CVPR2020:三维点云无监督表示学习的全局局部双向推理
Global-Local Bidirectional Reasoning for Unsupervised Representation Learning of 3D Point Clouds
论文地址:
摘要
局部模式和全局模式密切相关。虽然对象的每个部分都是不完整的,但是对象的底层属性在所有部分之间是共享的,这使得从单个部分推理整个对象成为可能。假设,一个强大的三维物体的表现应该建模的属性之间的部分和整个对象,并区别于其对象。基于这个假设,提出在没有人工监督的情况下,通过在不同抽象层次的局部结构和全局形状之间进行双向推理来学习点云表示。在不同基准数据集上的实验结果表明,无监督学习表示在识别能力、泛化能力和鲁棒性等方面优于有监督表示。证明了无监督训练的点云模型在下游分类任务上的表现优于有监督的点云模型。最值得注意的是,通过简单地增加SSG PointNet++的通道宽度,无监督模型在合成和真实世界的3D对象分类数据集上都优于最先进的监督方法。期望观察能够为从数据结构中学习更好的表示提供一个新的视角,而不是使用人工注释来理解点云。
1.介绍
促进机器理解三维世界对于许多重要的现实世界应用至关重要,例如自主驾驶、增强现实和机器人技术。三维几何数据(如点云)的一个核心问题是学习具有区分性、通用性和鲁棒性的强大表示。为了解决这一问题,本文借助于大量的人工注释监督信息,建立了点云分析的最新进展[2,26,28,33,38,43,49,51,54]。
然而,人工标注的数据需要耗费大量的人力,这可能会限制学习模型的泛化能力。因此,无监督学习是一个有吸引力的方向,以获得通用和鲁棒的三维物体理解表示。从未标记的数据中学习有用的表示是点云分析的一个基本且具有挑战性的问题。虽然人已经致力于学习无人工监督的点云表示[1,8,14,18,26,31,47,55,56],但这些方法主要基于生成或重构任务提供的自监督信号,包括自重构[1,8,14,26,47,55,56],局部到全局重构[18,31]和分布估计[1,26]。这些方法在获取点云的结构信息和低层信息方面是有效的,但通常无法从点云中获取高层语义信息。因此,无监督模型的性能仍然远远落后于最先进的有监督模型。本文的目的是探索一种既能学习结构信息又能学习语义知识的无监督学习算法,以提高无监督学习表征的质量。
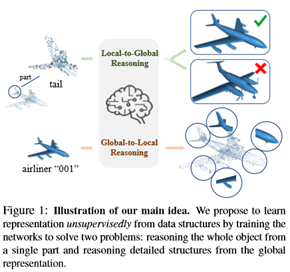
不同于图像中局部区域的噪声很大,并且通常独立于整个图像(例如,给定一个狗的斑块,无法识别该图像是关于动物还是附近的人),3D对象的所有部分都共享潜在的语义和结构信息。三维物体的这一独特特性使得从一个单独的部分来推理整个物体成为可能。基于这一观察结果,假设一个强大的三维物体的表现应该对部分和整个物体之间共享的、与其物体不同的潜在属性进行建模。如图1所示,给定一架飞机尾部的点云,良好的尾部表示应该反映出相应飞机的类型。同时,整个飞机的表现应该包含所有必要的细节来推断这架飞机的局部结构。
