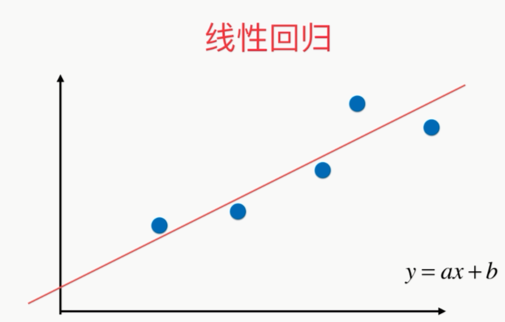
问题:线性回归要求假设我们的数据背后存在线性关系;
 ,
,
如果将x的平方理解成一个特征,x理解成另一个特征;本来只有一个特征x,现在看成有两个特征的数据集,多了一个特征,就是x的平方,其实式子本身依然是一个线性回归的式子,但是从x 的角度来看,也就是所谓的非线性方程,这样的方式就叫做多项式回归
PCA降维,多项式回归提升维度
 ,
,


import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error np.random.seed(666) x=np.random.uniform(-3.0,3.0,size=100) X=x.reshape(-1,1) y=0.5*x**2+x+2+np.random.normal(0,1,size=100) from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler def PolynomialRegression(degree): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("lin_reg", LinearRegression()) ]) poly2_reg=PolynomialRegression(degree=2) poly2_reg.fit(X,y) y2_predict=poly2_reg.predict(X) mean_squared_error(y,y2_predict) plt.scatter(x,y) plt.plot(np.sort(x),y2_predict[np.argsort(x)],color='r') plt.show() # 不同的degree poly10_reg=PolynomialRegression(degree=10) poly10_reg.fit(X,y) y10_predict=poly10_reg.predict(X) mean_squared_error(y,y10_predict) plt.scatter(x,y) plt.plot(np.sort(x),y10_predict[np.argsort(x)],color='r') plt.show() # degree=100 poly100_reg=PolynomialRegression(degree=100) poly100_reg.fit(X,y) y100_predict=poly100_reg.predict(X) mean_squared_error(y,y100_predict) plt.scatter(x,y) plt.plot(np.sort(x),y100_predict[np.argsort(x)],color='r') plt.show()
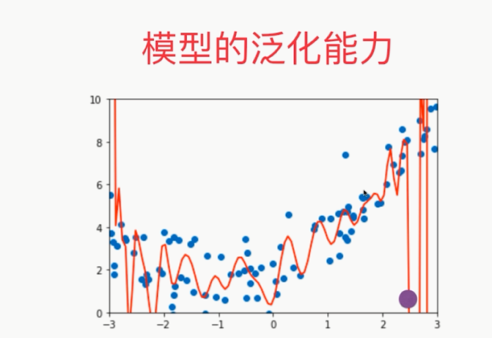
机器学习主要解决的问题其实是过拟合的问题。
泛化能力:由此及彼的能力(根据已知的训练数据得到的这条曲线,可是这条曲线在面对新的数据的时候它的能力却非常弱,也就是泛化能力差)
我们要训练这个模型为的不是最大程度的拟合这些点,而是为了获得一个可以预测的模型,当有了新的数据的时候,我们的模型可以给出很好的解答。
所以,我们去衡量我们的模型对于这个训练的数据它的拟合程度有多好是没有意义的,我们真正需要的是能够衡量我们的得到的这个模型的泛化能力有多好。
因此使用训练数据集和测试数据集
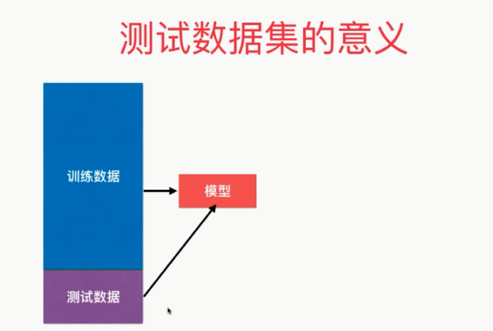
如果使用训练数据获得的的这个模型面对测试数据也能获得很好的结果的话,我们就说这个模型的泛化能力就是很强的!!!但是如果面对测试数据集它的效果很差的话,那么的的泛化能力就是很弱的,多半我们就遭遇了过拟合
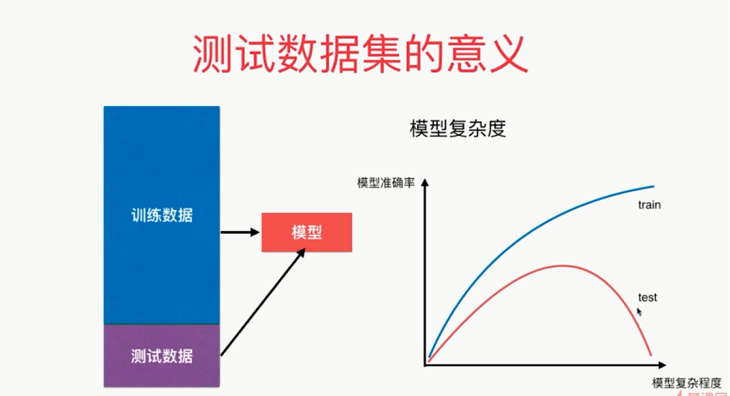
模型的复杂度:不同的模型代表的意思不同
KNN:K越小,模型越复杂;K=1,最复杂
多项式回归:阶数越大,degree越大,模型越复杂
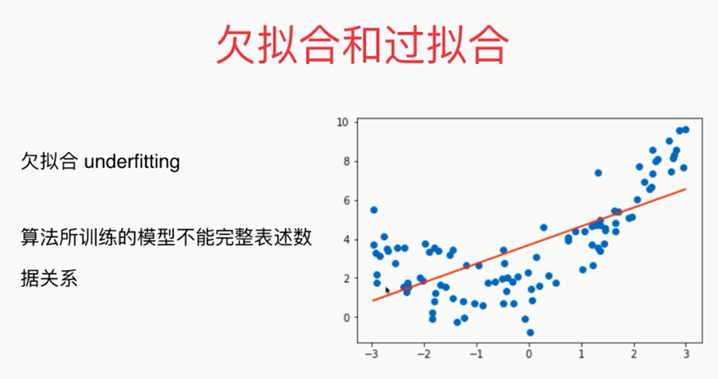 ,
,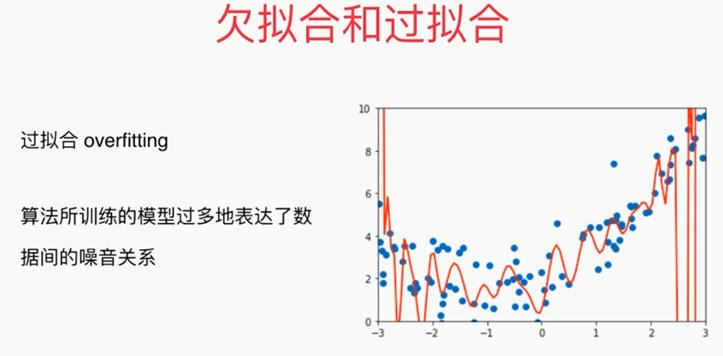
 ,
,
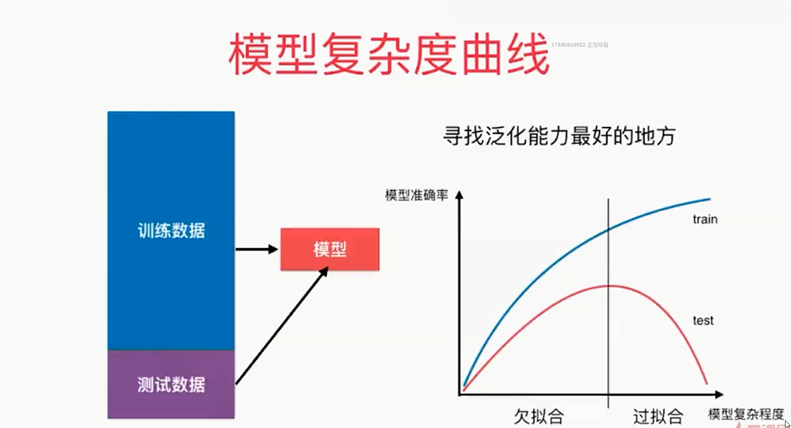 ,
,
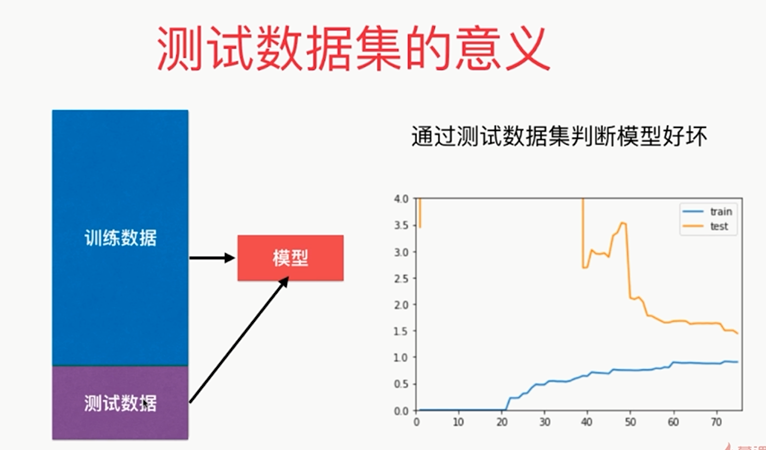
通过学习曲线也可以看到模型的过拟合和欠拟合
学习曲线:随着训练样本的逐渐增多,算法训练出的模型的表现能力
import numpy as np import matplotlib.pyplot as plt np.random.seed(666) x=np.random.uniform(-3.0,3.0,size=100) X=x.reshape(-1,1) y=0.5*x**2+x+2+np.random.normal(0,1,size=100) from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=10) from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error train_score=[] test_score=[] for i in range(1,76): lin_reg=LinearRegression() lin_reg.fit(X_train[:i],y_train[:i]) # 依次取训练数据、测试数据的前i个元素 y_train_predict=lin_reg.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i],y_train_predict)) y_test_predict=lin_reg.predict(X_test) test_score.append(mean_squared_error(y_test,y_test_predict)) plt.plot([i for i in range(1,76)],np.sqrt(train_score),label="train") plt.plot([i for i in range(1,76)],np.sqrt(test_score),label="test") plt.legend() plt.show() # 封装成函数 def plot_learning_curve(algo,X_train,X_test,y_train,y_test): train_score=[] test_score=[] for i in range(1,len(X_train)+1): algo.fit(X_train[:i],y_train[:i]) y_train_predict=algo.