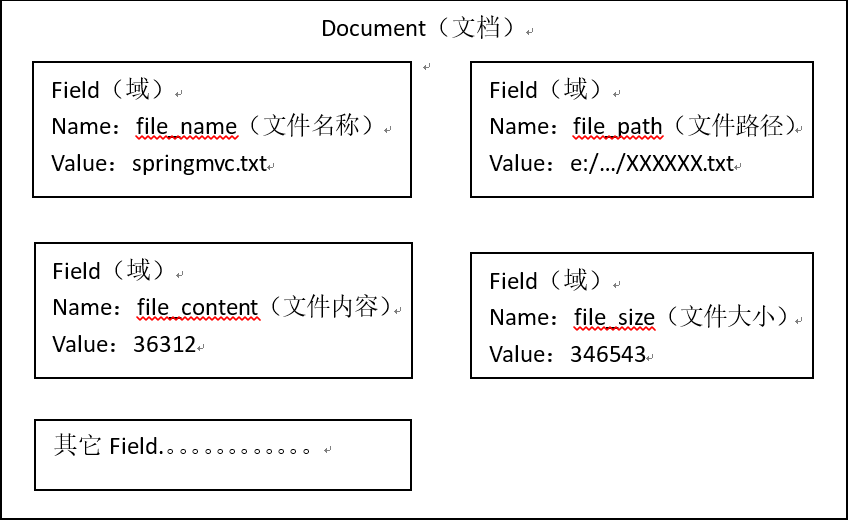
注意: (1)每个Document可以有多个Field
(2)不同的Document可以有不同的Field
(3)同一个Document可以有相同的Field(域名和域值都相同)
(4)每个文档都有一个唯一的编号,就是文档id。
分析文档:
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
Lucene is a Java full-text search engine.
分析后得到的语汇单元:
lucene、java、full、search、engine
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
例如:文件名中包含apache和文件内容中包含的apache是不同的term。
创建索引:
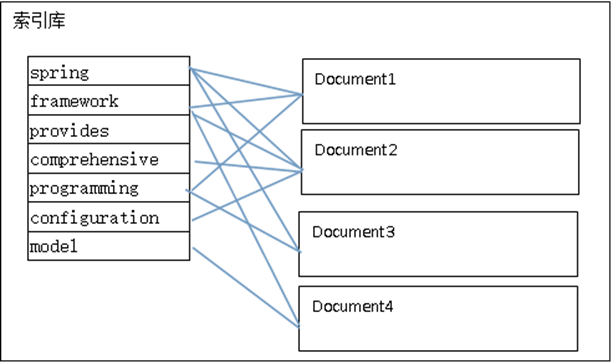
根据不同的term找到对应的Document
注意: (1)创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
(2)传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
用户查询接口:
搜索框输入关键字
五:入门案例
导入相关jar包
IndexWriterTest.java
1 package com.it.lucene;
2
3 import java.io.File;
4 import java.io.IOException;
5
6 import org.apache.commons.io.FileUtils;
7 import org.apache.lucene.analysis.Analyzer;
8 import org.apache.lucene.analysis.standard.StandardAnalyzer;
9 import org.apache.lucene.document.Document;
10 import org.apache.lucene.document.Field;
11 import org.apache.lucene.document.Field.Store;
12 import org.apache.lucene.document.TextField;
13 import org.apache.lucene.index.IndexWriter;
14 import org.apache.lucene.index.IndexWriterConfig;
15 import org.apache.lucene.store.Directory;
16 import org.apache.lucene.store.FSDirectory;
17
18 public class lucene_first {
19 public static void main(String[] args) throws Exception {
20 //1,指定索引库位置
21 Directory directory =FSDirectory.open(new File("D:\BaiduNetdiskDownload\lucene\indexDatebase").toPath());
22 //指定分词器
23 Analyzer analyzer=new StandardAnalyzer();
24 IndexWriterConfig config=new IndexWriterConfig(analyzer);
25
26 //2,创建写入索引的对象
27 IndexWriter indexWriter=new IndexWriter(directory, config);
28
29 //3获取原文档
30 File scrFile=new File("D:\BaiduNetdiskDownload\lucene\searchSource");
31 //遍历
32 File[] listFiles = scrFile.listFiles();
33 for (File file : listFiles) {
34 Document doc=new Document();
35 //将域写入到文档中
36 //1),文件名称
37 String name = file.getName();
38 Field fileName=new TextField("name",name, Store.YES);
39 doc.add(fileName);
40 //2),文件大小
41 long size = FileUtils.sizeOf(file);
42 Field fileSize=new TextField("size",size+"", Store.YES);
43 doc.add(fileSize);
44 //3),文件路径
45 String path = file.getPath();
46 Field filePath=new TextField("path",path+"", Store.YES);
47 doc.add(filePath);
48 //4),文件内容
49 String content = FileUtils.readFileToString(file);
50 Field fileContent=new TextField("content",content, Store.YES);
51 doc.add(fileContent);
52
53 //4,将文档写入索引库
54 indexWriter.addDocument(doc);
55 }
56 //5关闭资源
57 indexWriter.close();
58 }
59 }
运行程序后,在索引库中可以查看到索引文件,通过luke可视化工具查看到
IndexReaderTest.java
1 package com.it.lucene;
2
3 import java.io.File;
4 import java.io.IOException;
5
