通过之前的 Spring Cloud 组件学习, 实际上我们已经能够通过使用它们搭建起一 个基础的微服务架构系统来实现业务需求了。 但是, 随着业务的发展, 系统规模也会变得越来越大, 各微服务间的调用关系也变得越来越错综复杂。 通常 一 个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果, 在复杂的微服务架构系统中, 几乎每 一 个前端请求都会形成 一 条复杂的分布式服务调用链路, 在每条链路中任何 一 个依赖服务出现延迟过高或错误的时候都有可能引起请求最后的失败。这时候,对于每个请求, 全链路调用的跟踪就变得越来越重要, 通过实现对请求调用的跟踪可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等。针对上面所述的分布式服务跟踪问题, Spring Cloud Sleuth 提供了一 套完整的解决方案。 在本文中, 我们将详细介绍如何使用 Spring Cloud Sleuth 来为微服务架构增加分布式服务跟踪的能力。
快速入门(实现跟踪):
在引入 Sleuth 之前, 我们先按照之前章节学习的内容来做 一 些准备工作, 构建 一 些基础的设施和应用。
- 服务注册中心: eureka-server, 这里不做赘述, 直接使用之前构建的工程即可。
- 微服务应用: trace-1, 实现 一 个 REST 接口 /trace-1, 调用该接口后将触发对 trace-2 应用的调用。 具体实现如下所述。
1.创建 一 个基础的 Spring Boot 应用, 在 pom.xml 中增加下面的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
2.实现 /trace-1 接口, 并使用 RestTemplate 调用 trace-2应用的接口。 具体如下:
@Configuration
public class ConfigBean {
@Bean
@LoadBalanced // ribbon是客户端 的负载均衡工具
//默认算法是轮询算法 核心组件IRule
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
}
@RestController
public class TestController {
private final Logger logger = Logger.getLogger(getClass().getName());
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/trace-1", method = RequestMethod.GET)
public String trace() {
logger.info(" === call trace- 1 === ");
return restTemplate.getForEntity("http://trace-2/trace-2", String.class).getBody();
}
}
3.添加主类:
@SpringBootApplication
@EnableDiscoveryClient
public class Trace1App {
public static void main(String[] args) {
SpringApplication.run(Trace1App.class, args);
}
}
4.增加配置
server.port = 9101
eureka.client.serviceUrl.defaultZone = http://localhost:7001/eureka/,http://localhost:7002/eureka/
spring.application.name = trace-1
5. 创建 一 个基础的 Spring Boot 微服务应用:trace-2, 实现 一 个 REST 接口 /trace-2, 供 trace-1 调用。pom.xml 中的依赖与 trace-1 相同。
@RestController
public class TestController {
private final static Logger log = LoggerFactory.getLogger(TestController.class);
@RequestMapping(value = "/trace-2", method = RequestMethod.GET)
public String trace() {
log.info(" = = = <call trace-2> == = ");
return " Return ===call trace-2 === ";
}
}
6.配置如下
server.port = 9102
eureka.client.serviceUrl.defaultZone = http://localhost:7001/eureka/,http://localhost:7002/eureka/
spring.application.name = trace-2
在实现了上面的内容之后, 我们可以将 eureka-server、 trace-1、 trace-2应用都启动起来, 并对 trace-1 的接口发送请求http://localhost:9101/trace-1 。 可以得到返回值 Trace.
