MLIR中间表示与编译
概述
目前深度模型的推理引擎按照实现方式大体分为两类:
解
解释型推理引擎:
- 一般包含模型解析器,模型解释器,模型优化器。
- 模型解析器负责读取和解析模型文件,转换为适用于解释器处理的内存格式;
- 模型优化器负责将原始模型变换为等价的、但具有更快的推理速度的模型;
- 模型解释器分析内存格式的模型并接受模型的输入数据,然后根据模型的结构依次执行相应的模型内部的算子,最后产生模型的输出。
编译型推理引擎:
- 一般包含模型解析器和模型编译器。模型解析器的作用与解释型推理引擎相同;
- 模型编译器负责将模型编译为计算设备(CPU、GPU 等)可直接处理的机器码,并且可能在编译的过程中应用各种优化方法来提高生成的机器码的效率。
- 由于机器码的模型可以直接被计算设备处理,无需额外的解释器的参与,其消除了解释器调度的开销。
- 相对于解释型推理引擎,由于生成机器码的过程更加靠底层,编译器有更多的优化机会以达到更高的执行效率。
由于现在业界对于推理引擎的执行速度有了更高的需求,编译型推理引擎也逐渐成为高速推理引擎的发展方向。编译型推理引擎有 Apache TVM、oneDNN、PlaidML、TensorFlow XLA、TensorFlow Runtime 等。
为了便于优化,一般来说推理引擎会把模型转换为中间表示,然后对中间表示进行优化和变换,最终生成目标模型(对于解释型推理引擎)或目标机器码(对于编译型推理引擎)。此外,除了深度学习领域,在很早以前编程语言领域就引入了中间表示来做优化和变换。而新的编程语言层出不穷,因此就出现了各种各样的中间表示:
不同的推理引擎或者编译器都会有自己的中间表示和优化方案,而每种中间表示和优化方案可能都需要从头实现,最终可能会导致软件的碎片化和重复的开发工作。
MLIR 简介
MLIR(Multi-Level Intermediate Representation)是一种新型的用于构建可复用和可扩展的编译器的框架。MLIR 旨在解决软件碎片化、改善异构硬件的编译、降低构建领域特定编译器的成本,以及帮助将现有的编译器连接到一起。
MLIR 旨在成为一种在统一的基础架构中,支持多种不同需求的混合中间表示,例如:
表示数据流图(例如在 TensorFlow 中)的能力,包括动态性状、用户可扩展的算子生态系统、TensorFlow 变量等。
在这些图中进行优化和变换(例如在 Grappler 中)。
适合优化的形式的机器学习算子内核的表示。
能够承载跨内核的高性能计算风格的循环优化(融合、循环交换、分块等),并能够变换数据的内存布局。
代码生成“下降”变换,例如 DMA 插入、显式缓存管理、内存分块,以及 1 维和 2 维寄存器架构的向量化。
表示目标特定算子的能力,例如加速器特定的高层算子。
在深度学习图中的做的量化和其它图变换。
MLIR 是一种支持硬件特定算子的通用中间表示。因此,对围绕 MLIR 的基础架构进行的任何投入(例如在编译器 pass 上的工作)都将产生良好的回报;许多目标都可以使用该基础架构,并从中受益。
尽管 MLIR 是一种强大的框架,也有一些非目标。MLIR 不试图去支持底层机器码生成算法(如寄存器分配和指令调度)。这些更适合于底层优化器(例如 LLVM)。此外,MLIR 也不意图成为最终用户写算子内核的源语言(类似于 CUDA 和 C++)。另一方面,MLIR 提供了用于表示此类领域特定语言并将其集成到生态系统中的支柱。
MLIR 在构建时受益于从构建其它中间表示(LLVM IR、XLA HLO 和 Swift SIL)的过程中获得的经验。MLIR 框架鼓励现存的最佳实践,例如:编写和维护中间表示规范、构建中间表示验证器、提供将 MLIR 文件转储和解析为文本的功能、使用 FileCheck 工具编写详尽的单元测试、以及以一组可以以新的方式组合的模块化库的形式构建基础框架。
其它的经验教训也已经整合到了设计中。例如,LLVM 有一个不明显的设计错误,其会阻止多线程编译器同时处理 LLVM 模块中的多个函数。MLIR 通过限制 SSA 作用域来减少使用-定义链,并用显式的符号引用代替跨函数引用来解决这些问题。
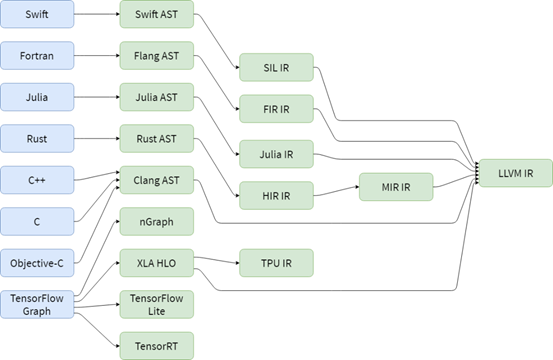
MLIR 方言(Dialect)