6 import org.apache.commons.io.FileUtils;
7 import org.apache.lucene.analysis.Analyzer;
8 import org.apache.lucene.analysis.standard.StandardAnalyzer;
9 import org.apache.lucene.document.Document;
10 import org.apache.lucene.document.Field;
11 import org.apache.lucene.document.Field.Store;
12 import org.apache.lucene.document.TextField;
13 import org.apache.lucene.index.DirectoryReader;
14 import org.apache.lucene.index.IndexReader;
15 import org.apache.lucene.index.IndexWriter;
16 import org.apache.lucene.index.IndexWriterConfig;
17 import org.apache.lucene.index.Term;
18 import org.apache.lucene.search.IndexSearcher;
19 import org.apache.lucene.search.Query;
20 import org.apache.lucene.search.ScoreDoc;
21 import org.apache.lucene.search.TermQuery;
22 import org.apache.lucene.search.TopDocs;
23 import org.apache.lucene.store.Directory;
24 import org.apache.lucene.store.FSDirectory;
25
26 public class IndexReaderTest {
27 public static void main(String[] args) throws Exception {
28 //1,指定索引库位置
29 Directory directory =FSDirectory.open(new File("D:\BaiduNetdiskDownload\lucene\indexDatebase").toPath());
30 //2,创建索引读取对象
31 IndexReader indexReader=DirectoryReader.open(directory);
32 //3,创建索引查询对象
33 IndexSearcher indexSearcher=new IndexSearcher(indexReader);
34 //4,查询条件
35 Query query=new TermQuery(new Term("content","spring"));
36 //5,返回查询结果
37 TopDocs result = indexSearcher.search(query, 100);//100指最多返回100个Document
38 System.out.println("总记录数:"+result.totalHits);
39 ScoreDoc[] scoreDocs = result.scoreDocs;
40 for (ScoreDoc scoreDoc : scoreDocs) {
41 int docId = scoreDoc.doc;
42 //获取文件
43 Document doc = indexSearcher.doc(docId);
44 System.out.println("文件名"+doc.get("name"));
45 System.out.println("文件路径"+doc.get("path"));
46 }
47 //6,关闭资源
48 indexReader.close();
49 }
50 }
六:分词器(Aanlyzer)
每个分词器都有tokenStream()方法
中文一般使用第三方分词器IK-Aanlyzer(需要导入相应的包)
下载地址: https://pan.baidu.com/s/1BAujr36FozHuwt6JyVFpHQ 提取码: m3mt
注意:搜索使用的分析器要和索引使用的分析器一致,不然搜索出来结果可能会错乱。
七:Field域的属性概述
是否分析:即是否分词
是否索引:即是否添加到索引库中用来检索
是否存储:即是否用来展示出来
如下图:
|
Field类
|
数据类型
|
Analyzed
是否分析
|
Indexed
是否索引
|
Stored
是否存储
|
说明
|
|
StringField(FieldName, FieldValue,Store.YES))
|
字符串
|
N
|
Y
|
Y或N
|
这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)
是否存储在文档中用Store.YES或Store.NO决定
|
|
LongField(FieldName, FieldValue,Store.YES)
|
Long型
|
Y
|
Y
|
Y或N
|
这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格)
是否存储在文档中用Store.YES或Store.NO决定
|
|
StoredField(FieldName, FieldValue)
|
重载方法,支持多种类型
|
N
|
N
|
Y
|
这个Field用来构建不同类型Field
不分析,不索引,但要Field存储在文档中
|
|
TextField(FieldName, FieldValue, Store.NO)
或
TextField(FieldName, reader)
|
字符串
或
流
|
Y
|
Y
|
Y或N
|
如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略.
