YOLOv3和YOLOv4长篇核心综述(下)
4.3.3 Neck创新
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。
(1)SPP模块
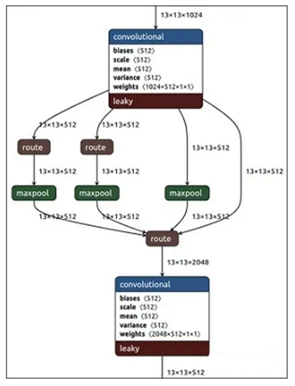
SPP模块,其实在Yolov3中已经存在了,在Yolov4的C++代码文件夹中有一个Yolov3_spp版本,但有的同学估计从来没有使用过,在Yolov4中,SPP模块仍然是在Backbone主干网络之后:
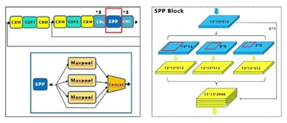
作者在SPP模块中,使用k={1*1,5*5,9*9,13*13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。
在2019提出的《DC-SPP-Yolo》文章:https://arxiv.org/ftp/arxiv/papers/1903/1903.08589.pdf
也对Yolo目标检测的SPP模块进行了对比测试。
和Yolov4作者的研究相同,采用SPP模块的方式,比单纯的使用k*k最大池化的方式,更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征。
Yolov4的作者在使用608*608大小的图像进行测试时发现,在COCO目标检测任务中,以0.5%的额外计算代价将AP50增加了2.7%,因此Yolov4中也采用了SPP模块。
(2)FPN+PAN
PAN结构比较有意思,看了网上Yolov4关于这个部分的讲解,大多都是讲的比较笼统的,而PAN是借鉴图像分割领域PANet的创新点,有些同学可能不是很清楚。
下面大白将这个部分拆解开来,看下Yolov4中是如何设计的。
Yolov3结构:
先来看下Yolov3中Neck的FPN结构
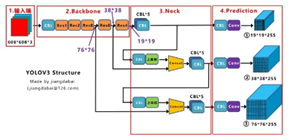
可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76*76、38*38、19*19。
以及最后的Prediction中用于预测的三个特征图①19*19*255、②38*38*255、③76*76*255。[注:255表示80类别(1+4+80)×3=255]
将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。
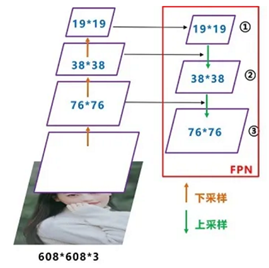
如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。
Yolov4结构:
而Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:

前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是3*3大小,相当于下采样操作。
因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。
以及最后Prediction中用于预测的三个特征图:①76*76*255,②38*38*255,③19*19*255。
也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中包含两个PAN结构。
这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
不过这里需要注意几点:
注意一:
Yolov3的FPN层输出的三个大小不一的特征图①②③直接进行预测
但Yolov4的FPN层,只使用最后的一个76*76特征图①,而经过两次PAN结构,输出预测的特征图②和③。
这里的不同也体现在cfg文件中,这一点有很多同学之前不太明白,
比如Yolov3.cfg最后的三个Yolo层,
第一个Yolo层是最小的特征图19*19,mask=6,7,8,对应最大的anchor box。
第二个Yolo层是中等的特征图38*38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最大的特征图76*76,mask=0,1,2,对应最小的anchor box。
而Yolov4.cfg则恰恰相反
第一个Yolo层是最大的特征图76*76,mask=0,1,2,对应最小的anchor box。
第二个Yolo层是中等的特征图38*38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最小的特征图19*19,mask=6,7,8,对应最大的anchor box。
注意点二:
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用**concat(route)**操作,特征图融合后的尺寸发生了变化。
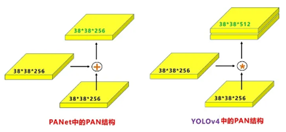
这里也可以对应Yolov4的netron网络图查看,很有意思。
4.3.4 Prediction创新
(1)CIOU_loss
目标检测任务的损失函数一般由**Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)**两部分构成。
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。
a.IOU_Loss
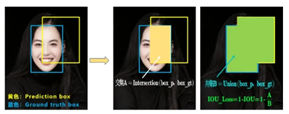
可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。

问题1: 即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2: 即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
因此2019年出现了GIOU_Loss来进行改进。
b.GIOU_Loss
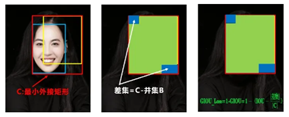
可以看到右图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。
但为什么仅仅说缓解呢?
因为还存在一种不足:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
基于这个问题,2020年的AAAI又提出了DIOU_Loss。
c.DIOU_Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
一:如何最小化预测框和目标框之间的归一化距离?
二:如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)

DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。
但就像前面好的目标框回归函数所说的,没有考虑到长宽比。

比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。
但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
针对这个问题,又提出了CIOU_Loss,不对不说,科学总是在解决问题中,不断进步!!
d.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
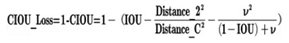
其中v是衡量长宽比一致性的参数,也可以定义为:
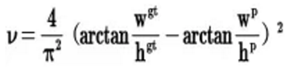
这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
再来综合的看下各个Loss函数的不同点:
IOU_Loss: 主要考虑检测框和目标框重叠面积。
GIOU_Loss: 在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss: 在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss: 在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
(2)DIOU_nms
Nms主要用于预测框的筛选,常用的目标检测算法中,一般采用普通的nms的方式,Yolov4则借鉴上面D/CIOU loss的论文:https://arxiv.org/pdf/1911.08287.pdf
将其中计算IOU的部分替换成DIOU的方式:
再来看下实际的案例

在上图重叠的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,也可以回归出来。
因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
注意:有读者会有疑问,这里为什么不用CIOU_nms,而用DIOU_nms?
答: 因为前面讲到的CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含groundtruth标注框的信息,在训练时用于回归。
但在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
总体来说, YOLOv4的论文称的上良心之作,将近几年关于深度学习领域最新研究的tricks移植到Yolov4中做验证测试,将Yolov3的精度提高了不少。
虽然没有全新的创新,但很多改进之处都值得借鉴,借用Yolov4作者的总结。
Yolov4 主要带来了 3 点新贡献:
(1)提出了一种高效而强大的目标检测模型,使用 1080Ti 或 2080Ti 就能训练出超快、准确的目标检测器。
(2)在检测器训练过程中,验证了最先进的一些研究成果对目标检测器的影响。
(3)改进了 SOTA 方法,使其更有效、更适合单 GPU 训练。
5.YoloV4相关代码
5.1 python代码
代码地址:https://github.com/Tianxiaomo/pytorch-Yolov4
作者的训练和测试推理代码都已经完成
5.2 C++代码
Yolov4作者Alexey的代码,俄罗斯的大神,应该是个独立研究员,更新算法的频繁程度令人佩服。
在Yolov3作者Joseph Redmon宣布停止更新Yolo算法之后,Alexey凭借对于Yolov3算法的不断探索研究,赢得了Yolov3作者的认可,发布了Yolov4。
代码地址:https://github.com/AlexeyAB/darknet
5.3 python版本的Tensorrt代码
目前测试有效的有tensorflow版本:weights->pb->trt
代码地址:https://github.com/hunglc007/tensorflow-Yolov4-tflite
5.4 C++版本的Tensorrtrt代码
代码地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov4
作者自定义了mish激活函数的plugin层,Tensorrt加速后速度还是挺快的。
6.相关数据集下载
项目中,目标检测算法应该的非常多非常多,比如人脸识别,比如疫情期间的口罩人脸识别,比如车流统计,人流统计等等。
因此大白也会将不错的值得一试的目标检测数据集汇总到此处,方便需要的同学进行下载。
6.1 口罩遮挡人脸数据集
数据集详情: 由武汉大学多媒体研究中心发起,目前是全球最大的口罩遮挡人脸数据集。
分为真实口罩人脸和模拟口罩人脸两部分,真实口罩人脸包含525人的5000张口罩人脸和9万张正常人脸。模拟口罩人脸包含1万个人共50万张模拟人脸数据集。
应用项目: 人脸检测、人脸识别
数据集地址:https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
6.2 Wider Face人脸数据集
数据集详情:香港中文大学发起的,包含3万张图片共40万张人脸。
应用项目:人脸检测
数据集地址:http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html
6.3 Wider Person拥挤场景行人数据集
数据集详情:多种场景比较拥挤场景的行人检测数据集,包含13382张图片,共计40万个不同遮挡程度的人体。
应用项目:人体检测
数据集地址:http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/
因为工作原因,会搜集大量的各类公开应用场景数据集,如果有同学需要其他场景或者其他项目的,也可以留言,或者发送邮件到jiangdabai@126.com,也会将对应的数据集更新到此处。
7.不断更新ing
在深度学习的图像领域,肯定会涉及目标检测,而在目标检测中,Yolov3是非常经典,必须要学习的算法,有些同学,特别新接触的同学,刚学习时会觉得yolo算法很繁琐。
但发现,网上很多的教程其实讲的还是比较笼统,并不适合学习。
所以大白也在耗尽洪荒之力,在准备Yolov3和Yolov4及相关的基础入门视频,让大家看完就能明白整体的流程和各种算法细节,大家可以先收藏,后期制作好后会更新到此处。