主要内容:
列表 和 元组和字典
列表
一、列表介绍
列表是一种能存储大量数据的数据结构,是能装对象的对象。由方括号 [] 括起来,能放任意类型的数据,数据之间用逗号隔开
列表存储数据是有顺序的
二、增删改查
lis = []
1、增加 (三种)
lis.append() 在末尾追加,一次只能加一个
lis.insert(index, 元素) 在指定位置插入元素,这种方法由于会改变列表中其他索引,“牵一发而动全身”,所以运行效率会低一些
lis.extend(可迭代对象) 迭代添加
2、删除
lis.pop() “弹出一个” 删除末尾的元素,并返回删除的元素值,也可以指定索引删除指定元素(通过索引删除)
lis.remove(元素) 移除一个某个元素(通过值删除元素)
lis.clear() 清空列表
切片删除
del lis[1:3] # 删除索引是1,2的元素

索引切片修改
# 修改
lst = ["太白", "太", "五", "银王", "日天"]
lst[1] = "太污" # 把1号元素修改成太污
print(lst)
lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步长不是1, 要注意. 元素的个数
print(lst)
lst[1:4] = ["李嘉诚很厉害"] # 如果切片没有步长或者步长是1. 则不用关心个数
print(lst)
结果:
['太白', '太污', '五', '银王', '日天']
['太白', '麻花藤', '五', '哇靠', '日天']
['太白', '李嘉诚很厉害', '日天']
3、修改
只能根据索引值修改
即
lis[index] = " new"
4、查询
、根据索引和切片查找某个或某些元素
lis = ["列","表","与","元组"]
# 循环输出列表中元素
for c in lis :
print(c) # 代表列表中每个元素
# 循环输列表中元素 带索引
for n in rang(len(lis)):
print(n, lis[n])
、列表循环遍历
三、列表常用功能
lis.count(元素) 统计某个元素在列表出现次数
lis.index(元素) 返回元素的索引 没有时报错 ValueError: 5 is not in list
lis.sort() 列表排序,对于纯数字元素的列表,从小到大排序(升序)
lis.sort(reverse = True) 从大到小排序(逆序)
注意: 字符串不要用这个方法排序,不是不能排,而是用这个方法排完也没有什么价值,因为用的是默认的字符串比较大小的方式
"xxx".join(lis) 用"xxx"将列表元素连成字符串, 和split()功能相反 两个可以一起记
四、列表嵌套
想要找某个元素是,用降维的方法,一层一层的找,一定要注意每一层对应的是什么数据
元组
元组由括号()括起来。可以存任意类型数据
元组是不可变数据类型,所以,增删改查中只有查能进行,所以也被称为“只读列表”
对元组不可变性的理解:
它的不可变性体现在元组在创建时第一层元素的内存地址就是固定的了,所以如果元素是不可变数据类型,比如字符串,那么是无法对其有修改操作的,但如果元素是可变数据类型,比如列表,是可以对其进行一些修改操作的。参考图解
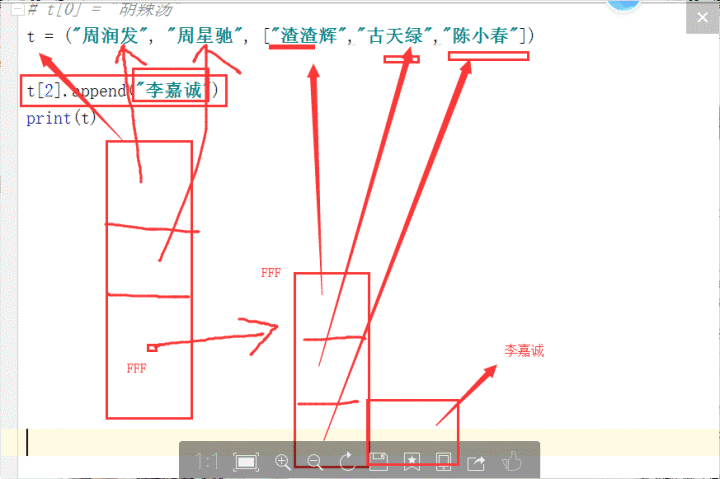
注意坑:元组如果只有一个元素,要加逗号,不然会将括号算作运算符
t1 = (2)
t2 = (2,)
t3 = (1,2,3,)
print(t1) # 2
print(type(t1)) #<class 'int'>
print(t2) #(2,)
print(type(t2)) #<class 'tuple'>
print(t3) #(1,2,3)
print(type(t3) #<class 'tuple'>
code
常用操作:
t = (1,2,2,4,5,"张")
t.index() 查找指定索引元素 元素不存在时报错 ValueError: tuple.index(x): x not in tuple
t.count() 统计某个元素出现次数
补充知识:
range()函数
range(n) 遍历[0,n)的元素
range(m,n) 遍历[m,n)的元素
range(m,n,p) 从m到n, 每隔p个取一个 p为负数可以倒序遍历 如range(100,0,-1) 遍历[100,0)的元素