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i],y_train_predict)) y_test_predict=algo.predict(X_test) test_score.append(mean_squared_error(y_test,y_test_predict)) plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(train_score),label="train") plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(test_score),label="test") plt.legend() plt.axis([0,len(X_train)+1,0,4]) plt.show() plot_learning_curve(LinearRegression(),X_train,X_test,y_train,y_test) # 使用多项式回归 from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler def PolynomialRegression(degree): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("lin_reg", LinearRegression()) ]) poly2_reg=PolynomialRegression(degree=2) plot_learning_curve(poly2_reg,X_train,X_test,y_train,y_test) poly2_reg=PolynomialRegression(degree=20) # 过拟合 plot_learning_curve(poly2_reg,X_train,X_test,y_train,y_test)
, ,
,
 ,
,
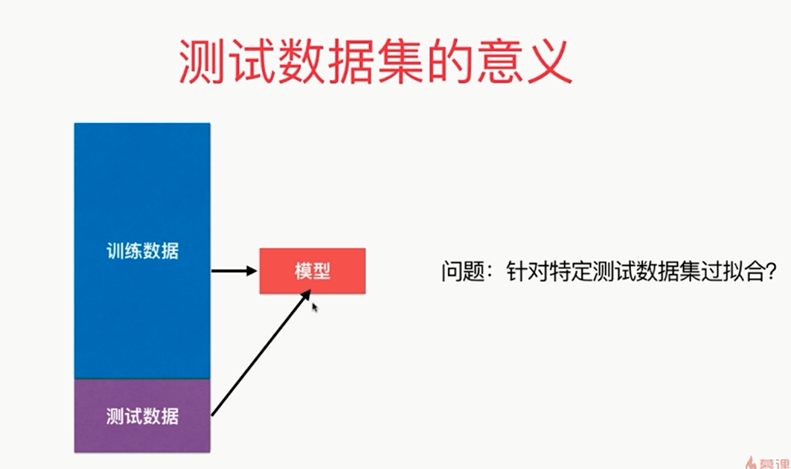 ,一定程度上围绕着测试数据集打转,也就是说我们在想办法找到一组参数,这组参数使得我们用训练数据集获得的模型在测试数据集上的效果最好,但是由于测试数据集是已知的,我们相当于在针对这组测试数据集调参,那么它也有可能产生过拟合的情况,也就是说我们得到的这个模型针对这个测试数据集过拟合了
,一定程度上围绕着测试数据集打转,也就是说我们在想办法找到一组参数,这组参数使得我们用训练数据集获得的模型在测试数据集上的效果最好,但是由于测试数据集是已知的,我们相当于在针对这组测试数据集调参,那么它也有可能产生过拟合的情况,也就是说我们得到的这个模型针对这个测试数据集过拟合了
