 ,
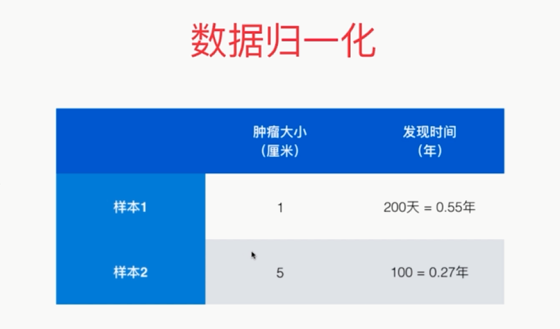
, 
 ,
, 
No.1. 数据归一化的目的
数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用。
No.2. 数据归一化的方法
数据归一化的方法主要有两种:最值归一化和均值方差归一化。
最值归一化的计算公式如下: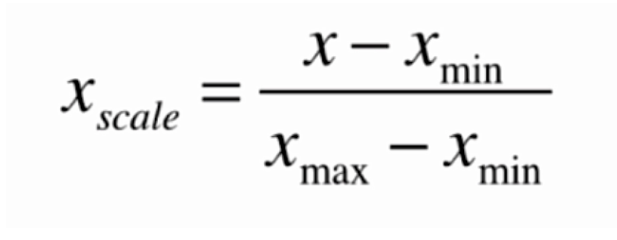
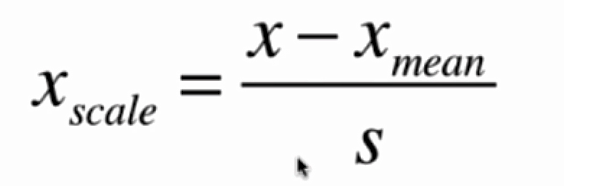
 ,
,  ,
, 
最值归一化的特点是,可以将所有数据都映射到0-1之间,它适用于数据分布有明显边界的情况,容易受到异常值(outlier)的影响,异常值会造成数据的整体偏斜。
均值方差归一化的计算公式如下:
均值方差归一化的特点是,可以将数据归一化到均值为0方差为1的分布中,不容易受到异常值(outlier)影响。
No.3. 向量和矩阵的最值归一化
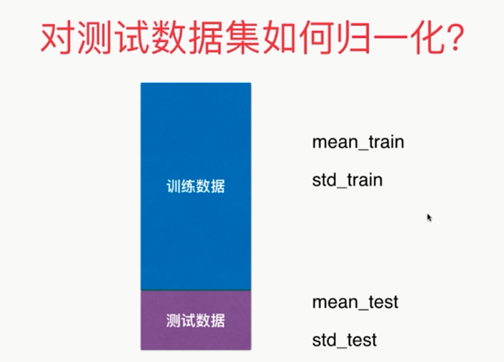
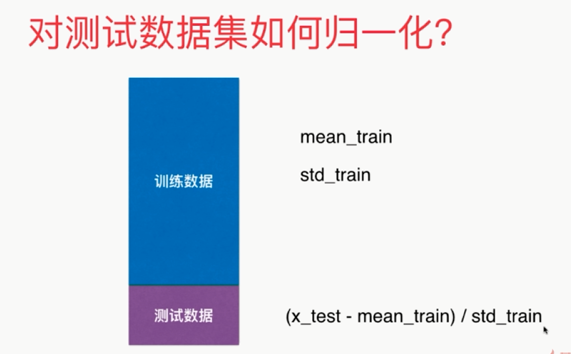
如何对测试数据集进行归一化处理?
不能直接求mean_test,std_test!!!
应该使用训练数据集求得的mean_train,std_train
, ,