7.实现跟踪,在完成了准备工作之后, 为上面的 trace-1和 trace-2 添加服务跟踪功能。 通过 Spring Cloud Sleuth 的封装, 我们为应用增加服务跟踪能力的操作非常简单, 只需在 trace-1 和 trace-2 的 porn.xrnl 依赖管理中增加spring-cloud-starter-sleuth 依赖即可,具体如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
到这里, 实际上我们已经为 trace-1 和 trace-2 实现服务跟踪做好了基础的准备,重启 trace-1 和 trace-2, 再对 trace-1 的接口发送请求 http://localhost:9101/ trace-1 。 此时, 我们可以从它们的控制台输出中窥探到 Sleuth 的 一 些端倪。

从上面的控制台输出内容 中 , 我 们可 以看到多了一些形如[[trace-1,dfb2da015596c556,864c49f71578d260,false]的日志信息, 而这些元素正是实现分布式服务跟踪的重要组成部分,每个值的含义如下所述。
- 第一 个值: trace-1, 它记录了应用的名称,也就是 application.properties中 spring.application.name参数配置的属性。
- 第二个值: dfb2da015596c556, Spring Cloud Sleuth生成的 一 个ID,称为Trace ID,它用来标识 一 条请求链路。一 条请求链路中包含 一 个TraceID, 多个SpanID。
- 第三个值: 864c49f71578d260, Spring Cloud Sleuth生成的另外 一 个ID, 称为Span ID, 它表示 一 个基本的工作单元, 比如发送 一 个HTTP请求。
- 第四个值: false, 表示是否要将该信息输出到Zipkin等服务中来收集和展示 。
上面四个值中的TraceID和SpanID是Spring Cloud Sleuth实现分布式服务跟踪的核心。 在 一 次服务请求链路的调用过程中, 会保待并传递同 一 个Trace ID, 从而将整个分布于不同微服务进程中的请求跟踪信息串联起来。 以上面输出内容为例, trace-1 和 trace-2同属于 一 个前端服务请求来源,所以它们的TraceID是相同的,处于同 一 条请求链路中。
跟踪原理:
分布式系统中的服务跟踪在理论上并不复杂, 它主要包括下面两个关键点。
- 为了实现请求跟踪, 当请求发送到分布式系统的入口端点时, 只需要服务跟踪框架为该请求创建 一 个唯 一 的跟踪标识, 同时在分布式系统内部流转的时候,框架始终保待传递 该唯 一 标识, 直到返回给请求方为止, 这个唯 一 标识就是前文中提到的Trace ID。 通过TraceID的记录, 我们就能将所有请求过程的日志关联起来。
- 为了统计各处理单元的时间延迟, 当请求到达各个服务组件时, 或是处理逻辑到达某个状态时,也通过 一 个唯 一 标识来标记它的开始、 具体过程以及结束, 该标识就是前文中提到的SpanID。 对于每个Span来说, 它必须有开始和结束 两个节点, 通过记录开始 Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含 一 些其他元数据, 比如事件名称、 请求信息等。
