一、Hive的简介和配置
1.简介
Hive是构建在Hadoop之上的数据操作平台l Hive是一个SQL解析引擎,它将SQL转译成MapReduce作业,并在Hadoop上运行Hive表是HDFS的一个文件目录,一个表名对应一个目录名,如果存在分区表的话,则分区值对应子目录名。
2.Hive的体系结构
Hive作为Hadoop的数据仓库处理工具,它所有的数据都存储在Hadoop兼容的文件系统中。Hive在加载数据的过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive设置的指定目录下,因此,Hive不支持对数据的改写和添加,所有的数据都是在加载的时候设定的,Hive的设计特点如下:
1.支持索引,加快数据查询
2.不同的存储类型,例如:纯文本文件、HBase中的文件
3. 将元数据保存在关系型数据库中,减少了在查询中执行语义的检查时间
4. 可以直接使用存储在Hadoop文件系统中的数据
5. 内置大量的用户UDF来操作时间,字符串和其他数据挖掘工具,支持用户扩展UDF来完成内置函数无法完成的操作
6.类SQL的查询方式,将SQL查询转换为MapReduce的job在Hadoop集群上执行
7.编码与Hadoop同样采用UTF-8

用户接口:
① CLI:CLI启动的时候,会同时启动一个Hive副本
② JDBC客户端:封装了Thrift,Java应用程序可以通过指定的主机和端口 连接到在另一个进程中的Hive服务
③ WEB接口:通过浏览器访问Hive服务
Thrift服务器:
① 基于Socket通讯,支持跨语言。Hive的Thrift服务简化了在多编程语言 中运行Hive命令,绑定支持C++,JAVA,PHP和Ruby语言。
解析器:
① 编译器:完成HQL语句的从词法分析、语法分析、编译优化以及执行计 划的生成。
② 优化器:是一个演化组件,当前它的规则是:列修剪,谓词下压
③ 执行器:会顺序执行所有的Job。如果Task链不存在依赖关系,可以采取 并发方式执行Job
元数据库:
① Hive的数据由两部分组成:数据文件和元数据。元数据用于存放Hive库的基 础信息,它存储在关系型数据库中,如MySQL、Derby。元数据包括:数据库信息、表 的名字、表的列和分区及其属性,表的属性,表的数据所在目录等。
Hadoop:
① Hive的数据文件存储在HDFS中,大部分的查询由MapReduce构成,不过对 于包含*的查询,比如select * from lbl不会生成MapReduce作业。
3.Hive的运行机制
① 用户通过用户接口连接Hive,发布Hive SQL
② Hive解析查询并制定查询计划
③ Hive将查询转换为MapReduce作业
④ Hive在Hadoop上执行MapReduce作业
4.Hive的优势
1. 解决了传统关系数据库在大数据处理上的瓶颈,适合大数据的批量处理
2.充分利用集群的CPU计算资源、存储资源,实现并行计算
3.Hive支持标准SQL语法,免去了编写MR程序的过程。提升开发效率
4.具有良好的扩展性,拓展功能很方便
5.Hive的缺点
1.Hive的HQL表达能力有限:有些复杂运算HQL不易表达
2.Hive的效率低:Hive自动生成MR作业,通常不够智能;HQL调优困难,粒度较粗;可控性差
3.针对Hive运行效率低下等问题,促使人们去寻找一种更快,更具交互性的分析框架。SparkSQL的出现则有效的提高了Sql在Hadoop上的分析效率
6.Hive的配置(Lin集群)
(1).Hive配置前的准备: 完整的hadoop集群; ssh免密登录;安装mysql数据库;安装java
(2).下载Hive的tar包 下载地址:http://mirror.bit.edu.cn/apache/hive/
(3).上传Hive到Linux系统上 #将压缩包解压到对应目录 tar -zxvf /usr/localhost/apache-hive-2.3.5-bin.tar.gz
(4).#将解压的目录重命名为hive mv apache-hive-2.3.5-bin/ hive
(5).#设置hive的环境的变量 vim /etc/profile
(6).#编辑内容如下(在profile文件)
export HIVE_HOME=/usr/local/hive (这个路径是自己将解压后的包解压后的位置)
export PATH=$PATH:$HIVE_HOME/bin
(7.)#刷新文件(保存后) source /etc/profile
(8).#检查hive版本 hive --version
(9).Hive的配置
#切换到hive的配置文件目录
cd /usr/local/hive/conf/
#以模板复制一个hive-site.xml
cp hive-default.xml.template hive-site.xml
#编辑hive-site.xml文件
vim hive-site.xml
#将以下内容插入到hive-site.xml文件,其他内容替换
<property><!--数据库用户名-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property><!--数据块密码-->
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property><!--连接字符串-->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property><!--驱动类-->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<!--关闭数据库的版本检查-->
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
(9).接下来将mysql的数据库驱动包放置到hive下的lib目录中
初始化Hive元数据
schematool -dbType mysql -initSchema
(10).beeline连接操作 (找到hadoop的路径在相应的文件下修改以下下文件)
hdfs-site.xml文件
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
core-site.xml文件
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
(11).使用scp命令发送到slave1与slave2两台节点上,
scp hdfs-site.xml core-site.xml root@slave1:/usr/local/hadoop-2.8.0/etc/hadoop/
scp hdfs-site.xml core-site.xml root@slave2:/usr/local/hadoop-2.8.0/etc/hadoop/
(12).hdfs namenode -format 重启服务 格式化namenode节点 (利用dbvis操作hive)
------------------------hiveserver2打开服务
hiveserver2
------------------------beeline连接
beeline
!connect jdbc:hive2://master:10000
------------------------安装dbvis
(13).注意事项
在格式化hadoop集群时 从起hadoop会发现dataName没有启动成功
解决办法: 进入hadoop的安装路径 找到 etc/hadoop 查看hadoop的tmp文件路径然后进入
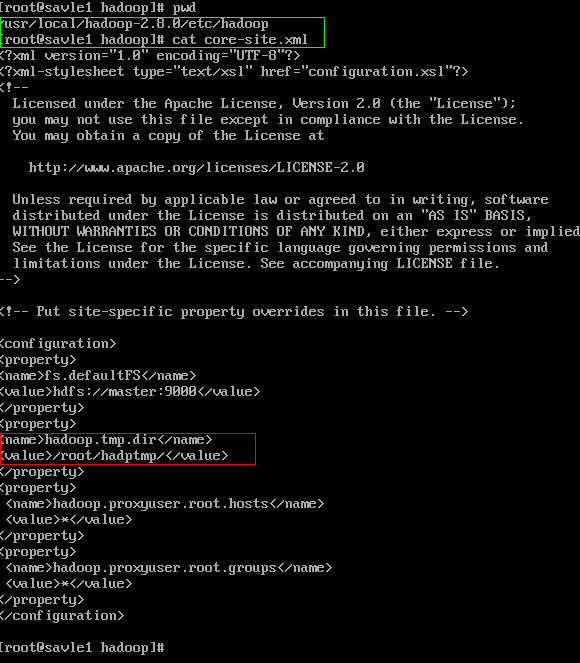
进入红色圈中的文件夹

复制标红的哪一行代码 到从节点的相同目录文件下 覆盖原有的一行
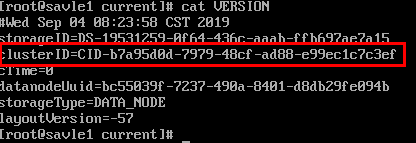
从起集群即可解决