解决方法:将整个数据分成三部分:训练数据集、验证数据集(validation test)、测试数据集(将验证数据集当成之前的测试数据集)
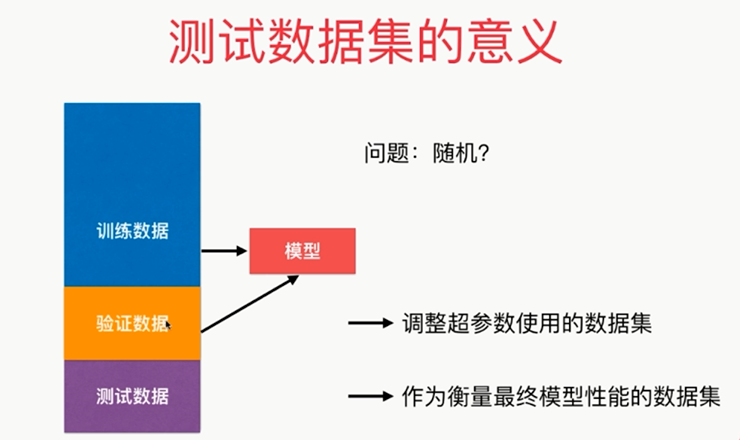 ,
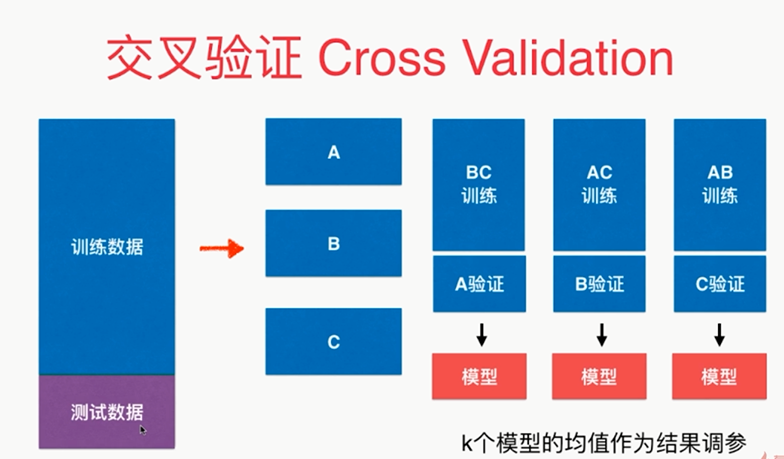
,
import numpy as np from sklearn import datasets digits=datasets.load_digits() # 手写识别数据 X=digits.data y=digits.target # 测试train_test_split from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4,random_state=666) from sklearn.neighbors import KNeighborsClassifier best_score, best_p, best_k = 0, 0, 0 for k in range(2, 11): for p in range(1, 6): knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p) knn_clf.fit(X_train, y_train) knn_clf.score(X_test, y_test) score = knn_clf.score(X_test, y_test) if score > best_score: best_score, best_p, best_k = score, p, k print("Best K=", best_k) print("Best P=", best_p) print("Best Score", best_score) # 使用交叉验证 from sklearn.model_selection import cross_val_score knn_clf=KNeighborsClassifier() cross_val_score(knn_clf,X_train,y_train,cv=3) best_score, best_p, best_k = 0, 0, 0 for k in range(2, 11): for p in range(1, 6): knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p) scores = cross_val_score(knn_clf, X_train, y_train, cv=3) score = np.mean(scores) if score > best_score: best_score, best_p, best_k = score, p, k print("Best K=", best_k) print("Best P=", best_p) print("Best Score", best_score) best_knn_clf=KNeighborsClassifier(weights="distance",n_neighbors=2,p=2) # 选用刚刚找到的最好的参数 