抽样收集:
通过Trace ID和Span ID已经实现了对分布式系统中的请求跟踪, 而记录的跟踪信息最终会被分析系统收集起来, 并用来实现对分布式系统的监控和分析功能, 比如, 预警延迟过长的请求链路、 查询请求链路的调用明细等。 此时, 我们在对接分析系统时就会碰到一个问题: 分析系统在收集跟踪信息的时候, 需要收集多少跟踪信息才合适呢?理论上来说, 我们收集的跟踪信息越多就可以越好地反映出系统的实际运行情况, 并给出更精准的预警和分析。 但是在高并发的分布式系统运行时, 大量的请求调用会产生海量的跟踪日志信息, 如果收集过多的跟踪信息将会对整个分布式系统的性能造成 一 定的影响, 同时保存大量的日志信息也需要不少的存储开销。 所以, 在 Sleuth 中采用了抽象收集的方式来为跟踪信息打上收集标记,也就是我们之前在日志信息中看到的第4个布尔类型的值,它代表了该信息是否要被后续的跟踪信息收集器获取和存储。
Sleuth 中的抽样收集策略是通过 Sampler (1.3.5.RELEASE)抽象类实现的,通过实现 isSarnpled 方法, Spring Cloud Sleuth 会在产生跟踪信息的时候调用它来为跟踪信息生成是否要被收集的标志。 需要注意的是, 即使 isSampled 返回了 false, 它仅代表该跟踪信息不被输出到后续对接的远程分析系统(比如 Zipkin), 对于请求的跟踪活动依然会进行,所以我们在日志中还是能看到收集标识为 false 的记录。默认情况下, Sleuth 会使用 PercentageBasedSarnpler 实现的抽样策略,以请求百分比的方式配置和收集跟踪信息。 我们可以通过在 application.properties 中配置
下面的参数对其百分比值进行设置, 它的默认值为0 .1, 代表收集10%的请求跟踪信息。
spring.sleuth.sampler.percentage = 0.1
与Logstash整合:
通过之前的准备与整合,我们已经为trace-1和trace-2引入了Spring Cloud Sleuth的基础模块spring-cloud-starter-sleuth, 实现了在各个微服务的日志信息中添加跟踪信息的功能。 但是, 由于日志文件都离散地存储在各个服务实例的文件系统之上, 仅仅通过查看日志文件来分析我们的请求链路依然是 一 件相当麻烦的事, 所以我们还需要 一些工具来帮助集中收集、 存储和搜索这些跟踪信息。 引入基于日志的分析系统是 一 个不错的选择, 比如ELK平台, 它可以轻松地帮助我们收集和存储这些跟踪日志, 同时在需要的时候我们也可以根据Trace ID来轻松地搜索出对应请求链路 相关的明细日志。
ELK平台主要由ElasticSearch、 Logstash和 Kibana三个开源工具组成。
- ElasticSearch是 一 个开源分布式搜索引擎, 它的特点有: 分布式, 零配置, 自动发现, 索引自动分片, 索引副本机制,RESTful风格接口, 多数据源, 自动搜索负载等。
- Logstash是 一 个完全开源的工具, 它可以对日志进行收集、 过滤, 并将其存储供以后使用。
