CVPR2020:点云分类的自动放大框架PointAugment
PointAugment: An Auto-Augmentation Framework for Point Cloud Classification
论文地址:
code:https://github.com/liruihui/PointAugment
摘要
本文提出了一种新的自动放大框架PointAugment,在训练分类网络时,自动优化和放大点云样本,以丰富数据的多样性。与现有的二维图像自动放大方法不同,PointAugment是一种样本感知的方法,采用一种对抗性学习策略来联合优化放大器网络和分类器网络,使放大器能够学习产生最适合分类器的放大样本。此外,构造了一个带形状变换和点位移的可学习点放大函数,并根据分类器的学习进度,精心设计损失函数来采用放大样本。大量实验也证实了PointAugment的有效性和鲁棒性,可以改善各种网络的形状分类和检索性能。
1.介绍
近24年来,人对三维神经网络的研究兴趣与日俱增。可靠地训练网络通常依赖于数据的可用性和多样性。然而,与ImageNet[10]和MS-COCO数据集[15]等二维图像基准测试不同,3D数据集的数量通常要小得多,标签数量相对较少,多样性有限。例如,ModelNet40[38]是3D点云分类最常用的基准之一,只有40个类别的12311个模型。有限的数据量和多样性可能导致过拟合问题,进而影响网络的泛化能力。目前,数据放大(DA)是一种非常普遍的策略,通过人工增加训练样本的数量和多样性来避免过度拟合,提高网络泛化能力。对于三维点云,由于训练样本数量有限,且在3D中有巨大的放大空间,传统的DA策略[23,24]通常只是在一个小的、固定的预先定义的放大范围内随机扰动输入点云,以保持类标签。
尽管这种传统的DA方法对现有的分类网络有效,但可能导致训练不足,如下所述。首先,现有的深部三维点云处理方法将网络训练和数据采集视为两个独立的阶段,没有联合优化,例如反馈训练结果以放大DA。因此,训练后的网络可能是次优的。其次,现有方法对所有输入点云样本应用相同的固定放大过程,包括旋转、缩放和/或抖动。在放大过程中忽略了样本的形状复杂度,例如,球体无论如何旋转都保持不变,但复杂形状可能需要更大的旋转。因此,传统的DA对于增加训练样本可能是多余的或不充分的[6]。
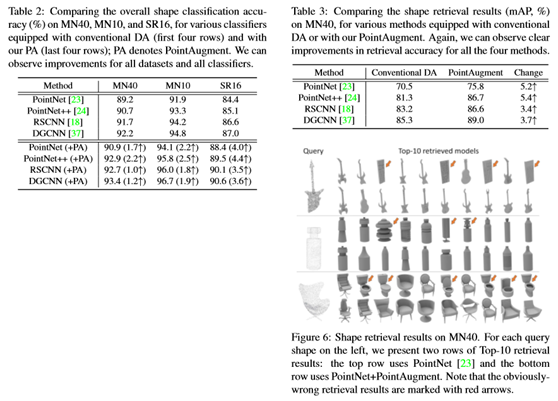
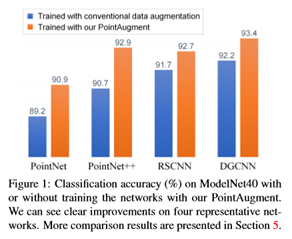
为了改进点云样本的放大,提出了一种新的三维点云自动放大框架PointAugment,并展示了其放大形状分类的有效性;见图1。与以前的二维图像不同,PointAugment学习生成特定于单个样本的放大函数。此外,可学习的放大函数同时考虑了形状变换和点方向位移,这与三维点云样本的特征有关。此外,PointAugment通过一种对抗性学习策略,将放大网络(augmentor)与分类网络(Classifier)进行端到端的训练,从而与网络训练共同优化放大过程。通过将分类损失作为反馈,放大器可以学习通过扩大类内数据变化来丰富输入样本,而分类器可以学习通过提取不敏感特征来克服这一问题。受益于这种对抗性学习,放大器可以学习生成在不同训练阶段最适合分类者的放大样本,从而最大限度地提高分类者的能力。作为探索3D点云自动放大的第一次尝试,展示了通过用PointAugment取代传统的DA,可以在四个具有代表性的网络上实现对ModelNet40[38](见图1)和SHREC16[28](见第5节)数据集的形状分类的明显改进,包括PointNet[23]、PointNet++[24],RSCNN[18]和DGCNN[37]。此外,还展示了PointAugment在形状检索上的有效性,并评估了其鲁棒性、损失配置和模块化设计。
