个人博客网:https://wushaopei.github.io/ (你想要这里多有)
内容:
- 通用命令
- 单线程架构
- 数据结构和内部编码
一、常用的通用命令:
- keys 计算所有的键
- dbsize 获取redis的长度
- exists key 判断键的存在与否
- del key [key ...] 删除指定键的值
- expire key seconds 对key做定时操作
- type key
1、keys
1)用法1:

![]()
2)用法2:

![]()
说明: keys命令一般不在生产环境使用
2、dbsize:

![]()
3、exists:

![]()
4、del:

![]()
5、expire、ttl、persist

![]()
演示:

![]()
6、type:

![]()
7、命令的时间复杂度:

![]()
二、数据结构和内部编码
1、Redis的主要数据结构:

![]()
Redis的内部隐含结构体(对象): redis Object
2、该结构体包含以下数据类型及编码方式:

![]()
三、单线程

![]()
1、抽象理解Redis的单线程:
我们知道一个命令进入Redis执行的效率是很高的,在进入Redis之前可以认为它们在经过一条高速公路,如图中的黄色管道部分,而这条管道每一次都只能通过一个命令,多余的命令需要等待前面的命令执行完成后才能进入Redis中执行相应操作,也就是说,多个命令在操作Redis时是串行执行的。
2、单线程为什么这么快?
1)纯内存:
内存的响应速度是非常快的,内存的响应速度是100纳秒;也就是说Redis的速度高是依赖于内存的;
2)非阻塞IO

![]()
Redis中将equals和关闭、读写、连接转换为自己的一个事件,从而避免在网络IO上浪费过多的时间。
3)避免线程切换和竞态消耗
单线程equals模型

![]()
一瞬间只能执行一条命令
3、单线程:
1)一次只运行一条命令
2)拒绝长(慢)命令
Keys , flushall , flushdb , slow lua script , mutil / exec , operate big value ( collection )
3)其实不是单线程
fysnc file descriptor
close file descriptor
四、字符串
字符串:
- 结构和命令
- 快速实战
- 内部编码
- 查漏补缺
1、字符串键值结构
对于Redis来说,所有的key都是字符串,而它的value则是前面说过的五种类型。这里主要对Redis的value进行解析。当前的value为字符串类型
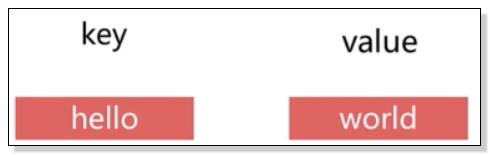
![]()
如上图,value是“world”,是一个字符串的类型

![]()
同样的,字符串的value也可以是一个数值类来表示

![]()
并且,字符串也可以做相应的转换,在字符串和整型间做转换,其原理类似于位图的使用。

![]()
① 字符串的value的表现形式也可以是以json的形式存在
② 字符串的value 最大限制为512MB的容量。
2、字符串的value的适用场景:
- 缓存;
- 计数器:例如:视频网站的视频的播放次数,每一次的播放会做加一的操作;
- 分布式锁;
- 等等。。。
3、字符串value的相关API操作:get、set、del、

![]()
其他的API的使用:Incr、decr、incrby、decrby:

![]()
4、演示:

![]()
5、实战
1)实战1:
实现如下功能:记录网站每个用户个人主页的访问量?
Incr userid : pageview (单线程:无竞争)当用户的userid为123时, 以 incr 123:pageview的形式来进行自增,由于单线程执行,每个key都是一次执行的,不存在并发的问题,每次有新的访问就会提交一次 incr 123:pageview 的请求,依次累加达到访问量的计数。
2)实战2:
实现如下功能:缓存视频的基本信息(数据源在MySQL中)伪代码
如图,用户通过视频的id去获取视频的信息,首先会从App Server发起请求,App Server 会先从redis查询是否有匹配视频id的视频信息,如果redis中存在了,就直接返回给App Server,这就减少了数据库MySQL的压力;如果不存在,就会直接访问MySQL,从MySQL查询到了视频信息,就会回写到redis中,并同时返回给App Server。
下一次,用户访问接口或App Server时,依旧会从redis中访问,这无论是对应用的性能还是mysql减少压力都会有很大的优势。
伪代码实现:

![]()
首先,使用视频id和redisPrefix定义一个redis的key,然后从redis中获取key对应的 VideoInfo,再判断vaideoInfo如果为空,则从mysql中查询并返回对应视频id的视频信息 videoInfo;再次判断videoInfo 从mysql返回的结果不为空后进行序列化并set存入到redis 中。
3)实战3:
实现如下功能:分布式id生成器

![]()
比如我们有三个java的服务,我们希望每次获取到的id是自增的,并且是由三个服务去并发的获取,必须满足不重复又逐步递增。
解决方法:
incr id (原子操作)使用 incr 对共享的id进行操作,该操作由于原子性,可保证并发安全。
6、key 的设置命令:set setnx setxx

![]()
演示:

![]()
7、批量操作API:mget mset

![]()
演示:

![]()
8、延伸:
1)n次get

![]()
n次get = n次网络时间 + n次命令时间
由于大部分情况下,应用的客户端和服务端都处在不同的地区或机房,双方的信息交换即网络时间是一个很大的开销,而由于redis本身的优越性能,命令本身的开销是非常小的。
2)1次mget

![]()
1次mget = 1次网络时间 + n次命令时间
使用批量操作可以大大减少网络时间的消耗,有利于提高性能和效率。
9、Redis 的API : getset 、append、strlen

![]()
演示:

![]()
10、Redis 的API :incrbyfloat 、getrange、setrange

![]()
演示:

![]()
11、字符串总结:

![]()
五、 hash(1)
哈希:
- 特点
- 重要API
- hash vs string
- 查漏补缺
1、哈希键值结构:

![]()
如图:哈希的结构也是主要由键值结构组成,即key - value;但是其value是由 field 和 value 组成。

![]()
由于field属性的存在,与value构成了类似双列集合的结构,我们可以根据需要在相同的key ,即user:1:info 中添加一个field为viewCounter、value为50的值。
2、具体操作如下:
add a new value3、特点:
Mapmap:它的结构类似于一个包含了map的map;
Small redis: 由以上的mapmap结构可知,它就像包含了一个小的redis结构的redis
field不能相同,value可以相同:field类似于key ,每一个都是唯一的
4、相关API:hget 、hset、hdel

![]()
演示:

![]()
5、相关API: hexists 、hlen

![]()
演示:

![]()
6、API: hmget、hmset

![]()
演示:

![]()
六、hash(2)
1、实战:
1)实现如下功能:记录网站每个用户个人主页的访问量?
具体实现:
hincrby user:1:info pageview count分析:
用user:1:info作为用户id,在用户的信息里面添加一个叫pageview的属性作为访问量的字段,这样可以让访问量的属性与用户信息成为一个整体,当有一个用户访问时,count为1,则访问量加1。
演示:
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5
2) 实现如下功能: 缓存视频的基本信息(数据源在mysql中)伪代码:

![]()
2、API:hgetall key、hvals key、hkeys key

![]()
演示:

![]()
小心使用hgetall,有redis是单线程的,使用hgetall取出多个信息的时候会有效率上的问题,即数据量过大时,如1万个value时,获取结果会很慢。
3、相似的API:


4、如何更新用户的属性:
1)使用字符串1:

![]()
将用户id作为key,并将用户属性及值的集合转换为json作为value保存到redis中;做更新操作时,根据用户id去取得所有的属性及值的json集合,由json格式转换为用户对象类型;对要修改的部分做增删改操作,将修改后的对象数据进行序列化,重新保存到对应用户id的redis中,覆盖原来的value值。
2)使用字符串2:

![]()
如图中,将用户的信息根据用户id+属性名的方式进行拼接作为key,这样该用户的所有信息都是单独保存到redis中,在进行修改时只需要根据对应的key就可以进行修改了,将修改后的数据重新覆盖原来的信息。
同时的,在进行添加新的属性时,只需要按照key的规则进行单独添加即可。
3)使用hash:
用户信息(hash)

![]()
如图中,将用户的属性作为value的field,属性值作为vlue来进行添加到用户id作为key的redis中。更新用户信息时直接使用hset user:1:infor age 41 进行操作便可实现age的修改,同样也可以用来进行新增操作:如图中的link属性。
5、3种方案比较:

![]()
6、查漏补缺:

![]()
7、哈希总结:

![]()
七、 list(1)
列表:
- 特点
- 重要API
- 实战
- 查漏补缺
1、列表结构:

![]()
可以对列表做一些操作:如左边的添加、右边的添加、左边的弹出、右边的弹出

![]()
也可以获取列表的长度、删除指定元素、获取字列表、获取指定元素的索引值
2、特点:
- 有序
- 可以重复
- 左右两边插入弹出
3、增——rpush

![]()
例如:使用rpush 向右边插入值 c b a

![]()
4、增——Ipush

![]()
例如:使用Ipush从右向左依次插入c b a

![]()
八、list(2)
1、增——linsert

![]()
例如:向值b的左边或右边插入值java或php

![]()
2、删——Ipop:

![]()
例如:从列表左侧弹出一个key ,弹出对象不需要指定,只需指定该列表listkey即可

![]()
3、删—— rpop:

![]()
例如:从列表右侧弹出一个key ,弹出对象不需要指定,只需指定该列表listkey即可

![]()
4、删——Irem :

![]()
例子:删除所有的a,从右到左删除1个c

![]()
5、列表修剪—— Itrim:

![]()
例如:第一次修剪索引1-4的值为:b(0)、c(1)、d(2)、e(3)
第二次修剪索引0-2的值为: b(0)、c(1)、d(2)、

![]()
Itrim在做一些大型列表的删除时是非常有用的,比如:一个列表有几百万,如果直接使用delkey的话会直接将redis阻塞掉,因为它的开销是非常大的。
而通过使用Itrim就可以通过每一个保留百万条、十万条、万条等等这样的方式去逐步的进行裁剪,从而达到删除的效果。
6、查——Irange:

![]()
例如:根据索引从左向右(0~5)或从右向左(-1~6)的查询

![]()
例如:保存0~2索引区间:a、bc、
保存1~-1索引区间:b、c、d、e、f

![]()
7、查—— lindex :

![]()
例如:获取索引为0的是a ;获取索引为-1的是f
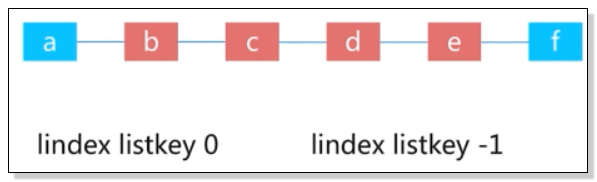
![]()
8、查—— llen

![]()
例如:当前的长度是6

![]()
9、改 —— lset

![]()
例如:将索引为2的值改为java,即java覆盖值c
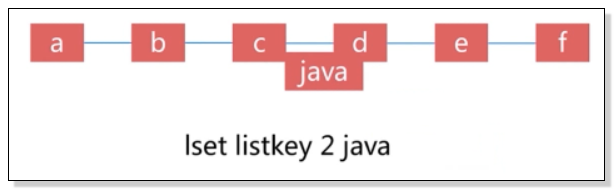
![]()
演示:

![]()
10、实战—— TimeLine

![]()
图中展示了微博的时间轴功能—— TimeLine,它会将微博按照从新到旧的功能进行排列,这和列表的功能是非常相似的。

![]()
假设图中的Your TimeLine是你微博的时间轴,如果你关注的用户有了更新,俺么该更新信息就会加入到时间轴的左上角,进入队列中。
在微博之中,包含了文字、图片、赞等等信息,可作为对象看待,存储的时候可以使用字符串或hash等等,而微博的id可以作为一个外联的key,这样就可以对微博的获取进行关联。
11、查漏补缺: -- blpop brpop:

![]()
12、总结:
①如果要实现一个栈的功能:
LRUSH + LPOP = Stack
②如果要实现一个堆的功能:
LRUSH +LPOP = Stack
③如果要控制一个有固定数量的列表,而不是让它无限制放大:
LPUSH + LTRIM = Capped Collection
④如果要实现一个消息队列的系统:
LPUSH + BRPOP = Message Queue
九、set
set:
- 集合结构
- 特点
- 集合内API和实战
- 集合间API和实战
1、特点:
- 无序
- 无重复
- 支持集合间操作
2、增—— sadd srem :

![]()
工具—— scard 、sismember、srandmember、smembers、

![]()
注意: smembers 是无序且单线程的。
srandmember 和 spop:
- spop 从集合弹出元素
- srandmember不会破坏集合
演示:

![]()
3、实战
1)实战——抽奖系统:

![]()
以微博的抽奖为例,只要用户的量不是太大,可以把用户信息放入到集合中去,可以使用can be spop 进行弹出操作,在取出之后进行删除。
2)实战——标签(tag)

![]()

![]()
4、sdiff(差集) 、sinter(交集)、sunion(并集)

![]()
5、集合的使用场景:
1) SADD = Tagging 做标签
2) SPOP/SRANDMEMBER = Random item 随机数
3) SADD + SINTER = Social Graph 社交相关的场景
十、 zset
有序集合:
- 特点
- 重要API
- 实战
- 查漏补缺
1、有序结合的结构:

![]()
上图是有序集合的结构图,有序集合同样是有key-value键值结构的,但是它的value是由score和value构成的。它的有序是由score分值支持的,这与排序无关,所谓有序是指它的score是唯一的,并且由数值构成,意味着score的值是有序的。
2、集合和有序集合的对比:

![]()
3、列表和有序集合的对比:

![]()
4、增—— zadd :

![]()
例如:为id 为 user:1:ranking的用户添加一个score为225的element为tom的value

![]()
5、删—— zrem :

![]()
例如:删除id为user:1:ranking 的用户的score为225且element为tom的value

![]()
6、查—— zscore:

![]()
例如:获取有序集合中元素为tom的分数score 225.

![]()
7、自增或自减 —— zincrby:

![]()
例如:将元素为mike的分数增加9,达到100.

![]()
8、查个数——zcard :

![]()
例如:返回key为user:1:ranking 的元素的总个数

![]()
演示:

![]()
9、按照索引排名—— zrange :

![]()
例如:获取有序集合中索引为1到3的元素 mike 、frank、charis

![]()
10、按照分数排名——zrangebyscore :

![]()
例如:获取90分到123分的元素: mike 、frank

![]()
11、获取指定分数范围的元素个数—— zcount :

![]()
例如:获取200到210之间的个数: 2

![]()
12、按照排名范围进行元素的删除—— zremrangebyrank :

![]()
例如:删除集合中索引为1和2的元素

![]()
13、按照分值范围进行元素的删除 —— zremrangebyscore :

![]()
例如:将90到210间分数的元素删除

![]()
演示:

![]()
14、实战——排行榜 :

![]()
使用有序集合对新书榜单进行分数、销量、评价等进行排序。
15、有序集合总结:

![]()