【第一回】---python基本数据类型
Ⅰ、字符串
a:字符串的join(方法)
import argparse
if __name__ == '__main__':
name = "hello"
names = ','.join(name)
print('Hello to %s'%(names));
>> Hello to h,e,l,l,o
Ⅱ、列表
def study_list(length): #36、带有参数的函数
l1 = [1,2,3,4,5,9.0] #37、创建列表,利用符号[]
l2 = list(range(10,10+length)) #38、创建列表,也可以用list()
l3[0]=99 #43、更新列表值
print('l2==l3么?',l2==l3) #44、更新l3后依旧等于l2,因为l3和l2本来就是一个对象,不过换了个名字
l4 = l2.copy() #45、复制一个l2给l4,copy()创建一个一模一样的列表
l4[0]=999
print('删除前',l4)
del l4[0] #47、del语句进行删除列表值,在python中del可以删除所有的变量
l4.append(30) #48、给列表添加值
l4.extend(l1) #49、给列表追加一个序列多个值
print('添加l1后:',l4)
l4.reverse() #50、列表反转
print('反转后:',l4)
l4.sort() #51、sort()函数,将列表进行排序
print('排序后:',l4)
2)、从键盘输入列表:
scores = list(map(int, input("请输入每个士兵的分数:").strip().split(',')))
Ⅲ、元组
def study_tuple(length:int)->bool: #52、解释参数类型的函数创建,->为返回值类型 tuple1 = (1,2,3,4) #53、创建元组,利用()符号,元组的特性是不可以改变 tuple2 = tuple(range(10,10+length)) #54、利用tuple创建元组 print(tuple1.count(1)) #55、元组函数count(),用于输出某个值的数量 print(tuple1.index(1)) #56、元组函数index(),可以按照索引得到值 tuple1[0] = 9 #58、因为元组的不可改变性,所以该语句会出错 tuple3 = tuple1+tuple2 #60、元组虽然不可改变,但是可以通过+号进行合并为另一个元组 print(tuple3,id(tuple3))
Ⅳ、字典
def study_dict(): #学习python中的字典模型,字典是 键->值 的映射
dict1 = {1:'一',2:'二',3:'三',4:'四'} #61、以下为创建字典的3种方法
dict4 = dict([('One',1),('Two',2),('Three',3)])
dict5 = dict({1:'一',2:'二',3:'三',4:'四'})
dict1[1] = '壹' #65、修改字典内容
dict1[5] = '五' #66、添加字典
dict6 = dict1.copy() #68、字典的复制
dict6[1] = 'One'
print(dict1,'<dict1------------dict6>',dict6)
dict1.clear() #69、字典的清空
print(dict1)
del dict1,dict2,dict3,dict4,dict5,dict6 #70、删除字典,也可以用del dict[key]的方式删除某个键
1):字典添加元素
a. Test[‘价格’] = 100
b. xx = {‘hhh’:‘gogogo’}
Test.update(xx)
2):字典删除元素
a. del[aa[‘adress’]] b. vv = aa.pop(‘key名称’)
3):字典的遍历
for item in dict.items(): print(item)
Ⅴ、集合
def study_set(): #python中集合的学习,集合中不存在相等的值
set1 = set(['You','Are','Not','Beautiful']) #71、利用set()函数进行创建集合
set2 = {'You','Are','So','Beautiful'} #72、利用{}创建集合,创建空集合的时候不能用{},因为{}表示字典
set3 = set2.copy() #73、集合的复制
print(type(set1))
print(set1,set2)
print(set1|set2) #74、集合或运算符,得到两个集合中所有元素
print(set1&set2) #75、集合与运算符,得到两个集合共同元素
print(set1^set2) #76、不同时包含于set1和set2的元素
print(set1-set2) #77、集合差运算,得到set1有,set2没有的元素
set1.add('Me too') #79、集合添加元素
print('is语句用法',set3==set2,set3 is set2,set1 is not set2) #80、is和is not语句,is语句用于判断对象是否一样,==判断值是否一样
