逻辑斯蒂分布
 图像是这样的:
图像是这样的: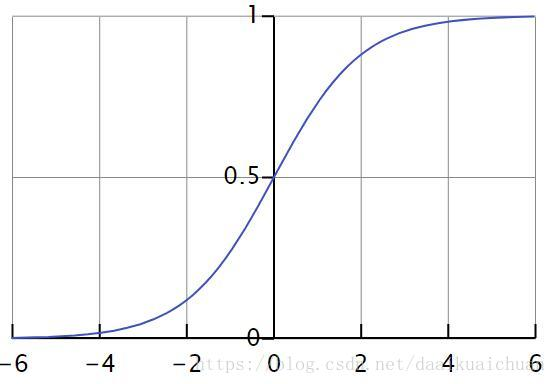
此时我们将线性模型产生的预测值带入sigmoid函数,函数会输出相对应的二分类的概率,具体的训练方法和上面的线性回归是一样的,不同的是误差函数的求导
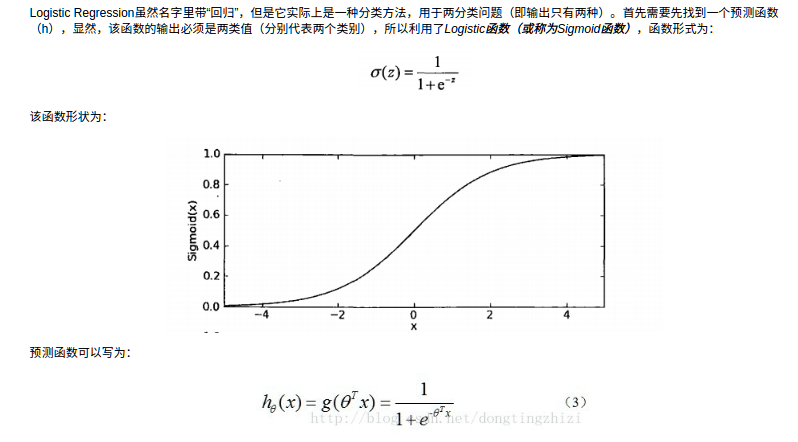


逻辑斯蒂回归算法的优缺点
1、优点
1. 形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大;
2. 模型效果不错。在工程上是可以接受的(作为baseline),如果特征工程做的好,效果不会太差,并且特征工程可以大家并行开发,大大加快开发的速度;
3. 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型;
4. 资源占用小,尤其是内存。因为只需要存储各个维度的特征值;
5. 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
2、缺点
1. 准确率并不是很高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
2. 很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好;
3. 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题;
4. 逻辑回归本身无法筛选特征。有时候,我们会用gbdt来筛选特征,然后再上逻辑回归
逻辑斯蒂回归算法的相关问题
(1)逻辑斯蒂回归适合应用在什么场景?
在我们的工业应用上,如果需要作出分类的数据拥有很多有意义的特征,每个特征(我们假设这些特征都是有效的)都对最后的分类结果又或多或少的影响,那么最简单最有效的办法就是将这些特征线性加权,一起参与到作出决策的过程中。比如预测广告的点击率,又比如从原始数据集中筛选出符合某种要求的有用的子数据集。
逻辑斯蒂回归还有一个优点,那就是它不是硬性地将分类结果定为0或者1,而是给出了0和1之间的概率。这就相当于对每条数据的分类结果给出了一个打分。打分越高的数据越是我们想要的。如果我们要从一个数据集中筛选出一批数据(比如100个),就只要选出打分排名前100的数据就可以了。我们也可以根据实际情况设定一个阀值,大于这个阀值的归为一类,小于这个阀值的归为另一类。
logistic回归应用领域:
1. 用于二分类领域,可以得出概率值,适用于根据分类概率排名的领域,如搜索排名等;
2. Logistic回归的扩展softmax可以应用于多分类领域,如手写字识别等;
3. 信用评估;
4. 测量市场营销的成功度;
5. 预测某个产品的收益;
6. 特定的某天是否会发生地震。
(2)逻辑回归的损失函数为什么要使用极大似然函数作为损失函数?
(3)逻辑回归在训练的过程当中,如果有很多的特征高度相关或者说有一个特征重复了100遍,会造成怎样的影响?
(4)为什么我们还是会在训练的过程当中将高度相关的特征去掉?
(5)使用L1L2正则化,为什么可以降低模型的复杂度?
(6)为什么L1能得到稀疏解呢?
(7)L1正则化不可导,怎么求解?

参考文献:
https://blog.csdn.net/daaikuaichuan/article/details/80848958