一、Hive的数据类型
1.基本数据类型

由上表我们看到hive不支持日期类型,在hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
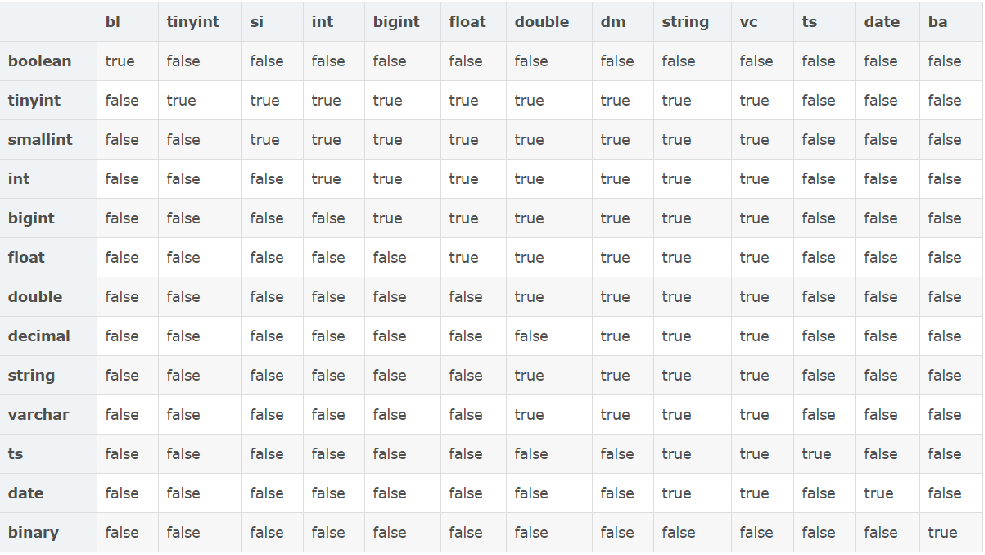
hive是用java开发的,hive里的基本数据类型和java的基本数据类型也是一一对应的,除了string类型。有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。Hive的浮点数据类型FLOAT和DOUBLE,对应于java的基本类型float和double类型。而hive的BOOLEAN类型相当于java的基本数据类型boolean。
对于hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
Hive支持基本类型的转换,低字节的基本类型可以转化为高字节的类型,例如TINYINT、SMALLINT、INT可以转化为FLOAT,而所有的整数类型、FLOAT以及STRING类型可以转化为DOUBLE类型,这些转化可以从java语言的类型转化考虑,因为hive就是用java编写的。当然也支持高字节类型转化为低字节类型,这就需要使用hive的自定义函数CAST了
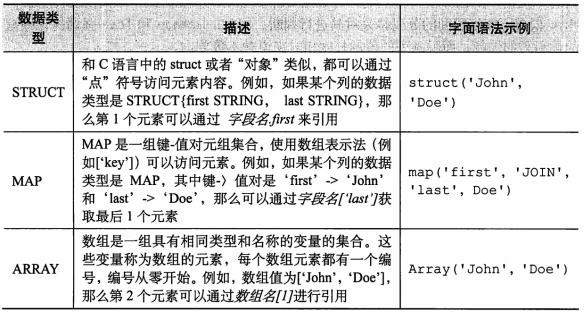
2.复杂数据类型
复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT/或者可以理解为对象),具体如下表所示:
3.文本的字符编码
文本格式文件,毫无疑问,对于用户来讲,应该很熟悉以逗号或者制表符分割的文本文 件,只要用户需要,Hive是支持这些文件格式的。然而这两种文件格式有一个共同的缺点, 那就是用户需要对文本文件中那些不需要作为分隔符处理的逗号或者制表符格外小心,也 因此,Hive默认使用了几个控制字符,这些字符很少出现在字段值中。Hive使用属于field来表示替换默认分隔符的字符。

二、数据库的操作
1.创建数据库
create database 数据库名;
2.查看数据库
//查看全部数据库 SHOW DATABASES; //查看指定数据库 SHOW DATABASE 数据库名; //使用like实现模糊查询,例如:以hive开头的数据库 SHOW DATABASE LIKE 'like_*'; //查看数据库的详细描 desc database hive_01;
3.使用数据库
use 数据库名;
4.删除数据库
//数据库名;这种删除,需要将对应数据库中的表全部删除后才能删除数据库 drop database 数据库名; // 强制删除,自行删除所有表 drop database 数据库名 cascade;
三、数据表操作
1.创建数据表
//创建内部表 create table inner_table( id int, name string, hobby array<string>, address map<string,string> ) row format delimited //固定格式 fields terminated by ','//表示分割字段 collection items terminated by '-'//分割数组 map keys terminated by ':';//分割集合
注意事项:
我所创建的数据表根据每一个分割的符号根据自己的需求改写

加载数据
//inpath后是Linux中要加载文件的路径 overwrite表示从写会清空加载之前的所有数据 load data local inpath '/hivetest/person.txt' overwrite into table person;
//创建外部表 //创建外部表需要运用external关键字 create external table inner_table( id int, name string, hobby array<string>, address map<string,string> ) row format delimited //固定格式 fields terminated by ','//表示分割字段 collection items terminated by '-'//分割数组 map keys terminated by ':';//分割集合 location '/outter/data' //此路径是HDFS中的已有路径
2.内部表和外部表的区别
虽然内部表和外部表只有一个关键字之差,但是性质是完全不一样的,内部表存在hive中,若删除则内部表不能恢复,外部表被删除之后,在创建的外部表的hdfs路径上回留下一个文件,当再次创建相同字段的类型时吧路径指向原有的路径那么不需要导入数据,创建表之后就自动存在,如果在新建的表中,只要local的路径内存在着文件,那么文件会跟着创建的表类型匹配,产生错误的表.
如果 直接讲表放到为外部表的位置 但是在hive中没有该表的元数据,要通过 MSCK REPAIR TABLE table_name (将HDFS上的元数据信息写入到metastore);
3.查看表
//查看表的全部内容 select * from 表名; //查看表结构 desc formatted 表名; //查看库中的表 show tables; //将查询的表结果放到新表 create table 表名 as select 查询字句; //创建结构相同 没有数据的表 CREATE TABLE 新表 LIKE 被复制的表;
4.删除表
drop table 表名;
5.修改表
//1:表的重命名 alter table 源表名 rename to 新表名; //2:表修改列的信息 alter table 表名 change 表列名 新表列名 新表列名类型; //3:为表新增列(一次性插入多列) alter table 表名add columns( 列名1 列名1类型, 列名2 列名2类型 ) //4:删除与替换列 在hive中本质上不能删除 所以用替换来实现删除的效果 alter table person_info replace columns( id string, name string, hobby array<string>, address map<string,string> ) //5:替换表的存储格式 rcfile-->orcfile alter table t1 set fileformat sequencefile; //6:查看建表的语句 show create table 表名; //7:设置表的注释 alter table person_info set tblproperties("comment"="person detail"); //8:修改表的分隔符 alter table person_info set serdeproperties( 'colelction.delim'='~'); //9:设置表的serde_class 序列化的类 create table t1(id int,name string,age int); alter table t1 set serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties ("input.regex" = "id=(.*),name=(.*),age=(.*)")
注意事项:在修改类型时应该注意类型的兼容性如下图: