CukeTest+Puppeteer系列
1、CukeTest+Puppeteer的Web自动化测试(一)
2、CukeTest+Puppeteer的Web自动化测试(二)
上一篇我们讲了CukeTest+Puppeteer的相关理论知识,带大家认识熟悉了CukeTest如何运行与如何编写剧本,Puppeteer大体的理论体系与如何结合使用,但一直没有给大家进行上手实战操作。这一篇,我就带大家一起来实战燥起来~~~
测试页面以百度首页为例,我们用CukeTest+Puppeteer编写功能测试Demo,将上篇讲的相关知识点结合起来练手。
CukeTest官方文档:http://www.cuketest.com/zh-cn/
Puppeteer官方文档:https://zhaoqize.github.io/puppeteer-api-zh_CN/
一、实例1
功能测试:参数化形式打开多个网页
1、打开CukeTest我们来新建一个空项目,安装Node和Puppeteer,注意(两者版本兼容问题),上文中已提到过的。
2、编辑剧本相关参数
3、编写剧本对应的脚本
4、运行
如下图
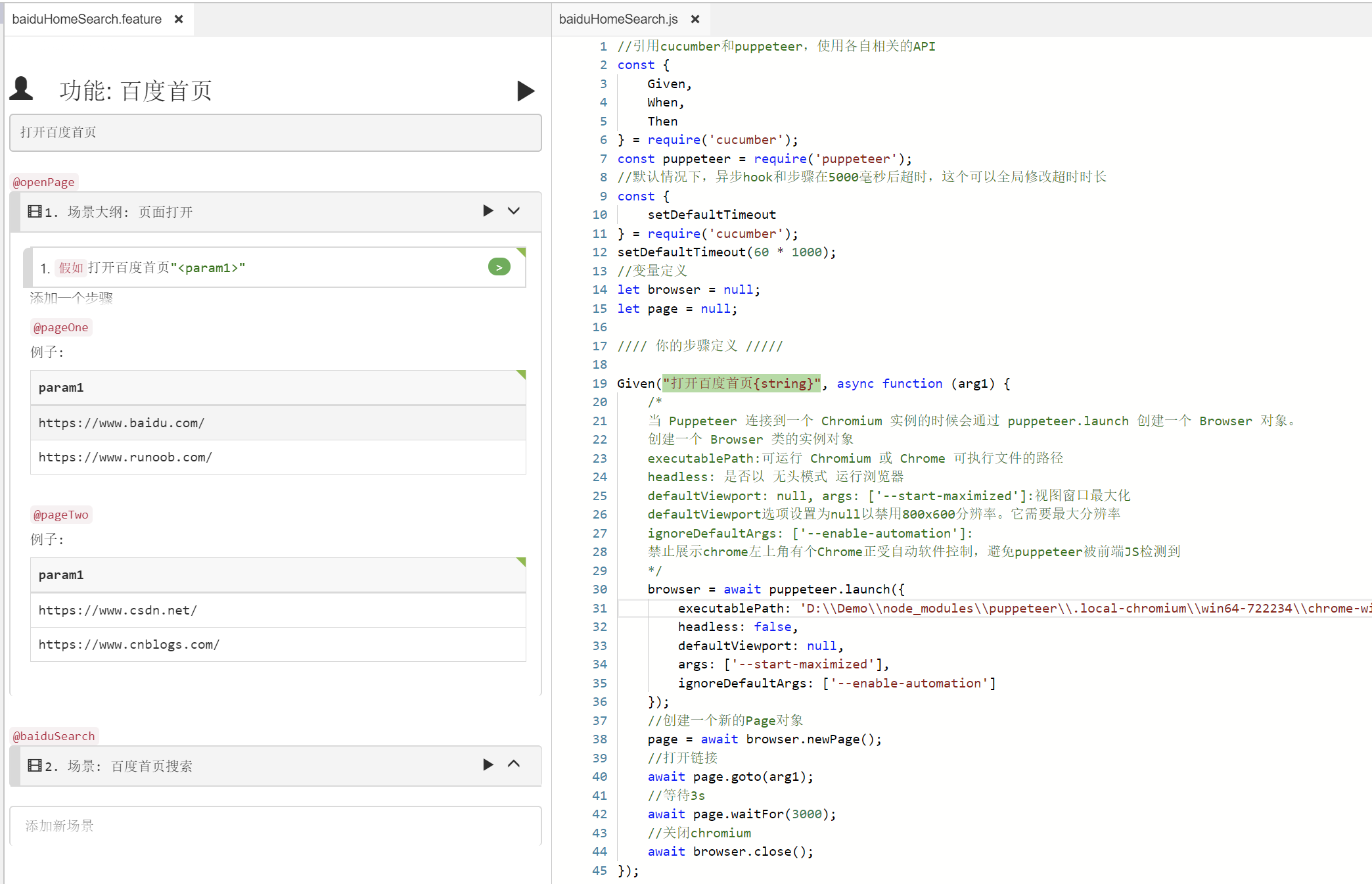
剧本的文本如下
# language: zh-CN 功能: 百度首页 打开百度首页 @openPage 场景大纲: 页面打开 假如打开百度首页"<param1>" @pageOne 例子: | param1 | | https://www.baidu.com/ | | https://www.runoob.com/ | @pageTwo 例子: | param1 | | https://www.csdn.net/ | | https://www.cnblogs.com/ | @baiduSearch 场景: 百度首页搜索 打开百度首页,搜索'puppeteer',百度查询并截图保存结果 假如打开百度首页"https://www.baidu.com/" 当输入"puppeteer",点击百度一下 那么截图保存搜索结果
剧本对应的脚本