2.相关工作
图像数据放大
训练数据对深层神经网络学习执行任务起着非常重要的作用。然而,与现实世界的复杂性相比,训练数据的数量往往是有限的,因此经常需要数据放大来放大训练集,最大限度地利用训练数据学习到的知识。一些工作没有随机变换训练数据样本[42,41],而是尝试利用图像组合[12]、生成对抗网络[31,27]、贝叶斯优化[35]和潜在空间中的图像插值[4,16,2]从原始数据中生成放大样本。然而,这些方法可能产生与原始数据不同的不可靠样本。另一方面,一些图像DA技术[12,42,41]对具有规则结构的图像应用像素插值,但是不能处理顺序不变的点云。另一种方法的目的是找到一个预先定义的转换函数的最佳组合,以增加训练样本,而不是基于人工设计或完全随机性应用转换函数。
AutoAugment[3]提出了一种强化学习策略,通过交替训练代理任务和策略控制器,然后将学习到的放大函数应用于输入数据,从而找到最佳的放大函数集。不久之后,另两项研究,FastAugment[14]和PBA[8]探索了先进的超参数优化方法,以更有效地找到放大的最佳转换。与这些学习为所有训练样本找到固定的放大策略的方法不同,PointAugment是样本感知的,这意味着在训练过程中根据单个训练样本的属性和网络能力动态生成转换函数。最近,Tang等人[33]张等[43]建议学习使用对抗策略的目标任务的放大策略。倾向于直接最大化增加样本的损失,以提高图像分类网络的泛化能力。与之不同的是,PointAugment通过一个明确设计的边界扩大了放大后的点云与原始点云之间的损失;动态地调整了放大样本的难度,以便放大的样本能够更好地满足不同训练阶段的分类要求。
点云数据放大
在现有的点处理网络中,数据放大主要包括围绕重力轴的随机旋转、随机缩放和随机抖动[23,24]。这些手工制定的规则在整个训练过程中都是固定的,因此可能无法获得最佳样本来有效地训练网络。到目前为止,还没有发现有任何研究利用三维点云来实现网络学习最大化的工作。
点云深度学习
在PointNet架构[23]的基础上,有几篇文章[24,17,18]探索了局部结构来放大特征学习。另一些人通过创建局部图[36,37,29,45]或几何元素[11,22]来探索图形卷积网络。另一个工作流程[32,34,19]将不规则点投影到规则空间中,以允许传统的卷积神经网络工作。与上述工作不同,目标不是设计一个新的网络,而是通过有效地优化点云样本的增加来提高现有网络的分类性能。为此,设计了一个放大器来学习一个特殊的放大函数,并根据分类器的学习进度调整放大函数。
3. Overview
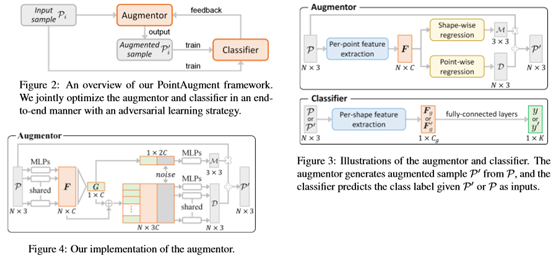
这项工作的主要贡献是PointAugment框架,该框架自动优化输入点云样本的放大,以便更有效地训练分类网络。图2说明了框架的设计,有两个深层神经网络组件:(i)一个放大器A和(ii)一个分类器C。
在阐述PointAugment框架之前,首先讨论框架背后的关键思想。这些都是新的想法(在以前的作品[3,14,8]中没有出现),使能够有效地增加训练样本,这些样本现在是三维点云,而不是二维图像。
•样本感知。目标是通过考虑样本的基本几何结构,为每个输入样本回归一个特定的放大函数,而不是为每个输入数据样本找到一套通用的放大策略或过程。称之为样本感知的自动放大。
