一、概述
ArrayList:数组集合。与数组不同,数组一旦创建,长度固定,但是ArrayList的长度是动态的,不受限制,可以存储任意多的对象,但是只能存储对象。
查询、修改、新增(新增的位置在尾部)快,删除、新增(新怎的位置在中间)慢。适用于查询、修改较多的场景。
LinkedList:双向链表集合。元素有序且可以重复。
查询、修改(需要遍历集合),新增‘删除(只需要修改前后节点的链接)快,适用于新增、删除较多的场景。
HashMap:结合数组和链表的优势,期望做到增删改查都快速,时间复杂度接近于O(1)。当哈希算法较好时,Hash冲突较低。适用于增删改查所有场景。
二、分述
ArrayList:
- ArrayList底层实现是基于数组的,因此对指定下表的查找和修改比较快,但是删除和插入的操作比较慢。
- 继承自AbstractList,实现了List接口。
- 允许 null 的存在,同时还实现了 RandomAccess、Cloneable、Serializable 接口,所以ArrayList 是支持快速访问、复制、序列化的。
- 构造ArrayList时尽量指定容量,减少扩容时带来的数组赋值操作,如果不知道大小可以赋值其默认容量,如果没有指定默认容量,其默认容量为10。
- 每次添加元素之前都会检查是否需要扩容,每次扩容都是增加到原有容量的一般。(扩容时创建一个新的数组,并将原来的数组元素迁移到新数组中)
- ArrayList的所有方法第一没有进行同步,因此它不是线程安全的。
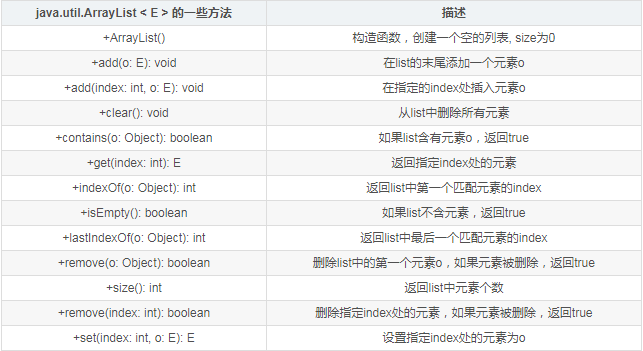
贴一个简单的案例:
1 import java.util.ArrayList; 2 public class TestArrayList { 3 public static void main(String[] args) { 4 // Create a list to store cities 5 ArrayList<String> cityList = new ArrayList<String>(); 6 7 // Add some cities in the list 8 cityList.add("London"); 9 // cityList now contains [London] 10 11 cityList.add("Denver"); 12 // cityList now contains [London, Denver] 13 14 cityList.add("Paris"); 15 // cityList now contains [London, Denver, Paris] 16 17 cityList.add("Miami"); 18 // cityList now contains [London, Denver, Paris, Miami] 19 20 cityList.add("Seoul"); 21 // Contains [London, Denver, Paris, Miami, Seoul] 22 23 cityList.add("Tokyo"); 24 // Contains [London, Denver, Paris, Miami, Seoul, Tokyo] 25 26 System.out.println("List size? " + cityList.size()); // 6 27 System.out.println("Is Miami in the list? " + cityList.contains("Miami")); // true 28 System.out.println("The location of Denver in the list? " + cityList.indexOf("Denver")); // 1 返回索引,如果不在list中,返回-1 29 System.out.println("Is the list empty? " + cityList.isEmpty()); // Print false 30 31 // Insert a new city at index 2 32 cityList.add(2, "Xian"); 33 // Contains [London, Denver, Xian, Paris, Miami, Seoul, Tokyo] 34 35 // Remove a city from the list 36 cityList.remove("Miami"); 37 // Contains [London, Denver, Xian, Paris, Seoul, Tokyo] 38 39 // Remove a city at index 1 40 cityList.remove(1); 41 // Contains [London, Xian, Paris, Seoul, Tokyo] 42 43 // Display the contents in the list 44 