MLIR 通过“方言”来定义不同层次的中间表示,每一个方言都有自己唯一的名字空间。开发者可以创建自定义方言,并在方言内部定义算子、类型和属性,以及语义。MLIR 推荐使用方言来对 MLIR 进行扩展。有这样一个统一的中间表示框架,降低了开发新的编译器的成本。除了可以使用 C++ 语言,对方言进行定义之外,MLIR 也提供了一种声明式的方式来定义方言,即用户通过编写 TableGen 格式的文件来定义方言,然后使用 TableGen 工具来生成对应的 C++ 头文件和源文件,以及对应的文档。MLIR 也推荐使用这种声明式的的方式来定义方言。此外,MLIR 也提供了一个框架用于在方言之间或者方言内部进行转换。
为了方便开发,MLIR 也内置了一些方言可供直接使用:
acc
affine
async
avx512
gpu
linalg
llvm
nvvm
omp
pdl
pdl_interp
quant
rocdl
scf
shape
spv
std
vector
MLIR 使用“算子”来描述不同层次的抽象和计算。MLIR 中的算子也是可扩展的,用户可以创建自定义的算子并规定其语义。例如目标无关算子、仿射算子和目标特定算子。MLIR 也支持用户通过声明式的方式(TableGen)来创建自定义算子。
MLIR 中的每个值都有其对应的“类型”,MLIR 内置了一些原始类型(比如整数)和聚合类型(张量和内存缓冲区)。MLIR 的类型系统也允许用户对其进行扩展,创建自定义的类型以及规定其语义。
此外在 MLIR 中,用户可以通过指定算子的“属性”的值来控制算子的行为。算子可以定义自身的属性,比如卷积算子的 stride 属性等。
方言的变换
在 MLIR 中定义算子的时候可以定义其规范化的行为,比如将 x + 2 和 2 + x 统一规范化为 x + 2,以便后续的优化过程更为方便地进行。MLIR 以一种贪婪地策略,不断地应用规范化变换,直到中间表示收敛为止。
在 MLIR 中进行方言内部或方言之间的转换时,用户首先要定义一个转换目标。转换目标规定了生成的目标中可以出现哪些算子。然后用户需要指定一组重写模式,这些重写模式定义了算子之间的转换关系。最后框架根据用户指定的转换目标和重写模式执行转换。这个转换过程会自动检测转换方式,例如如果指定了 A → B 和 B → C 的重写模式,框架会自动完成 A → C 的转换过程。MLIR 也支持用户通过声明式的方式(TableGen),创建自定义的重写模式。当转换的方言之间有着不同的类型系统,用户可以使用类型转换器,完成类型之间的转换。
MLIR 的用户
ONNX MLIR:将 ONNX 格式的深度学习网络模型转换为能在不同二进制执行的二进制格式。
PlaidML:一个开源的张量编译器,允许在不同的硬件平台上运行深度学习模型。
TensorFlow:TensorFlow 项目的 XLA 和 TensorFlow Lite 模型转换器用到了 MLIR。
TensorFlow Runtime:一种新的 TensorFlow 运行时。
Verona:一种新的研究型的编程语言,用于探索并发所有权。其提供了一个可以与所有权无缝集成新的并发模型。
附录:编译和安装 MLIR
下载 MLIR
MLIR 是 LLVM 项目的子项目,要编译 MLIR,首先获取 LLVM 的源代码。
LLVM 的源码可从 GitHub 获取:
git clone https://github.com/llvm/llvm-project.git
用户也可以直接下载源码包:https://github.com/llvm/llvm-project/releases。
假定 LLVM 的源码目录为 $LLVM_SRC。
编译 MLIR
首先用户需要指定一个路径用于存放编译中间产物,假定其路径为 $LLVM_BUILD。然后使用下列命令对 LLVM 进行配置:
cmake -S "$LLVM_SRC" -B "$LLVM_BUILD" -DLLVM_ENABLE_PROJECTS=mlir -DCMAKE_BUILD_TYPE=Release
默认情况下,LLVM 禁用了异常处理和运行时类型信息。如果应用程序需要依赖这些功能,可指定在配置时指定 LLVM_ENABLE_EH 和 LLVM_ENABLE_RTTI CMake 变量的值为 ON:
cmake -S "$LLVM_SRC" -B "$LLVM_BUILD" -DLLVM_ENABLE_PROJECTS=mlir -DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_RTTI=ON -DCMAKE_BUILD_TYPE=Release