本文提出了一种新的无监督点云表示学习方案,该方案通过网络中不同抽象层次的局部表示和三维对象的全局表示进行双向推理。方法简单而有效,可以广泛应用于点云理解的深度学习方法。现有的无监督学习方法主要是通过学习不同的自动编码器来获取结构信息,而方法是在三维点云中获取局部结构和全局形状之间共享的语义知识。具体来说,所提出的全局局部推理(GLR)包括两个子任务:1)局部到全局推理:将局部局部和全局形状之间的共享属性捕获问题描述为一个自监督度量学习问题,其中,鼓励局部特征比其对象的特征更接近于同一对象的全局特征,从而可以通过局部表示来提取每个对象的不同语义信息;2)全局局部推理:进一步使用包括自重构和正态估计在内的自监督任务来实现了解包含三维对象的必要结构信息的全局要素。在几个基准数据集上的实验结果表明,在下游对象分类任务中,
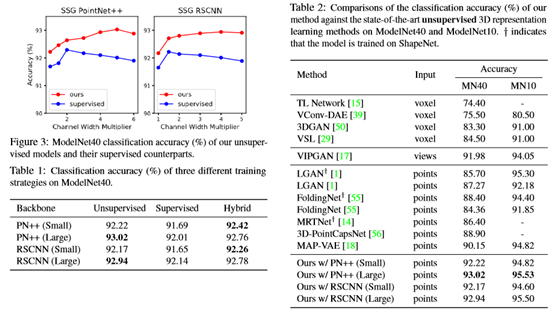
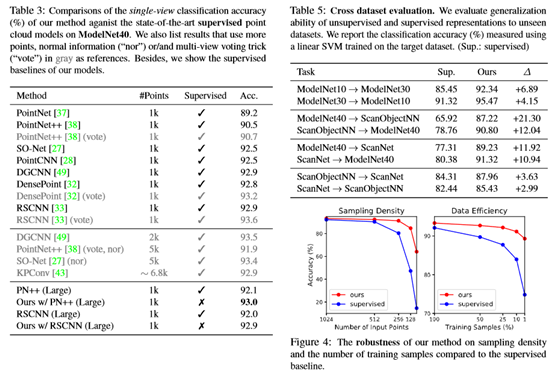
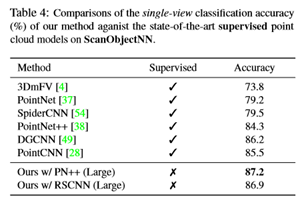
无监督学习的点云表示比监督表示更具鉴别性、通用性和鲁棒性。无监督训练模型可以持续优于监督对手。利用无监督学习方法,展示了一个简单而轻量级的SSG PointNet++[38]模型可以通过有监督的方法获得非常有竞争力的结果(在ModelNet40[52]上分类准确率为92.2%)。通过简单地增加通道宽度,在ModelNet40和ScanObjectNN[46]基准上分别获得93.0%和87.2%的单视图精度,超过了最先进的无监督和有监督方法,而该模型的监督版本则存在过度拟合的问题。
2.相关工作
3D点云深度学习:
近年来,三维点云分析的快速发展得益于直接使用三维点云的深度学习技术[28,33,37,38,49]。PointNet[26]开创了这一系列的工作,并设计了一个深度网络,通过独立学习每个点并使用最大池融合点特性,可以处理无序和非结构化的三维点。虽然很有效,但PointNet无法捕获本地结构,这已被证明是CNNs成功的关键。PointNet++[38]通过开发一个分层的分组体系结构,在不同的抽象层次上逐步提取局部特征,从而缓解了这一问题。随后的工作,如PointCNN[28]、PointConv[51]和关系形状CNN[33]等,也关注点云的局部结构,进一步提高了捕捉特征的质量。由于只需要局部和全局特征之间的关系,方法适用于所有这些PointNet++变量。虽然最近的作品通过提升网络的能力推动了点云深度学习的最新水平,但这项工作提供了一种新的途径,可以在无监督的方式下学习强大的表示,而无需任何人工注释。

无监督表征学习:
自最早的[13]以来,无监督学习一直是计算机视觉中的一组重要方法,其目的是学习数据的转换,从而使后续的下游问题求解更容易[5]。用于无监督学习的经典deep方法,如自动编码器[21]、生成性对抗性网络[16]和自回归模型[35]通过忠实地重建输入数据来学习表示,这些输入数据集中在数据的低级变化上,对于分类等下游任务不是很有用。近年来关于自监督学习的研究提出了一个强大的模型家族,可以学习具有丰富语义知识的区分表示。这组方法设计了各种问题生成器,使得模型需要从数据中学习有用的信息,以便解决这些生成的问题[3,10,11,19,44]。在本文中,也遵循这一思路,提出通过解决全局-局部双向推理问题来学习点云表示。