- Kibana 也是 一 个开源和免费的工具, 它可以为Logstash 和ElasticSearch提供日志分析友好的Web界面, 可以帮助汇总、 分析和搜索重要数据日志。Spring Cloud Sleuth 在与ELK平台整合使用时, 实际上只要实现与负责日志收集的Logstash完成数据对接即可, 所以我们需要为Logstash准备JSON格式的日志输出。 由于Spring Boot 应用默认使用logback来记录日志,而Logstash自身也有对logback日志工具的支持工具, 所以我们可以直接通过在logback的配置中增加对Logstash的Appender, 就能非常方便地将日志转换成以JSON的格式存储和输出了。
下面我们来详细介绍 一 下在快速入门示例的基础上, 如何实现面向Logstash的日志输出配置。
1.在pom.xml依赖中引入logstash-logback-encoder依赖, 具体如下:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions><!-- 去掉springboot默认配置 -->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.6</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.1.11</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.11</version>
</dependency>
</dependencies>
2.在工程 /resource 目录下创建 bootstrap.properties 配置文件,将 spring.application.name = trace-1 配置移动到该文件中去。由于 logback-spring.xml 的加载在 application.properties 之前, 所以之前的配置 logbackspring.xml 无法获取 spring.application.name 属性, 因此这里将该属性移动到最先加载的 bootstrap.properties 配置文件中。
3.在工程 /resource 目录下创建 logback 配置文件 logback-spring.xml, 具体内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="sleuth" source="spring.application.name"/>
<!-- 日志在工程中的输出位置 -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${sleuth}"/>
<!-- 控制台的日志输出样式 -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${sleuth:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- 控制台Appender -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- 为logstash输出的json格式的Appender -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${sleuth:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="logstash"/>