•2D与3D放大。与二维图像放大不同,三维放大涉及更广阔和不同的空间域。应该考虑云的两种变形点(包括点云的变换和点云的变换)的放大(包括点云的变换和点云的变换)。
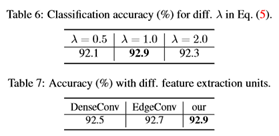
•联合优化。在网络训练过程中,分类器将逐渐学习并变得更加强大,因此需要更具挑战性的放大样本,以便更好地训练分类器,因为分类器变得更强。因此,以端到端的方式设计和训练PointAugment框架,这样就可以共同优化放大器和分类器。为此,必须仔细设计损失函数,动态调整增加样本的难度,同时考虑输入样本和分类器的容量。
4. Method
在本节中,首先介绍放大器和分类器的网络架构细节。然后,提出了为放大器和分类器制定的损失函数,并介绍了端到端训练策略。最后,给出了实现细节。
4.1. Network Architecture
放大器。不同于现有的工作[3,14,8],放大器是样本感知的,学习生成一个特定的函数来放大每个输入样本。从现在起,为了便于阅读,去掉了下标i,并将P表示为A的训练样本输入,P′表示A的相应放大样本输出。放大器的总体架构如图3(上图)所示。
4.2. Augmentor loss
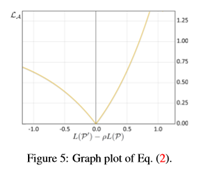
为了使网络学习最大化,由放大器生成的放大样本P′应满足两个要求:(i)P′比P更具挑战性,即目标是L(P′)≥L(P);(ii)P′不应失去形状特异性,这意味着应该描述一个与P不太远(或不同)的形状。为了达到要求(i),一个简单的方法来描述放大器(表示为LA)的损失函数是使P和P′上的交叉熵损失之差最大化,或者等效地最小化。
4.3. Classifier loss
分类C的目标是正确预测P和P′。另外,无论输入P或P′,C都应该具有学习稳定的每形状全局特征的能力。
4.4. End-to-end training strategy
算法1总结了端到端训练策略。总的来说,在训练过程中,该程序交替地优化和更新放大器A和分类器C中的可学习参数,同时调整另一个参数。
4.5. Implementation details
使用PyTorch[21]实现PointAugment。具体来说,将训练阶段的数量设为S=250,批量大小为B=24。为了训练放大器,采用了学习率为0.001的Adam优化器。为了训练分类人员,遵循发布的代码和文件中各自的原始配置。具体来说,对于PointNet[23]、PointNet++[24]和RSCNN[18],使用的Adam优化器的初始学习率为0.001,该值逐渐降低,每20个时期衰减率为0.5。
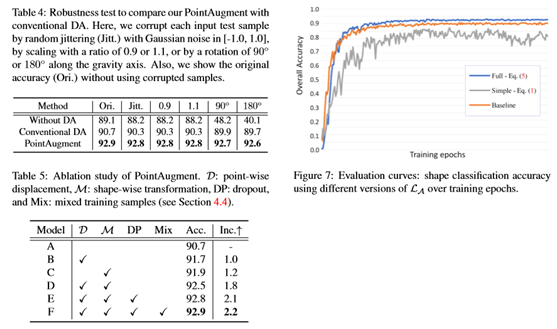
对于DGCNN[37],使用动量为0.9、基本学习率为0.1的SGD解算器,该解算器使用余弦退火策略衰减[9]。还需要注意的是,为了减少模型振荡[5],遵循[31]使用混合训练样本来训练点放大,混合训练样本包含一半原始训练样本,另一半包含先前放大的样本,而不是只使用原始训练样本。详见[31]。此外,为了避免过度拟合,设置了0.5的脱落概率来随机丢弃或保持回归的形状方向变换和点方向位移。在测试阶段,遵循之前的网络[23,24],将输入的测试样本输入到经过训练的分类器,以获得预测的标签,而不需要任何额外的计算成本。

5. Experiments
在点放大上做了大量的实验。首先,介绍了实验中使用的基准数据集和分类器。然后,在形状分类和形状检索方面评估PointAugment。接下来,将对PointAugment的健壮性、损耗配置和模块化设计进行详细分析。最后,提出进一步的讨论和未来可能的扩展。