best_knn_clf.fit(X_train,y_train) best_knn_clf.score(X_test,y_test) # 对于模型完全没有见过的test # 回顾网格搜索 from sklearn.model_selection import GridSearchCV # cv:就是交叉验证的意思,cross_validation param_grid = [ { 'weights': ['distance'], 'n_neighbors': [ i for i in range(2,11)], 'p':[i for i in range(1,6)] } ] grid_search=GridSearchCV(knn_clf,param_grid,verbose=1,cv=3,n_jobs=-1) #n_jobs=-1的时候,表示cpu里的所有core进行工作(cv:交叉验证,默认3) grid_search.fit(X_train,y_train) grid_search.best_score_ grid_search.best_params_ cross_val_score(knn_clf,X_train,y_train,cv=5)
 ,
,
留一法:训练数据集有m个样本,就分成m份;每次都将m-1份样本用于训练,然后去看预测那剩下的一个样本预测的准不准,将这些结果综合起来来进行评均,作为衡量我们当前参数下这个模型对应的预测的准确度
偏差方差平衡:Bias Variance Trade off
 ,
,
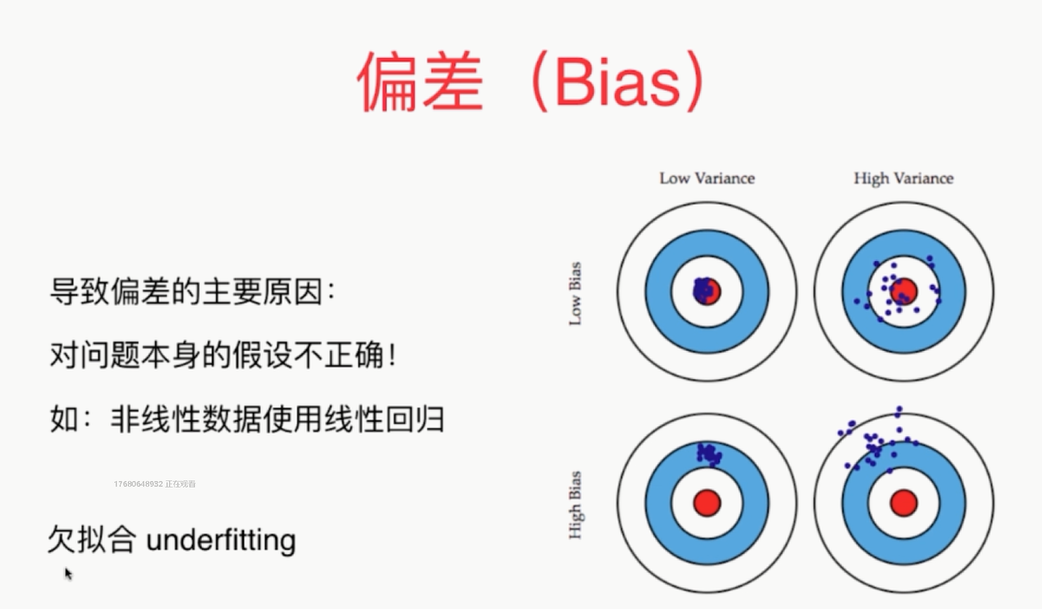 ,
,
导致较高方差:是模型太过复杂,没有完全的学习到这个问题的实质,而学习到了很多的噪音
 ,
,
 ,
,
 ,
,
高方差:泛化能力差
解决方差:模型的正则化
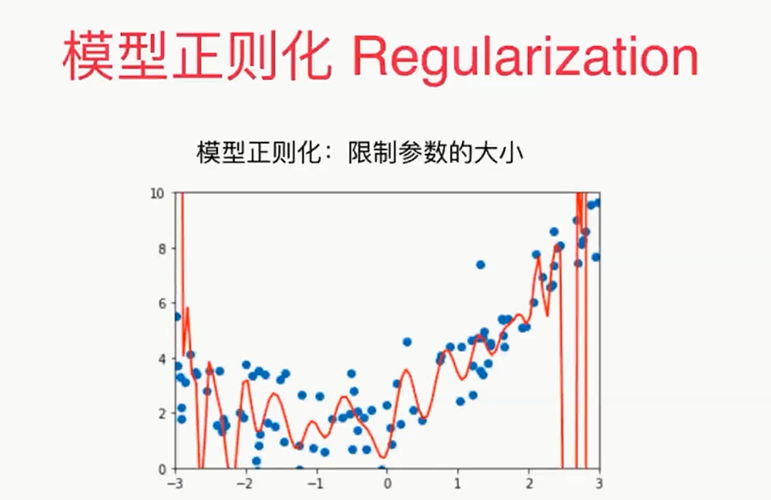 ,
,
α:新的超参数
这种正则化的方式又叫做岭回归

import numpy as np import matplotlib.pyplot as plt np.random.seed(42) x=np.random.uniform(-3.0,3.0,size=100) X=x.reshape(-1,1) y=0.5*x+3+np.random.normal(0,1,size=100) plt.scatter(x,y) plt.show() from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression def PolynomialRegression(degree): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("lin_reg", LinearRegression()) ]) from sklearn.model_selection import train_test_split np.random.seed(666) X_train,X_test,y_train,y_test=train_test_split(X,y) from sklearn.metrics import mean_squared_error