|
|
八:索引查询
1,MatchAllDocsQuery(查询索引库中的全部Document)
2,TermQuery(精准查询)
3,NumericRangeQuery(根据数值范围查询)
示例代码:
1 //数值范围查询
2 @Test
3 public void testNumericRangeQuery() throws Exception {
4 //创建一个Directory对象,指定索引库存放的路径
5 Directory directory = FSDirectory.open(new File("E:\programme\test"));
6 //创建IndexReader对象,需要指定Directory对象
7 IndexReader indexReader = DirectoryReader.open(directory);
8 //创建Indexsearcher对象,需要指定IndexReader对象
9 IndexSearcher indexSearcher = new IndexSearcher(indexReader);
10
11 //创建查询
12 //参数:
13 //1.域名
14 //2.最小值
15 //3.最大值
16 //4.是否包含最小值
17 //5.是否包含最大值
18 Query query = NumericRangeQuery.newLongRange("fileSize", 41L, 2055L, true, true);
19 //执行查询
20
21 //第一个参数是查询对象,第二个参数是查询结果返回的最大值
22 TopDocs topDocs = indexSearcher.search(query, 10);
23
24 //查询结果的总条数
25 System.out.println("查询结果的总条数:"+ topDocs.totalHits);
26 //遍历查询结果
27 //topDocs.scoreDocs存储了document对象的id
28 //ScoreDoc[] scoreDocs = topDocs.scoreDocs;
29 for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
30 //scoreDoc.doc属性就是document对象的id
31 //int doc = scoreDoc.doc;
32 //根据document的id找到document对象
33 Document document = indexSearcher.doc(scoreDoc.doc);
34 //文件名称
35 System.out.println(document.get("fileName"));
36 //文件内容
37 System.out.println(document.get("fileContent"));
38 //文件大小
39 System.out.println(document.get("fileSize"));
40 //文件路径
41 System.out.println(document.get("filePath"));
42 System.out.println("----------------------------------");
43 }
44 //关闭indexreader对象
45 indexReader.close();
46 }
4,BooleanQuery(组合条件查询)
示例代码:
1 //组合条件查询
2 2 @Test
3 3 public void testBooleanQuery() throws Exception {
4 4 //创建一个Directory对象,指定索引库存放的路径
5 5 Directory directory = FSDirectory.open(new File("E:\programme\test"));
6 6 //创建IndexReader对象,需要指定Directory对象
7 7 IndexReader indexReader = DirectoryReader.open(directory);
8 8 //创建Indexsearcher对象,需要指定IndexReader对象
9 9 IndexSearcher indexSearcher = new IndexSearcher(indexReader);
10 10
11 11 //创建一个布尔查询对象
12 12 BooleanQuery query = new BooleanQuery();
13 13 //创建第一个查询条件
14 14 Query query1 = new TermQuery(new Term("fileName", "apache"));
15 15 Query query2 = new TermQuery(new Term("fileName", "lucene"));
16 16 //组合查询条件
17 17 /*
18 18 Occur.MUST:必须满足此条件,相当于and
19 19
20 20 Occur.SHOULD:应该满足,但是不满足也可以,相当于or
21 21
22 22 Occur.MUST_NOT:必须不满足。相当于not*/
23 23
24 17 query.add(query1, Occur.MUST);
25 18 query.add(query2, Occur.MUST);
26 19 //执行查询
27 20
28 21 //第一个参数是查询对象,第二个参数是查询结果返回的最大值
29 22 TopDocs topDocs = indexSearcher.search(query, 10);
30 23
31 24 //查询结果的总条数
32 25 System.out.println("查询结果的总条数:"+ topDocs.totalHits);
33 26 //遍历查询结果
34 27 //topDocs.scoreDocs存储了document对象的id
35 28 //ScoreDoc[] scoreDocs = topDocs.scoreDocs;
36 29 for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
37 30 //scoreDoc.doc属性就是document对象的id
38 31 //int doc = scoreDoc.doc;
39 32 //根据document的id找到document对象
40 33 Document document = indexSearcher.doc(scoreDoc.doc);
41 34 //文件名称
42 35 System.out.println(document.get("fileName"));
43 36 //文件内容
44 37 System.out.println(document.get("fileContent"));
45 38 //文件大小
46 39 System.out.println(document.get("fileSize"));
47 40 //文件路径
48 41 System.out.println(document.get("filePath"));
49 42 System.out.println("----------------------------------");
50 43 }
51 44 //关闭indexreader对象
52 45 indexReader.close();
53 46 }
5,queryparser(更具查询语法查询)
查询语法
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
例如:content:java
2、范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
范围查询在lucene中支持数值类型,不支持字符串类型。在solr中支持字符串类型。
3、组合条件查询
1)+条件1 +条件2:两个条件之间是并且的关系and
例如:+filename:apache +content:apache