set3.clear() #81、清空集合,集合变为空
print(set3)
del set3
附加:bool类型 (Python中以下情况默认为False)
Ⅰ:为0的数字,包括0,0.0
Ⅱ:空字符串,包括’’, “”
Ⅲ:表示空值的None
Ⅳ:空集合,包括(),[],{} 其他的值都认为是True。
【第二回】---python函数
Ⅰ、迭代器、生成器、装饰器
1、迭代器:
a、可迭代对象:只要能iter(对象)的就是可迭代对象。如:list,truple,str,dict,set可以执行遍历都是可迭代对象。
备注:可迭代对象转换为迭代器,只需要执行iter(对象)即可
例1:输出一个列表list1,使用iter方法之后为一个迭代器
>>list1 = [1,2,3,4] >>print (iter(list1)) //生成的为迭代器 <list_iterator object at 0x0000027713494F28> >>print (next(list1)) //报错Error:TypeError: 'list' object is not an iterator
b、迭代器:可迭代对象并且能实现next(对象)叫迭代器
例1:输出一个列表list1,使用iter转换为迭代器,再执行next()方法
>>list1 = [1,2,3,4] >>iter1 = iter(list1) //转换为一个迭代器 >>print (next(iter1)) //输出第一个结果 1
2、生成器:生成器生成有两种方式,一种是列表生成式,一种为yield
a、yield,,在函数中可以先将yield想象成return
def foo():
print("starting........")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(next(g))
输出:
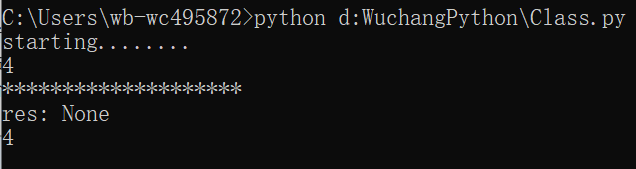
解析:(1)、如果没有yield,g = foo() 输出starting........,存在yield为生成器无结果输出,故g = foo()无结果输出
(2)、第一次遇到next(g)之后,函数开始执行,输出starting........。加上print,将函数结果yield 4返回,故print(next(g))输出前两行
(3)、输出20个*
(4)、第二次遇到next(g)之后,函数从yield之后开始执行,此时res的值已经返回,故输出的结果为none,print(next(g))将yield看作return,故再次打印输出4
例2:包子铺要做包子,如果一次性做1000个,可能存在卖不完浪费的情况,如果吃一个包子,你做一个包子,那么这就不会占用太多空间存储了。
def eat(): for i in range(1,10000): yield '包子'+str(i) e = eat() for i in range(200): next(e)
Ⅱ、递归函数
在一个函数里在调用这个函数本身
例1:从某个目录里面查找日志文件,如果里面的内容是目录,继续执行函数
import os, sys, datetime,re
# nginx日志存放的路径
nginxLogPath="/opt/nginx-1.9.5/logs/"
# 获取昨天的日期
yesterday = (datetime.date.today() + datetime.timedelta(days = -1)).strftime("%Y-%m-%d")
# nginx启动的pid文件
PID = "/var/run/nginx.pid"
def cutNginxLog(path):
"""
切割nginx日志函数
:param path: 日志文件的第一级目录
:return:
"""
logList = os.listdir(path) # 判断传入的path是否是目录
for logName in logList: # 循环处理目录里面的文件
logAbsPath = os.path.join(path, logName)
if os.path.isdir(logAbsPath): # 如果是目录,递归调用自己,继续处理
cutNginxLog(logAbsPath)
else: # 如果是日志文件,就进行处理
# 分割日志
re_Num = re.compile(r'^[a-zA-Z]')
# 判断日志文件是否是字母开头,如果是日期开头就不切割
if re_Num.search(logName):
logNewName = yesterday + "_" + logName # 新日志文件名称列如:2018-11-8_access.log
oldLogPath = os.path.join(path, logName) # 旧日志文件绝对路径
newLogPath = os.path.join(path, logNewName) # 新日志文件绝对路径
os.rename(oldLogPath, newLogPath)
cmd = " kill -USR1 `cat %s` "% PID
res = os.system(cmd)
if res != 0:
return "重新加载nginx失败"
cutNginxLog(nginxLogPath)