1 //引用cucumber和puppeteer,使用各自相关的API 2 const { 3 Given, 4 When, 5 Then 6 } = require('cucumber'); 7 const puppeteer = require('puppeteer'); 8 //默认情况下,异步hook和步骤在5000毫秒后超时,这个可以全局修改超时时长 9 const { 10 setDefaultTimeout 11 } = require('cucumber'); 12 setDefaultTimeout(60 * 1000); 13 //变量定义 14 let browser = null; 15 let page = null; 16 17 //// 你的步骤定义 ///// 18 19 Given("打开百度首页{string}", async function (arg1) { 20 /* 21 当 Puppeteer 连接到一个 Chromium 实例的时候会通过 puppeteer.launch 创建一个 Browser 对象。 22 创建一个 Browser 类的实例对象 23 executablePath:可运行 Chromium 或 Chrome 可执行文件的路径 24 headless: 是否以 无头模式 运行浏览器 25 defaultViewport: null, args: ['--start-maximized']:视图窗口最大化 26 defaultViewport选项设置为null以禁用800x600分辨率。它需要最大分辨率 27 ignoreDefaultArgs: ['--enable-automation']: 28 禁止展示chrome左上角有个Chrome正受自动软件控制,避免puppeteer被前端JS检测到 29 */ 30 browser = await puppeteer.launch({ 31 executablePath: 'D:\Demo\node_modules\puppeteer\.local-chromium\win64-722234\chrome-win\chrome.exe', 