列表删除
切片删除
del lis[1:3] # 删除索引是1,2的元素
修改

索引切片修改 # 修改 lst = ["太白", "太", "五", "银王", "日天"] lst[1] = "太污" # 把1号元素修改成太污 print(lst) lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步长不是1, 要注意. 元素的个数 print(lst) lst[1:4] = ["李嘉诚个⻳⼉⼦"] # 如果切片没有步长或者步长是1. 则不用关心个数 print(lst)
字典
字典由花括号表示{ },元素是key:value的键值对,元素之间用逗号隔开
特点:1、字典中key是不能重复的 且是不可变的数据类型,因为字典是使用hash算法来计算key的哈希值,然后用哈希值来存储键值对数据
2、字典中元素是无序的
3、value值可以是任意类型的数据
注:字典中的key是可hash的,可hash的数据的都是不可变的数据类型
已知的可哈希(不可变)的数据类型: int, str, tuple(元组), bool
不可哈希(可变)的数据类型: list(列表), dict(字典), set(集合)
增删改查
创建一个空字典---两种方式:
dic ={}
dic = dict()
新增(两种方式)
dic[key] = value # 可以新增也可修改已有key的value值
dic.setdefault(key, value) # 如果key是没有的,新增;如果key已存在 保持原值(这个方法是分两步的 在查询会细说)
删除(四种方式)
pop(key) # 必须指定一个key 删除指定元素
popitems( ) # 随机删除一个值(字典是无序的) 但是在3.6版本里效果是删除字典最后一个元素--->原因 3.5之前字典打印输出是无序的,但在3.6之后字典打印输出是按照元素添 加的顺序的,所以感觉用这个方法时是删除的最后一个元素,但是这个方法的源码里还是随机删除的
del dic[key] # 删除指定元素
dic.clear() # 清空字典
修改(两种)
dic[key] = new value #赋一个新值
dic.update(dic2) #将dic2更新到dic中
查询(三种)
dic[key] #查询指定元素 key不存在时报错
dic.get(key,[xxx]) # 查询key的value key不存在时返回xxx,如果不写xxx,默认返回None
dic.setdefault(key,[value]) # 执行逻辑 第一步,看key是否存在,key存在, 不添加也不修改value;不存在,添加key:value键值对,value没有时默认为None
第二步,返回key对应的value值
常用操作
dic.keys() 返回所有的键 返回的是一个可迭代对象,形式像列表但又不是列表
1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.keys()) #dict_keys(['意大利', '意大利2', '美国', '美国电视剧'])
4
5 for k in dic.keys(): # 可以迭代。 拿到的是每一个key
6 print(k)
dic.values() 返回所有的值
dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
print(dic.values()) #dict_values(['西西里的美丽传说', '天堂电影院', '美国往事', '越狱'])
for value in dic.values():
print(value)
dic.items() 返回所有的键值对
1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.items()) #dict_items([('意大利', '西西里的美丽传说'), ('意大利2', '天堂电影院'), ('美国', '美国往事'), ('美国电视剧', '越狱')])
4 for k ,v in dic.items():
5 print(k ,v)
6
7 #遍历字典最好的方案
8 for k, v in dic.items(): # 拿到的是元组(key, value) 这是解包操作
9 print(k,v) #直接拿到key和value