poly_reg=PolynomialRegression(degree=20) poly_reg.fit(X_train,y_train) y_predict=poly_reg.predict(X_test) mean_squared_error(y_test,y_predict) X_plot=np.linspace(-3,3,100).reshape(100,1) y_plot=poly_reg.predict(X_plot) plt.scatter(x,y) plt.plot(X_plot[:,0],y_plot,color='r') plt.axis([-3,3,0,6]) plt.show() def plot_model(model): X_plot=np.linspace(-3,3,100).reshape(100,1) y_plot=model.predict(X_plot) plt.scatter(x,y) plt.plot(X_plot[:,0],y_plot,color='r') plt.axis([-3,3,0,6]) plt.show() plot_model(poly_reg) # 使用岭回归 from sklearn.linear_model import Ridge def RidgeRegression(degree,alpha): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("ridge_reg", Ridge(alpha=alpha)) ]) ridge1_reg=RidgeRegression(20,0.0001) ridge1_reg.fit(X_train,y_train) y1_predict=ridge1_reg.predict(X_test) mean_squared_error(y_test,y1_predict) plot_model(ridge1_reg) ridge2_reg=RidgeRegression(20,1) ridge2_reg.fit(X_train,y_train) y2_predict=ridge2_reg.predict(X_test) mean_squared_error(y_test,y2_predict) plot_model(ridge2_reg) ridge3_reg=RidgeRegression(20,100) ridge3_reg.fit(X_train,y_train) y3_predict=ridge3_reg.predict(X_test) mean_squared_error(y_test,y3_predict) plot_model(ridge3_reg)
另外一种模型正则化的方式:LASSO Regularization
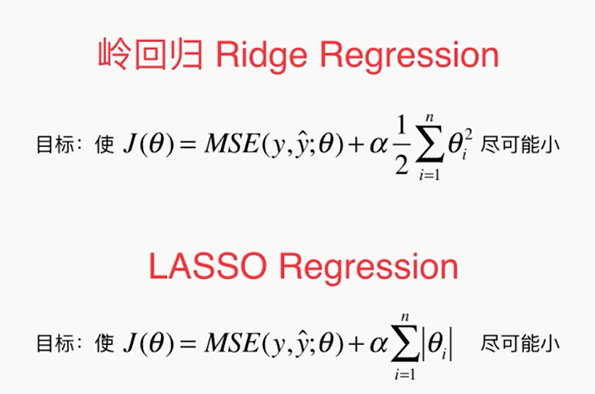 ,
,
import numpy as np import matplotlib.pyplot as plt np.random.seed(42) x=np.random.uniform(-3.0,3.0,size=100) X=x.reshape(-1,1) y=0.5*x+3+np.random.normal(0,1,size=100) plt.scatter(x,y) plt.show() from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression def PolynomialRegression(degree): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("lin_reg", LinearRegression()) ]) from sklearn.model_selection import train_test_split np.random.seed(666) X_train,X_test,y_train,y_test=train_test_split(X,y) from sklearn.metrics import mean_squared_error poly_reg=PolynomialRegression(degree=20) poly_reg.fit(X_train,y_train) y_predict=poly_reg.predict(X_test) mean_squared_error(y_test,y_predict) def plot_model(model): X_plot=np.linspace(-3,3,100).reshape(100,1) y_plot=model.predict(X_plot) plt.scatter(x,y) plt.plot(X_plot[:,0],y_plot,color='r') plt.axis([-3,3,0,6]) plt.show() plot_model(poly_reg) # LASSO from sklearn.linear_model import Lasso def LassoRegression(degree,alpha): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("std_scaler", StandardScaler()), ("ridge_reg", Lasso(alpha=alpha)) ]) lasso1_reg=LassoRegression(20,0.01) lasso1_reg.fit(X_train,y_train) y1_predict=lasso1_reg.predict(X_test) mean_squared_error(y_test,y1_predict) plot_model(lasso1_reg) # 增大α lasso2_reg=LassoRegression(20,0.1) lasso2_reg.fit(X_train,y_train) y2_predict=lasso2_reg.predict(X_test) mean_squared_error(y_test,y2_predict) plot_model(lasso2_reg)
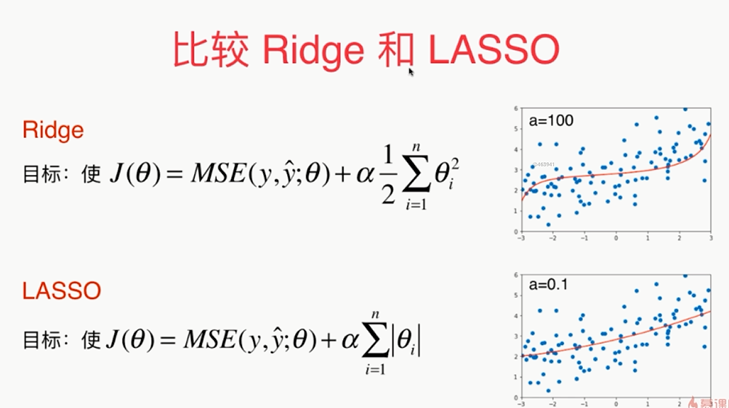 ,
,
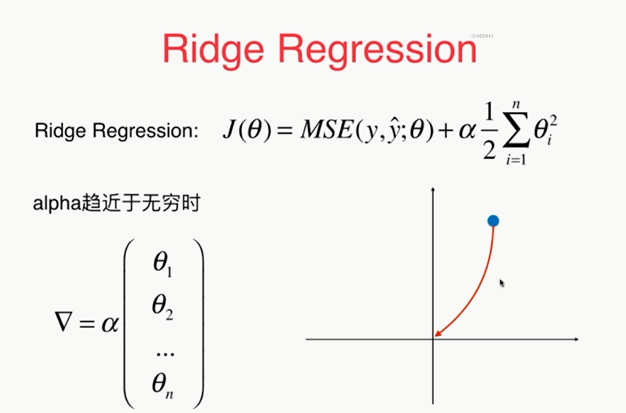 ,
, 
 ,
,
 ,
, 
 ,
,