32 headless: false, 33 defaultViewport: null, 34 args: ['--start-maximized'], 35 ignoreDefaultArgs: ['--enable-automation'] 36 }); 37 //创建一个新的Page对象 38 page = await browser.newPage(); 39 //打开链接 40 await page.goto(arg1); 41 //等待3s 42 await page.waitFor(3000); 43 //关闭chromium 44 await browser.close(); 45 });
运行:浏览器按顺序打开剧本中编辑的四个网页,打开一个网页后关闭浏览器,紧接着打开下一个。
二、实例2
功能:打开百度首页搜索,并保存截图。
在基于上面的实例1,接着编写场景2,如下图
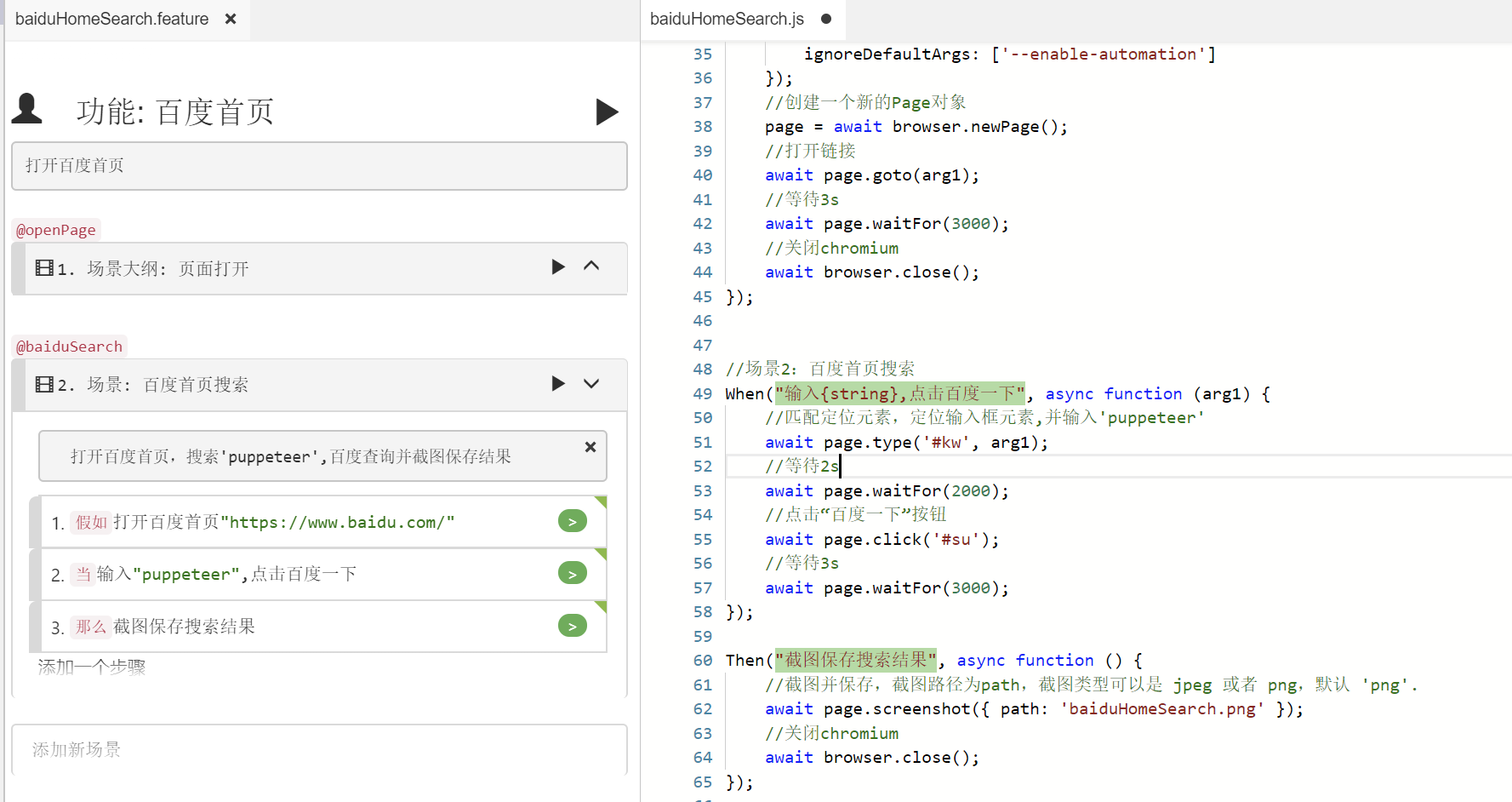
场景对应的脚本:
1 //场景2:百度首页搜索 2 When("输入{string},点击百度一下", async function (arg1) { 3 //匹配定位元素,定位输入框元素,并输入'puppeteer' 4 await page.type('#kw', arg1); 5 //等待2s 6 await page.waitFor(2000); 7 //点击“百度一下”按钮 8 await page.click('#su'); 9 //等待3s 10 await page.waitFor(3000); 11 }); 12 13 Then("截图保存搜索结果", async function () { 14 //截图并保存,截图路径为path,截图类型可以是 jpeg 或者 png,默认 'png'. 15 await page.screenshot({ path: 'baiduHomeSearch.png' }); 16 //关闭chromium 17 await browser.close(); 18 });