System.out.println(cityList.toString()); 45 46 // Display the contents in the list in reverse order 47 for (int i = cityList.size() - 1; i >= 0; i--) 48 System.out.print(cityList.get(i) + " "); 49 System.out.println(); 50 51 // Create a list to store two circles 52 ArrayList<CircleFromSimpleGeometricObject> list = new ArrayList<CircleFromSimpleGeometricObject>(); 53 54 // Add two circles 55 list.add(new CircleFromSimpleGeometricObject(2)); 56 list.add(new CircleFromSimpleGeometricObject(3)); 57 58 // Display the area of the first circle in the list 59 System.out.println("The area of the circle? " + list.get(0).getArea()); 60 } 61 }
LinkedList:
- LinkedList是基于双向链表实现的,不论是增删改查方法还是队列和栈的实现,都可通过操作节点实现。
- LinkedList无需提前指定容量,因为基于链表操作,集合的容量随着元素的加入自动增加(无序执行默认长度,也没有扩容需求)
- LinkedList删除元素后集合占用的内存自动缩小,无需像ArrayList一样调用trinToSize()方法
- LinkedList的所有方法没有进行同步,因此它也不是线程安全的,应该避免在多线程环境下使用。
- LinkedList根据index查询时采取的是二分法,即index小于总长度一半时从链表头开始往后查找,大于总长度一半时从链表尾往前查找。如果是根据元素查找,则需要从头开始遍历
LinkedList中的属性:
1 //链表的节点个数 2 transient int size = 0; 3 //指向头节点的指针 4 transient Node<E> first; 5 //指向尾节点的指针 6 transient Node<E> last;
Node节点结构
1 private static class Node<E> { 2 E item; 3 Node<E> next; 4 Node<E> prev; 5 Node(Node<E> prev, E element, Node<E> next) { 6 this.item = element; 7 this.next = next; 8 this.prev = prev; 9 } 10 }
HashMap:
- 哈希表是由数组和单向链表共同构成的一种结构,上图中一个数组元素链表存在多个元素,说明存在hash冲突,理想情况下每个数组元素之应包含一个元素
- 扩容原因:HashMap默认的初始容量为16,默认的加载因子是0.75。而threshold是集合能够存储的键值对的阀值,默认是初始容量*加载因子,也就是16*0.75=12,当键值对要超过阀值时,意味着这时候的哈希表已处于饱和状态,再继续添加元素就会增加哈希冲突,从而使HashMap的性能下降。
- 每次扩容都是增加原有容量的一倍。(扩容是创建一个新的数组,并将原来的数组元素迁移到新数组中,根据hash值重新分配)
- hash值的计算方式(字符串是单独的计算方式,扰动函数就是把所有东西杂糅到一起,提高随机性)
1 //生成hash码的函数 2 final int hash(Object k) { 3 int h = hashSeed; 4 //key是String类型的就使用另外的哈希算法 5 if (0 != h && k instanceof String) { 6 return sun.misc.Hashing.stringHash32((String) k); 7 } 8 h ^= k.hashCode(); 9 //扰动函数 10 h ^= (h >>> 20) ^ (h >>> 12); 11 return h ^ (h >>> 7) ^ (h >>> 4); 12 }
而还有与HashMap相似但又很容易混淆的HashTable和ConcurrentHasgMap在我的另一篇博客中有介绍到。
三、总结
概述中已经描述各个集合的适用场景,这里重点说一下HashMap。HashMap可以通过hash值快速定位到数组下标,执行新增、修改、删除操作。当hash算法较好(hash冲突较少)时,增删改查的时间复杂度都是O(1)。但是如果链表较长,则会增加增删改查的时间复杂度O(链表长度)。原则就是尽量减少hash冲突,并预先估算hashmap长度,减少扩容操作。