在没有人工监督的情况下学习点云的表示法已有几次尝试[1,8,14,18,26,31,47,55,56]。这些方法通过数据重建来发现三维点云中有用的信息,这对于学习结构信息是有效的。然而,由于缺乏有效的语义监督,以往的方法限制了网络在下游任务中的能力。方法通过将语义监督与结构监督相结合来解决这个问题。通过对高层语义知识的挖掘,方法能够学习像有监督方法一样的区别表示,同时保持无监督表示的鲁棒性和泛化性。
3. Approach
三维点云理解的核心是学习区分性、通用性和鲁棒性的表示,这些表示可以捕捉底层形状。为了在无监督的情况下实现这一目标,提出通过解决局部结构和全局形状之间的双向推理问题来实现点云表示。方法的总体框架如图2所示。
分层点云特征学习
首先回顾PointNet++[38]中提出的层次化点云特征学习框架,方法就是基于这个框架构建的。
几乎所有以前关于有监督点云学习的著作[2,26,28,33,38,43,49,51,54]都采用了端到端的训练范式,直接从标注的标签中学习表示。这些方法虽然取得了很好的效果,但忽略了点云本身所包含的语义和结构信息。在这项工作中,致力于探索点云的这一特性,并为点云表示学习提供一个非常有竞争力的替代方案。为了从没有人工标注的数据中发现结构和语义信息,提出了两个网络需要解决的问题:局部到全局的推理和全局到局部的推理,其目的分别是无监督地学习语义和结构知识。
局部到全局推理
即使只有一小部分物体被呈现出来,人类也能辨认出许多物体。这一事实启发利用局部部分和全局形状之间的关系作为一个自由而丰富的监督信号,来训练一个丰富的点云理解表示。因此,局部到全局推理的目标是挖掘点云不同抽象层次之间的共享语义知识。由于全局表示通常比局部表示能更好地捕捉三维对象的语义信息,因此局部到目标推理通过从局部表示中预测全局表示来实现。为了评估预测,将预测描述为一个自监督度量学习问题,并使用多类N对损失来监督预测任务。受实例判别的启发[53],为了学习每个对象的不同语义信息,将当前对象的全局表示作为正样本,将其对象的全局表示作为负样本。
全局到局部推理
由于从未标记的数据中发现有助于下游任务的知识通常是相当困难的,局部到全局的推理不一定会导致有用的表示。对互信息最大化方法的研究也指出了这一事实[44,45],其中证据表明,较大的互信息可能不能保证下游任务有更好的性能[45]。直觉上,由于局部到全局推理只监督局部表示接近全局表示,因此全局表示的质量至关重要。这就是说,如果全局代表性的启动良好,将对地方代表性进行适当的监督,从而为学习本地和全局特征创造一个良性循环。相反,由于全局表示的初始状态不好,学习过程可能会得到不可预测的结果。为了避免这个问题,提出了一个辅助的全局到局部推理任务来监督网络以共同学习有用的表示。具体来说,使用两个低层生成任务,包括自重构和正态估计作为两个自监督信号,这样全局表示需要捕获点云的基本结构信息。
4. Experiments
对几种广泛使用的点云分类基准数据集(包括ModelNet10/40[52]、ScanObjectNN[46]和ScanNet[7]等)进行了广泛的评估。首先,评估了方法在数据集上的识别能力、泛化能力和鲁棒性,并与最新的无监督和有监督方法进行了比较。然后提供了详细的实验来分析方法在模型设计和复杂度上的差异。最后,将学习到的表示可视化,以便对方法有一个直观的理解。下面详细介绍了实验、结果和分析。