来详细的看看 mycat的配置文件,更多信息请查看:mycat权威指南。
schema.xml:
Schema.xml 作为 MyCat 中重要的配置文件之一,管理着 MyCat 的逻辑库、表、分片规则、DataNode 以 及 DataSource。
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑库配置--> <!--一个schema标签就是一个逻辑库, 逻辑库名称 --> <schema name="db_store" checkSQLschema="false" sqlMaxLimit="100"> <!--非分片表的配置 名称,从属节点 主键--> <table name="store" dataNode="db_store_dataNode" primaryKey="storeID"/> <table name="employee" dataNode="db_store_dataNode" primaryKey="employeeID"/> </schema> <schema name="db_user" checkSQLschema="false" sqlMaxLimit="100"> <!--全局表 指定 type ,指定所在分片 ,主键--> <table name="data_dictionary" type="global" dataNode="db_user_dataNode1,db_user_dataNode2" primaryKey="dataDictionaryID"/> <!--分片表的配置 ,配置分片节点 ,rule 配置分片规则,具体配置在rule.xml里面,在rule.xml再细说--> <table name="users" dataNode="db_user_dataNode$1-2" rule="mod-userID-long" primaryKey="userID"> <!--ER表,通过parentKey去找 users表对应的分片,放到同一个分片下--> <childTable name="user_address" joinKey="userID" parentKey="userID" primaryKey="addressID"/> </table> </schema> <!-- 节点配置 为什么 db_store只有一个节点呢?因为这个节点理的两个主机是主从复制实现了读写分离 这里即具备读也具备了写。在节点主机配置中有体现。 --> <!-- db_store --> <dataNode name="db_store_dataNode" dataHost="db_storeHOST" database="db_store" /> <!-- db_user --> <dataNode name="db_user_dataNode1" dataHost="db_userHOST1" database="db_user" /> <dataNode name="db_user_dataNode2" dataHost="db_userHOST2" database="db_user" /> <!-- 主从复制 节点主机配置 --> <!-- 配置db_store的节点主机 最大连接数100 最小10 --> <dataHost name="db_storeHOST" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <!-- 心跳机制 --> <heartbeat>select user()</heartbeat> <!-- 读写分离 can have multi write hosts 写节点(master)--> <writeHost host="hostM1" url="192.168.254.138:3306" user="root" password="wuzhenzhao"> <!-- can have multi read hosts 读节点(slave)--> <readHost host="hostS1" url="192.168.254.136:3306" user="root" password="wuzhenzhao" /> </writeHost> </dataHost> <!-- 配置db_user的节点主机 --> <dataHost name="db_userHOST1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="userHost1" url="192.168.254.138:3306" user="root" password="wuzhenzhao"> </writeHost> </dataHost> <dataHost name="db_userHOST2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="userHost2" url="192.168.254.136:3306" user="root" password="wuzhenzhao"> </writeHost> </dataHost> </mycat:schema>
schema 标签:
schema 标签用于定义 MyCat 实例中的逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配 置。可以使用 schema 标签来划分这些不同的逻辑库。
1)dataNode 属性:该属性用于绑定逻辑库到某个具体的 database 上。
2)checkSQLschema 属性:当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;**则 MyCat 会把语句修改 为**select * from travelrecord;**。即把表示 schema 的字符去掉,避免发送到后端数据库执行时报**(ERROR 1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。** 不过,即使设置该值为 true ,如果语句所带的是并非是 schema 指定的名字,例如:**select * from db1.travelrecord;** 那么 MyCat 并不会删除 db1 这个字段,如果没有定义该库的话则会报错,所以在提供 SQL 语句的最好是不带这个字段。
3)sqlMaxLimit 属性:当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应 的值。需要注意的是,如果运行的 schema 为非拆分库的,那么该属性不会生效。需要手动添加 limit 语句。
table 标签:
Table 标签定义了 MyCat 中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
1)name 属性: 定义逻辑表的表名,这个名字就如同我在数据库中执行 create table 命令指定的名字一样,同个 schema 标 签中定义的名字必须唯一。
2)dataNode 属性: 定义这个逻辑表所属的 dataNode, 该属性的值需要和 dataNode 标签中 name 属性的值相互对应。如果需 要定义的 dn 过多 可以使用($1-2) 方法减少配置。例如我上面的例子。
3)rule 属性: 该属性用于指定逻辑表要使用的规则名字,规则名字在 rule.xml 中定义,必须与 tableRule 标签中 name 属 性属性值一一对应。
4)ruleRequired 属性: 该属性用于指定表是否绑定分片规则,如果配置为 true,但没有配置具体 rule 的话 ,程序会报错。
5)primaryKey 属性 :该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就 会发送查询语句到所有配置的 DN (dataNode)上,如果使用该属性配置真实表的主键。难么 MyCat 会缓存主键与具体 DN 的 信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的 DN,但是尽管 配置该属性,如果缓存并没有命中的话,还是会发送语句给具体的 DN,来获得数据。推荐配置成有唯一索引的字段,这样子能大大提高数据库性能。
6)type 属性:该属性定义了逻辑表的类型,目前逻辑表只有“全局表”和”普通表”两种类型。对应的配置:全局表:global。普通表:不指定该值为 globla 的所有表。
7)autoIncrement 属性 :mysql 对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0。所以,只有定义了自增长主 键的表才可以用 last_insert_id()返回主键值。 mycat 目前提供了自增长主键功能,但是如果对应的 mysql 节点上数据表,没有定义 auto_increment,那 么在 mycat 层调用 last_insert_id()也是不会返回结果的。 由于 insert 操作的时候没有带入分片键,mycat 会先取下这个表对应的全局序列,然后赋值给分片键。这样 才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的分片键值。 如果要使用这个功能最好配合使用数据库模式的全局序列。 使用 autoIncrement=“true” 指定这个表有使用自增长主键,这样 mycat 才会不抛出分片键找不到的异 常。 使用 autoIncrement=“false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
8)subTables 属性: 使用方式添加 subTables="t_order$1-2,t_order3"。 目前分表 1.6 以后开始支持 并且 dataNode 在分表条件下只能配置一个,分表条件下不支持各种条件的 join 语句。
9)needAddLimit 属性 :指定表是否需要自动的在每个语句后面加上 limit 限制。由于使用了分库分表,数据量有时会特别巨大。这时 候执行查询语句,如果恰巧又忘记了加上数量限制的话。那么查询所有的数据出来,也够等上一小会儿的。 所以,mycat 就自动的为我们加上 LIMIT 100。当然,如果语句中有 limit,就不会在次添加了。 这个属性默认为 true,你也可以设置成 false`禁用掉默认行为。
childTable 标签:
childTable 标签用于定义 E-R 分片的子表。通过标签上的属性与父表进行关联。
1)name 属性 定义子表的表名。
2)joinKey 属性 插入子表的时候会使用这个列的值查找父表存储的数据节点。
3)parentKey 属性 属性指定的值一般为与父表建立关联关系的列名。程序首先获取 joinkey 的值,再通过 parentKey 属性指定 的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上。从而确定子表存储的位置。
4)primaryKey 属性 同 table 标签所描述的。
5)needAddLimit 属性 同 table 标签所描述的。
dataNode 标签:
dataNode 标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。
1)name 属性: 定义数据节点的名字,这个名字需要是唯一的,我们需要在 table 标签上应用这个名字,来建立表与分片对 应的关系。
2)dataHost 属性 :该属性用于定义该分片属于哪个数据库实例的,属性值是引用 dataHost 标签上定义的 name 属性。
3)database 属性: 该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个纬度来定义分片,就是:实 例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。
dataHost 标签 :
作为 Schema.xml 中最后的一个标签,该标签在 mycat 逻辑库中也是作为最底层的标签存在,直接定义了具 体的数据库实例、读写分离配置和心跳语句。现在我们就解析下这个标签。
dataHost 标签的相关属性:属性名,值,数量限制
1)name String (1) :唯一标识 dataHost 标签,供上层的标签使用。
2)maxCon Integer (1) :指定每个读写实例连接池的最大连接。
3)minCon Integer (1) :指定每个读写实例连接池的最小连接,初始化连接池的大小。
4)balance Integer (1) :负载均衡类型,目前的取值有 3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
2. balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双 主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载 均衡。
3. balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
4. balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压 力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
5)writeType Integer (1) :
负载均衡类型,目前的取值有 3 种:
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties 。
2. writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。switchType 属 性 - -1 表示不自动切换。 - 1 默认值,自动切换。 - 2 基于 MySQL 主从同步的状态决定是否切换。
6)dbType String (1) :指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如: mongodb、oracle、mysql、spark 等。
7)dbDriver String (1):指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的 是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
从 1.6 版本开始支持 postgresql 的 native 原始协议。 如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到 MYCATlib 目录下,并检查驱动 JAR 包中包 括如下目录结构的文件:META-INFservicesjava.sql.Driver。在这个
文件内写上具体的 Driver 类名,例如: com.mysql.jdbc.Driver。
8) switchType 属性: 主从切换策略
-1 表示不自动切换。
1 默认值,自动切换 ,心跳 select user()。
2 基于 MySQL 主从同步的状态决定是否切换 心跳语句为 show slave status (主从延迟解决方案)。
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1) 心跳语句为 show status like ‘wsrep%。
9) slaveThreshold属性: 由于配置了 switch Type属性,会执行心跳语句 select user(),而这个属性就是查看slave的状态有个属性叫 Seconds_Behind_Master,这个属性大于 slave Threshold 配置的值,我们这里是大于100秒,就不会去读取。
超时的从节点,所有数据会从没有延迟的节点去加载或者从主节点加载。
writeHost 标签、readHost 标签:
这两个标签都指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同的是,writeHost 指 定写实例、readHost 指定读实例,组着这些读写实例来满足系统的要求。 在一个 dataHost 内可以定义多个 writeHost 和 readHost。但是,如果 writeHost 指定的后端数据库宕机, 那么这个 writeHost 绑定的所有 readHost 都将不可用。另一方面,由于这个 writeHost 宕机系统会自动的检测 到,并切换到备用的 writeHost 上去。
1)host 属性 :用于标识不同实例,一般 writeHost 我们使用*M1,readHost 我们用*S1。
2)url 属性: 后端实例连接地址,如果是使用 native 的 dbDriver,则一般为 address:port 这种形式。用 JDBC 或其他的 dbDriver,则需要特殊指定。当使用 JDBC 时则可以这么写:jdbc:mysql://localhost:3306/。
3)user 属性 :后端存储实例需要的用户名字。
4)password 属性 :后端存储实例需要的密码。
5)weight 属性 :权重 配置在 readhost 中作为读节点的权重(1.4 以后)。
6)usingDecrypt 属性: 是否对密码加密默认 0 否 如需要开启配置 1,同时使用加密程序对密码加密,加密命令为: 执行 mycat jar 程序(1.4.1 以后):
java -cp Mycat-server-1.6.6.1-release.jar io.mycat.util.DecryptUtil 1:host:user:password Mycat-server-1.6.6.1-release.jar 为 mycat lib 目录的 jar 1:host:user:password 中 1 为 db 端加密标志,host 为 dataHost 的 host 名称
执行结果如下:将该加密串替换掉password的值就可以提高密码安全性。这个时候请加上 usingDecrypt

server.xml:
server.xml 几乎保存了所有 mycat 需要的系统配置信息。其在代码内直接的映射类为 SystemConfig 类。
<?xml version="1.0" encoding="UTF-8"?> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://io.mycat/"> <system> <property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 --> <property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 --> <property name="sequnceHandlerType">2</property> <!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议--> <!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号--> <!-- <property name="processorBufferChunk">40960</property> --> <!-- <property name="processors">1</property> <property name="processorExecutor">32</property>--> <!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena--> <property name="processorBufferPoolType">0</property> <!--默认是65535 64K 用于sql解析时最大文本长度 --> <!--<property name="maxStringLiteralLength">65535</property>--> <!--<property name="sequnceHandlerType">0</property>--> <!--<property name="backSocketNoDelay">1</property>--> <!--<property name="frontSocketNoDelay">1</property>--> <!--<property name="processorExecutor">16</property>--> <!-- <property name="serverPort">8066</property> <property name="managerPort">9066</property> <property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property> <property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> --> <!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤), 2为不过滤分布式事务,但是记录分布式事务日志--> <property name="handleDistributedTransactions">0</property> <!--off heap for merge/order/group/limit 1开启 0关闭--> <property name="useOffHeapForMerge">1</property> <!--单位为m--> <property name="memoryPageSize">1m</property> <!--单位为k--> <property name="spillsFileBufferSize">1k</property> <property name="useStreamOutput">0</property> <!--单位为m--> <property name="systemReserveMemorySize">384m</property> <!--是否采用zookeeper协调切换 --> <property name="useZKSwitch">true</property> </system> <!-- 全局SQL防火墙设置 --> <!-- <firewall> <whitehost> <host host="127.0.0.1" user="mycat"/> <host host="127.0.0.2" user="mycat"/> </whitehost> <blacklist check="false"> </blacklist> </firewall> --> <!--把mycat看成一个超级数据库,在这里配置数据库的用户密码及可以访问的数据库--> <user name="root"> <property name="password">wuzhenzhao</property> <property name="schemas">db_store,db_user</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="db_user" dml="0110" > <table name="users" dml="1111"></table> IUSD <table name="useraddres" dml="1110"></table> </schema> </privileges>--> </user> </mycat:server> --> </user> </mycat:server>
system 标签:
这个标签内嵌套的所有 property 标签都与系统配置有关,请注意,下面我会省去标签 property 直接使用这 个标签的 name 属性内的值来介绍这个属性的作用。
1)sequnceHandlerType 属性 :指定使用 Mycat 全局序列的类型。0 为本地文件方式,1 为数据库方式,2 为时间戳序列方式,3 为分布式 ZK ID 生成器,4 为 zk 递增 id 生成。 从 1.6 增加 两种 ZK 的全局 ID 生成算法。
2)processors 属性 :这个属性主要用于指定系统可用的线程数,默认值为机器 CPU 核心线程数。 主要影响 processorBufferPool、processorBufferLocalPercent、processorExecutor 属性。 NIOProcessor 的个数也是由这个属性定义的,所以调优的时候可以适当的调高这个属性。
3)processorExecutor 属性:线程池内线程的数量
4)serverPort : 定义 mycat 的使用端口,默认值为 8066。
5)managerPort : 定义 mycat 的管理端口,默认值为 9066。 可以使用mysql -uroot -p123456 -P9066 -h192.168.254.138 登陆管理端。
firewall 标签:
全局sql防火墙的设置,设置黑(blacklist)/白(whitehost)名单,黑白名单互斥,理论上只存在一个。
user 标签:
这个标签主要用于定义登录 mycat 的用户和权限。例如上面的例子中,我定 义了一个用户,用户名为 root、密码为 wuzhenzhao,可访问的 schema 有 db_store,db_user 两个。 如果我在 schema.xml 中定义了多个 schema,那么这个用户是无法访问其他的 schema。在 mysql 客户端看来 则是无法使用 use 切换到这个其他的数据库。
1)Benchmark 属性:Benchmark:mycat 连接服务降级处理: benchmark 基准, 当前端的整体 connection 数达到基准值是, 对来自该账户的请求开始拒绝连接,0 或不设 表示不限制 例如 1000
2)usingDecrypt 属性: 80 是否对密码加密默认 0 否 如需要开启配置 1,在上篇博客中有详细说明。
privileges 标签:
对用户的 schema 及 下级的 table 进行精细化的 DML 权限控制,privileges 节点中的 check 属性是用 于标识是否开启 DML 权限检查, 默认 false 标识不检查,当然 privileges 节点不配置,等同 check=false, 由于 Mycat 一个用户的 schemas 属性可配置多个 schema ,所以 privileges 的下级节点 schema 节点同样 可配置多个,对多库多表进行细粒度的 DML 权限控制
按照以上 XML 所配置的来说 root 用户对于库 db_user 的权限是 0110 ,对于users 表是1111 ,对应的操作是 IUSD ( 增,改,查,删 )。同时配置了库跟表的权限,就近原则。以表权限为准。
rule.xml:
rule.xml 里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法, 或者对表使用相同的算法但具体的参数不同。这个文件里面主要有 tableRule 和 function 这两个标签。在具体使 用过程中可以按照需求添加 tableRule 和 function。
<?xml version="1.0" encoding="UTF-8"?> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://io.mycat/"> ........ <tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <!-- 分片规则定义--> <tableRule name="mod-userID-long"> <rule> <!--根据哪个列来分区--> <columns>userID</columns> <!--分区算法,指向下面的function 标签--> <algorithm>mod-long</algorithm> </rule> </tableRule> <tableRule name="sharding-by-murmur"> <rule> <columns>id</columns> <algorithm>murmur</algorithm> </rule> </tableRule> <tableRule name="crc32slot"> <rule> <columns>id</columns> <algorithm>crc32slot</algorithm> </rule> </tableRule> <!--指定分片类。指定规则与2取模--> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function> <function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash"> <property name="seed">0</property><!-- 默认是0 --> <property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --> <property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 --> <!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 --> <!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 --> </function> <function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot"> <property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --> </function> ........ </mycat:rule>
这个配置文件的内容属性比较少,具体作用都标注在XML 里面了。分片规则在 mycat权威指南中说的相当详细(从118页开始)。我这里就简单的描述一下。
根据官方提供的分片规则的特点来分,可以分成三大类:连续分片,离散分片,综合类分片。
1)连续分片:
该分片规则的代表是按日期(天)分片,按照自定义数字范围分片,自然月分片,该分片规则的优点是扩容无需迁移数据库,范围条件查询资源消耗少,缺点是并发能力受限于分片节点。
2)离散分片:
该分片规则的代表是枚举分片,数字取模分片,字符串数字hash分片,一致性hash分片,程序指定,该分片规则的优点是数据分布均匀,并发能力强,不受限分片节点,缺点是移植性差,扩容难。
3)综合类分片:
该分片规则的代表是范围求模分片,取模范围约束分片,该分片规则的优点是兼并以上二者 。
规则是很多,我这边主要列举两个,一个是按照数字范围分片跟取模分片,想了解更多请翻阅mycat权威指南,链接在顶部。
数字范围分片配置:
此分片适用于,提前规划好分片字段某个范围属于哪个分片, start <= range <= end. range start-end ,data node index K=1000,M=10000.
<tableRule name="auto-sharding-long"> <rule> <columns>user_id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <!--规则配置文件-->
<property name="mapFile">autopartition-long.txt</property>
<!--超出的范围记录在0号分片上-->
<property name="defaultNode">0</property> </function>
配置说明: 上面 columns 标识将要分片的表字段,algorithm 分片函数, rang-long 函数中 mapFile 代表配置文件路径 ,查看如下:

defaultNode 超过范围后的默认节点。 所有的节点配置都是从 0 开始,及 0 代表节点 1,此配置非常简单,即预先制定可能的 id 范围到某个分片 0-500M=0 500M-1000M=1 1000M-1500M=2 或 0-10000000=0 10000001-20000000=1。
取模分片:
此规则为对分片字段求摸运算。
<tableRule name="mod-long"> <rule> <columns>user_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">3</property> </function>
配置说明: 上面 columns 标识将要分片的表字段,algorithm 分片函数, 此种配置非常明确即根据 id 进行十进制求模预算,相比固定分片 hash,此种在批量插入时可能存在批量插入单 事务插入多数据分片,增大事务一致性难度。
分片取舍:
数据特点:活跃的数据热度较高规模可以预期,增长量比较稳定,首选 固定数量的离散分片规
数据特点:活跃的数据为历史数据,热度要求不高。规模可以预期,增长量比较稳定. 优势可定时清理或者迁移,连续分规则优先。
分片选择:
1,根据业务数据的特性合理选择分片规则。
2,善用全局表、ER关系表解决join操作。
3,用好primaryKey让你的性能起飞。
全局序列号:
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,MyCat 提供了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式。0 为本地文件方式,1 为数据库方式,2 为时间戳序列方式,3 为分布式 ZK ID 生成器,4 为 zk 递增 id 生成。 从 1.6 增加 两种 ZK 的全局 ID 生成算法。我这里主要介绍前3种,也是比较常用的方式。
本地文件方式: 原理:此方式 MyCAT 将 sequence 配置到文件中,当使用到 sequence 中的配置后,MyCAT 会更下 classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
配置方式: 在 sequence_conf.properties 文件中做如下配置:
GLOBAL_SEQ.HISIDS=
GLOBAL_SEQ.MINID=1001
GLOBAL_SEQ.MAXID=1000000000
GLOBAL_SEQ.CURID=1000
其中 HISIDS 表示使用过的历史分段(一般无特殊需要可不配置),MINID 表示最小 ID 值,MAXID 表示最大 ID 值,CURID 表示当前 ID 值。 server.xml 中配置:
<system><property name="sequnceHandlerType">0</property></system>
配置完可以登陆命令行监控工具查看配置信息:

注:sequnceHandlerType 需要配置为 0,表示使用本地文件方式。 使用示例:insert into users(userID,username,phoneNum) values(next value for MYCATSEQ_GLOBAL,‘本地全局序号’,'13858765412'); 缺点:当 MyCAT 重新发布后,配置文件中的 sequence 会恢复到初始值。 优点:本地加载,读取速度较快。看结果:
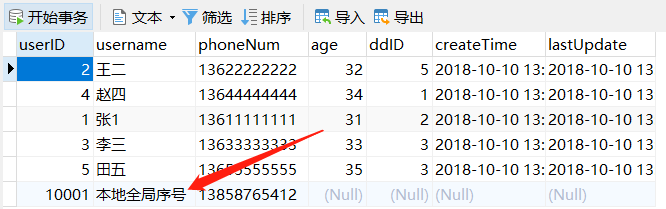
数据库方式:
在数据库中建立一张表,存放 sequence 名称(name),sequence 当前值(current_value),步长(increment int 类型每次读取多少个 sequence
server.xml 配置:sequnceHandlerType 需要配置为 1,表示使用数据库方式生成 sequence。
1.创建 MYCAT_SEQUENCE 表:
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE `MYCAT_SEQUENCE` (
`NAME` varchar(50) NOT NULL,
`current_value` int(11) NOT NULL,
`increment` int(11) NOT NULL DEFAULT '100',
PRIMARY KEY (`NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.创建相关的 FUNCTION ,返回当前的sequence的值:
DROP FUNCTION IF EXISTS mycat_seq_currval;
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval='-999999999,null';
SELECT concat(CAST(current_value AS CHAR),',',CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval;
END
设置sequence的值:
DROP FUNCTION IF EXISTS mycat_seq_setval;
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),value INTEGER) RETURNS varchar(64)
CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
获取下一个sequence的值:
DROP FUNCTION IF EXISTS mycat_seq_nextval;
CREATE FUNCTION mycat_seq_nextval ( seq_name VARCHAR ( 50 ) ) RETURNS VARCHAR ( 64 ) CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
创建完MYCAT_SEQUENCE 表跟3个FUNCTION 后需要配置 schema.xml,在指定的 schema中加入以下信息:dataNode表示你创建表跟函数的哪个节点配置
<table name = "mycat_sequence" dataNode ="db_user_dataNode1" />
然后配置 sequence_db_conf.properties 注释掉原来的所有东西,加入以下:这个USERS就是等等使用插入命令用的。
USERS=db_user_dataNode1
注意:MYCAT_SEQUENCE 表和以上的 3 个 function,需要放在同一个节点上。然后重启 mycat服务,执行 insert into users(userID,username,phoneNum) values(next value for MYCATSEQ_USERS,'数据库序列号','13858765412'); 。这个执行语句中 next value for MYCATSEQ_USERS 的USERS就是在 sequence_db_conf.properties 中配置的。结果如下。
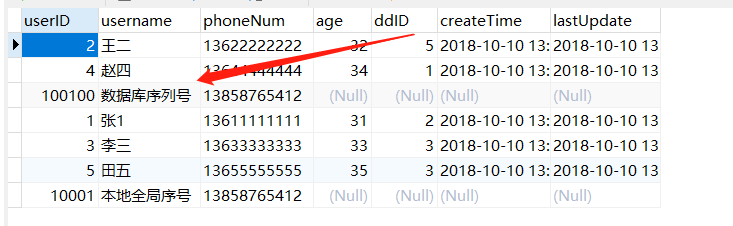
本地时间戳方式:
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
1.配置 server.xml :sequnceHandlerType 需要配置为 2.
2.在 mycat 下配置:sequence_time_conf.properties.
WORKID=0-31 任意整数
DATAACENTERID=0-31 任意整数
多个 mycat 节点下每个 mycat 配置的 WORKID,DATAACENTERID 不同,组成唯一标识,总共支持 32*32=1024 种组合。
3.在 schema.xml 的对应逻辑表位置配置 autoIncrement="true"。重启mycat服务,使用插入语句 insert into users(username,phoneNum) values("本地时间戳序列号","165498467684"); 注意这里需要把userID的长度设置成 bigint。不然会报错,结果如下:
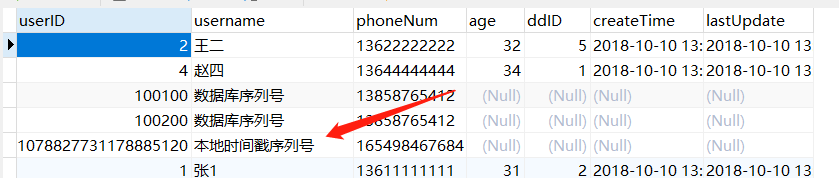
最后来看以下命令行监控工具:使用命令 mysql -uroot -p123456 -P9066 -h 192.168.254.138 这里的信息都是 mycat 的信息。进入控制台输入 show @@help; 查看命令:
可以通过这些命令查看所有你想获取的信息。