更多的 LLVM 配置参数参见 https://llvm.org/docs/CMake.html。
执行完配置过程后使用下列命令执行编译:
cmake --build "$LLVM_BUILD"
安装 MLIR
使用如下命令将 LLVM 安装到 /usr/local 目录:
cmake --install "$LLVM_BUILD"
如果想指定另外一个安装目录,例如 $INSTALL_DIR,可以使用 --prefix 命令行参数来指定:
cmake --install "$LLVM_BUILD" --prefix "$INSTALL_DIR"
在 CMake 项目中使用 MLIR
用户可以在 CMake 项目文件中使用下列语句添加查找 MLIR 依赖:
find_package(MLIR REQUIRED CONFIG)
如果 MLIR 被安装到了系统目录(比如 /、/usr、/usr/local 等),CMake 无需额外的配置就能找到 MLIR;如果 MLIR 被安装到了非系统目录,可以在 CMake 的配置过程通过 CMake 的 MLIR_DIR 变量来指定 MLIR 的安装位置:
cmake "$MY_PROJECT_DIR" -DMLIR_DIR="$INSTALL_DIR"
成功之后用户可以直接使用 MLIR 的库作为编译目标的依赖:
add_executable(my-executable main.cpp)
target_include_directories(my-executable SYSTEM PRIVATE ${MLIR_INCLUDE_DIRS})
target_link_libraries(my-executable PRIVATE MLIRIR)
其中 MLIR_INCLUDE_DIRS 是自动生成的变量,其指向 MLIR 的包含目录。
在使用 CMake 定义可执行文件目标时,如果 LLVM 禁用了运行时类型信息,那么依赖于 LLVM 的可执行文件目标也需要禁用运行时类型信息,否则可能会编译失败。LLVM 提供了一个 CMake 帮助函数 llvm_update_compile_flags 可以自动完成这个配置。这个函数定义在 LLVM 提供的 AddLLVM.cmake 文件中。用户可以使用下列语句导入 AddLLVM.cmake 文件:
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(AddLLVM)
导入 AddLLVM.cmake 文件后就可以对编译目标进行配置了:
llvm_update_compile_flags(my-executable)
完整的 CMake 项目文件示例如下:
cmake_minimum_required(VERSION 3.15)
project(my-executable)
find_package(MLIR REQUIRED CONFIG)
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(AddLLVM)
add_executable(my-executable main.cpp)
target_include_directories(my-executable SYSTEM PRIVATE ${MLIR_INCLUDE_DIRS})
target_link_libraries(my-executable PRIVATE MLIRIR)
llvm_update_compile_flags(my-executable)
结论
MLIR 是一种新型的编译器框架,设计从已有的编译器的实现中吸取了经验和教训,包括了中间表示的定义、转换以及优化等功能,极大地方便了新的编译器的开发和调试工作。同时,MLIR 也包含了很多现成的工具可直接使用(batteries included)。MLIR 包揽了编译器设计中的通用部分,使得编译器的开发人员,可以专注于核心的语义分析、中间表示的设计和变换,以此降低开发成本,提高开发效率和提高成品质量。
参考链接
MLIR 主页:https://mlir.llvm.org/。
MLIR 语言参考:https://mlir.llvm.org/docs/LangRef/。