</root>
</configuration>
完成上面的改造之后, 我们再将快速入门的示例运行起来, 并发起对 trace-1 的接口访间。 此时可以在 trace-1 和 trace-2 的工程目录下发现有 一 个 build 目录, 下面分别创建了以各自应用名称命名的 JSON 文件, 该文件就是在 logback-spring.xml中配置的名为 logstash 的 Appender 输出的日志文件,其中记录了类似下面格式的 JSON:
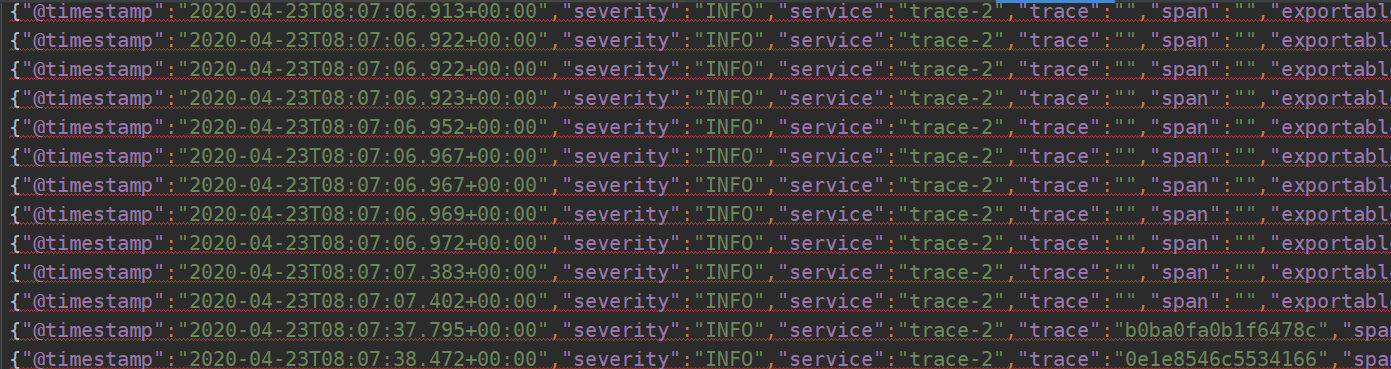
与Zipkin整合:
虽然通过 ELK 平台提供的收集、存储、 搜索等强大功能, 我们对跟踪信息的管理和使用已经变得非常便利。但是,在 ELK 平台中的数据分析维度缺少对请求链路中各阶段时间延迟的关注, 很多时候我们追溯请求链路的 一 个原因是为了找出整个调用链路中出现延迟过高的瓶颈源, 或为了实现对分布式系统做延迟监控等与时间消耗相关的需求, 这时候类似 ELK 这样的日志分析系统就显得有些乏力了。 对于这样的问题, 我们就可以引入 Zipkin来得以轻松解决。
下图展示了 Zipkin 的基础架构, 它主要由 4 个核心组件构成。
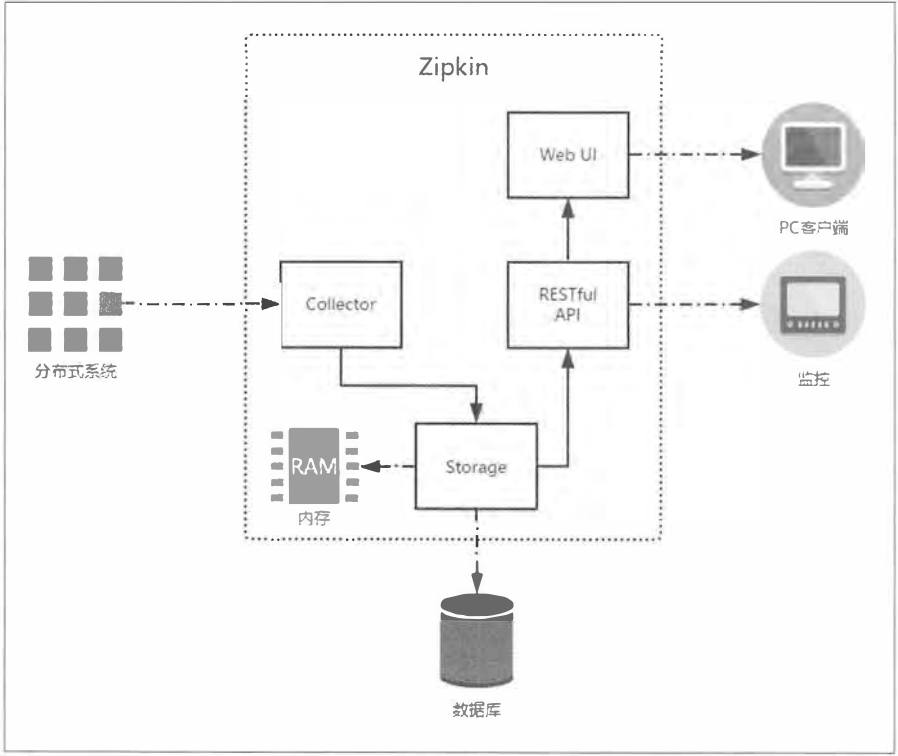
- Collector: 收集器组件, 它主要处理从外部系统发送过来的跟踪信息, 将这些信息转换为Zipkin内部处理的Span格式, 以支待后续的存储、 分析、 展示等功能。
- Storage: 存储组件, 它主要处理收集器接收到的跟踪信息, 默认会将这些信息存储在内存中。 我们也可以修改此存储策略, 通过使用其他存储组件将跟踪信息存储到数据库中。
- RESTful API: API组件, 它主要用来提供外部访问接口。 比如给客户端展示跟踪信息, 或是外接系统访问以实现监控等。
- Web UI: UI组件, 基于API组件实现的上层应用。 通过UI组件, 用户可以方便而又直观地查询和分析跟踪信息。
HTTP收集:
在Spring Cloud Sleuth中对Zipkin的整合进行了自动化配置的封装, 所以我们可以很轻松地引入和使用它。 下面我们来详细介绍 一 下Sleuth与Zip如n的基础整合过程, 主要分为以下两步。
1.创建 一 个基础的 Spring Boot 应用, 命名为 zipkin-server, 并在 pom.xml 中引入 Zipkin Server 的相关依赖, 具体如下:
<dependencies>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.11.8</version>
</dependency>
</dependencies>
2.创建应用主类 ZipkinApplication, 使用 @EnableZipkinServer 注解来启动Zipkin Server, 具体如下:
@SpringBootApplication
@EnableZipkinServer
public class ZikpinApp {
private final static Logger log = LoggerFactory.getLogger(ZikpinApp.class);