2)+条件1 条件2:必须满足第一个条件,应该满足第二个条件
例如:+filename:apache content:apache
3)条件1 条件2:两个条件满足其一即可。
例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
例如:-filename:apache content:apache
示例代码:
1 @Test
2 public void testQueryParser() throws Exception {
3 //创建一个Directory对象,指定索引库存放的路径
4 Directory directory = FSDirectory.open(new File("E:\programme\test"));
5 //创建IndexReader对象,需要指定Directory对象
6 IndexReader indexReader = DirectoryReader.open(directory);
7 //创建Indexsearcher对象,需要指定IndexReader对象
8 IndexSearcher indexSearcher = new IndexSearcher(indexReader);
9
10 //创建queryparser对象
11 //第一个参数默认搜索的域
12 //第二个参数就是分析器对象
13 QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());
14 //使用默认的域,这里用的是语法,下面会详细讲解一下
15 Query query = queryParser.parse("apache");
16 //不使用默认的域,可以自己指定域
17 //Query query = queryParser.parse("fileContent:apache");
18 //执行查询
19
20
21 //第一个参数是查询对象,第二个参数是查询结果返回的最大值
22 TopDocs topDocs = indexSearcher.search(query, 10);
23
24 //查询结果的总条数
25 System.out.println("查询结果的总条数:"+ topDocs.totalHits);
26 //遍历查询结果
27 //topDocs.scoreDocs存储了document对象的id
28 //ScoreDoc[] scoreDocs = topDocs.scoreDocs;
29 for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
30 //scoreDoc.doc属性就是document对象的id
31 //int doc = scoreDoc.doc;
32 //根据document的id找到document对象
33 Document document = indexSearcher.doc(scoreDoc.doc);
34 //文件名称
35 System.out.println(document.get("fileName"));
36 //文件内容
37 System.out.println(document.get("fileContent"));
38 //文件大小
39 System.out.println(document.get("fileSize"));
40 //文件路径
41 System.out.println(document.get("filePath"));
42 System.out.println("----------------------------------");
43 }
44 //关闭indexreader对象
45 indexReader.close();
46 }
6,MultiFieldQueryParser(指定多个默认域)
示例代码:
1 @Test
2 public void testMultiFiledQueryParser() throws Exception {
3 //创建一个Directory对象,指定索引库存放的路径
4 Directory directory = FSDirectory.open(new File("E:\programme\test"));
5 //创建IndexReader对象,需要指定Directory对象
6 IndexReader indexReader = DirectoryReader.open(directory);
7 //创建Indexsearcher对象,需要指定IndexReader对象
8 IndexSearcher indexSearcher = new IndexSearcher(indexReader);
9
10 //可以指定默认搜索的域是多个
11 String[] fields = {"fileName", "fileContent"};
12 //创建一个MulitFiledQueryParser对象
13 MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
14 Query query = queryParser.parse("apache");
15 System.out.println(query);
16 //执行查询
17
18
19 //第一个参数是查询对象,第二个参数是查询结果返回的最大值
20 TopDocs topDocs = indexSearcher.search(query, 10);
21
22 //查询结果的总条数
23 System.out.println("查询结果的总条数:"+ topDocs.totalHits);
24 //遍历查询结果
25 //topDocs.scoreDocs存储了document对象的id
26 //ScoreDoc[] scoreDocs = topDocs.scoreDocs;
27 for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
28 //scoreDoc.doc属性就是document对象的id
29 //int doc = scoreDoc.doc;
30 //根据document的id找到document对象
31 Document document = indexSearcher.doc(scoreDoc.doc);
32 //文件名称
33 System.out.println(document.get("fileName"));
34 //文件内容
35 System.out.println(document.get("fileContent"));
36 //文件大小
37 System.out.println(document.get("fileSize"));
38 //文件路径
39 System.out.println(document.get("filePath"));
40 System.out.println("----------------------------------");
41 }
42 //关闭indexreader对象
43 indexReader.close();
44 }
7:IndexSearcher.search()查询方法
|
方法
|
说明
|
|
indexSearcher.search(query, n)
|
根据Query搜索,返回评分最高的n条记录
|
|
indexSearcher.search(query, filter, n)
|
根据Query搜索,添加过滤策略,返回评分最高的n条记录
|
|
indexSearcher.search(query, n, sort)
|
根据Query搜索,添加排序策略,返回评分最高的n条记录
|
|
indexSearcher.search(booleanQuery, filter, n, sort)
|
根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录
|
8:TopDocs(返回的查询结果)
TopDocs topDocs.totalHits 查询到的总
条数