public static void main(String[] args) {
SpringApplication.run(ZikpinApp.class, args);
log.info("服务启动成功");
}
}
3.在application.properties中做一 些简单配置,比如设置 服务端口号为9411(客户端整合时,自动化配置会连接9411端口,所以在服务端设置了端口为9411的话, 客户端可以省去这个配置)。
spring.application.name=zipkin-server
server.port=9411
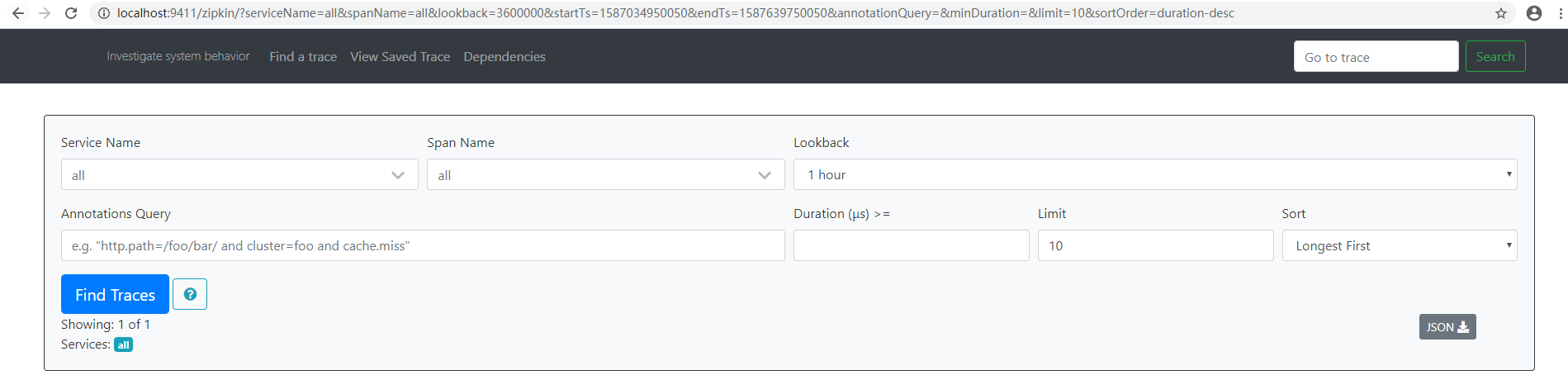
4.创建完上述工程之后, 我们将其启动起来,并访问http://localhost: 9411/, 可以看到如下图所示的Zipkin管理页面:
第二步: 为应用引入和配置Zipkin服务
在完成了Zipkin Server的搭建之后, 我们还需要对应用做一 些配置, 以实现将跟踪信息输出到ZipkinServer。 我们以之前实现的七race-1和trace-2为例, 对它们做以下改造。
1.在trace-1和trace-2的pom.xml中引入spring-cloud-sleuth-zipkin依赖, 具体如下所示。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
2.在trace-1和trace-2的application.properties中增加ZipkinServer的配置信息,具体如下所示(如果在zip-server应用中,我们将其端口设置为9411,并且均在本地调试的话, 也可以不配置该参数, 因为默认值就是http://localhost:9411)。
spring.zipkin.base-url=http://localhost:9411
测试与分析:
到这里我们已经完成 了接入 Zipkin Server 的所有基本工作,可以继续将eureka-server、 trace-1和trace-2启动起来, 然后做一 些测试,以对它的运行机制有 一 些初步的理解。我们先来向trace-1的接口发送几个请求http://localhost: 9101/trace-1。当在日志中出现 跟踪信息的最后 一 个值为true的时候, 说明该跟踪信息会输出给ZipkinServer, 所以此时可以在ZipkinServer的管理页面中选择合适的查询条件, 单击FindTraces按钮, 就可以查询出刚才在日志中出现的跟踪信息了(也可以根据日志中的TraceID, 在页面右上角的输入框中来搜索), 页面如下所示。

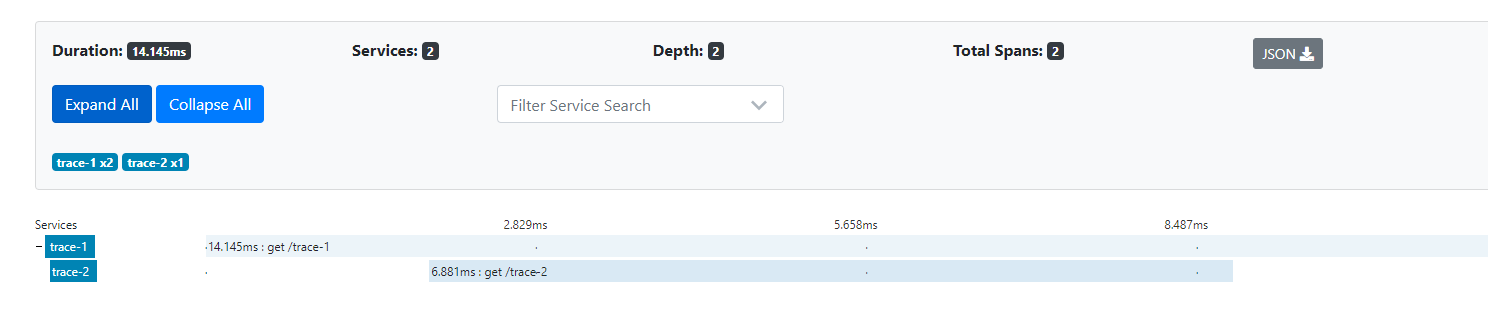
单击下方trace-1端点的跟踪信息, 还可以得到Sleuth跟踪到的详细信息, 其中包括我们关注的请求时间消耗等。
单击导航栏中的Dependencies菜单, 还可以查看ZipkinServer根据跟踪信息分析生成的系统请求链路依赖关系图, 如下图所示。

其他关于RabbitMQ收集就不说明了 ,springboot2.0以后官方不建议自己搭建 Zipkin-Server,建议使用 Jar 运行,详细可以查询官方文档。这个东西的说明以及最新版本的配置的资料不多,先到者,以后有需要了再深入看看。