先来简单了解下redis中提供的集群策略, 虽然redis有持久化功能能够保障redis服务器宕机也能恢复并且只有少量的数据损失,但是由于所有数据在一台服务器上,如果这台服务器出现硬盘故障,那就算是有备份也仍然不可避免数据丢失的问题。在实际生产环境中,我们不可能只使用一台redis服务器作为我们的缓存服务器,必须要多台实现集群,避免出现单点故。
Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
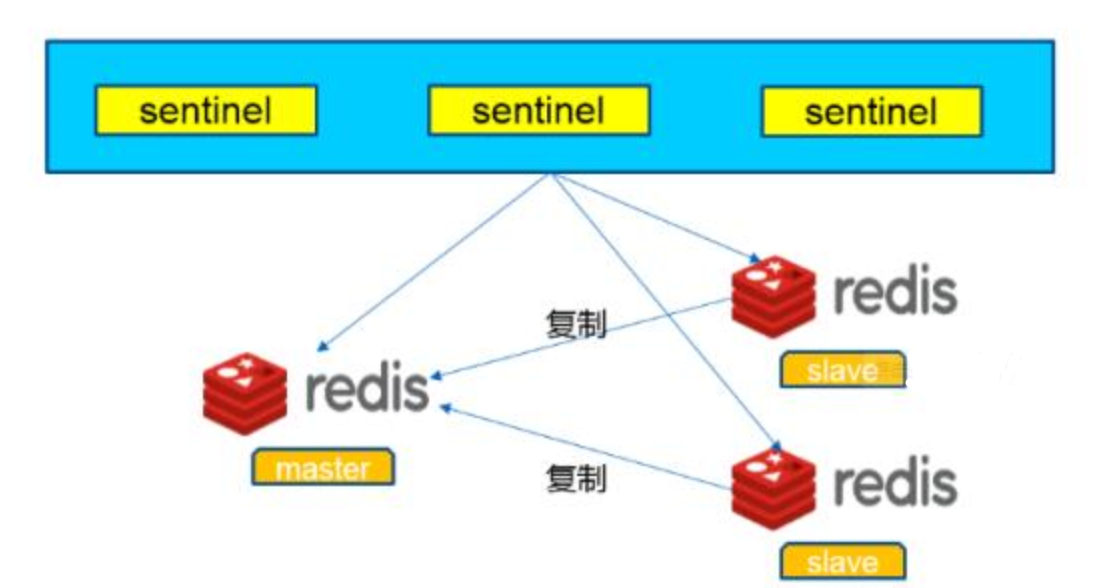
如上图所示,我们可以将一台redis服务器作为主库,多台其他的服务器作为从库,主库只负责写数据,从库负责读数据,当主库数据更新时,会同步到它所有的从库。这就实现了主从复制,读写分离。既可以解决服务器负载过大的问题,又能够在一台服务器发生故障时及时使用其他服务器恢复数据。
下面演示一下redis中的主从复制,首先我们创建三份配置文件,分别对应端口号6379,6380,6381开启三个redis服务:
可以看到目前下面3台服务的角色(role)是master,也就是目前没有主从关系。

由于我们现在没有配置主从库,所以可以通过命令info replication看到,三台服务器都分别是独立的主库。现在我们将端口号6379配置为主库(master),将端口号6380和6381配置为6379的从库,配置方法为在从库中执行命令:SLAVEOF 主库IP地址 主库端口号,或者直接在从机的配置文件中配置 SLAVEOF 主库IP地址 主库端口号,然后重启

执行完SLAVEOF 命令以后我们再使用INFO REPLICATION 查看当前3台服务的关系,可以看到79服务为master ,其他两台为slave,说明主从关系建立完成,这里有个注意的点,就是在两台从机的配置文件里需要配置 masterauth password 主机密码,不然在建立主从关系的时候会提示认证失败。

可以看到一开始3台服务的库里都是空的,在主机上set 值以后,可以直接在从机上get,可以看到下图,当在从机上set值的时候会报错,这是为什么呢?
默认情况下,从库只能读取数据,执行写操作会报错:可以修改配置文件中的以下参数来配置从机是只读还是可写,这里推荐设置成yes 只读。

slave-read-only yes

将从库升级为独立的主库:
SLAVEOF NO ONE
如果主库宕机,从库会“原地待命”,待主库重新连接之后,会恢复和主库的联系:
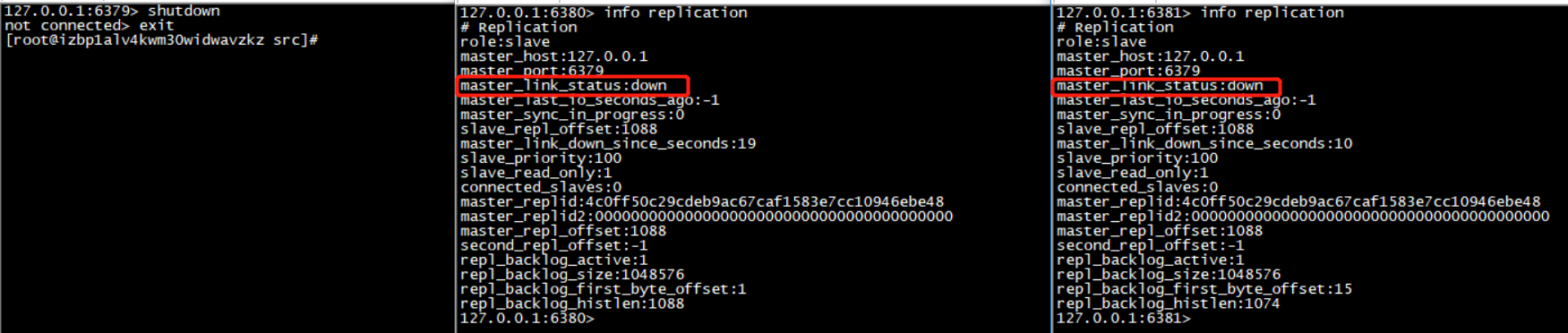
当主机重新启动,他依然会回到自己原先的角色,而自己的从机也依然在苦苦等待他回来,一旦发现他回来了,从机依然会在他手下效劳,但是,如果从库宕机,连接会断开,当从库重新连接后,需要重新建立与主库的连接: 如下图:
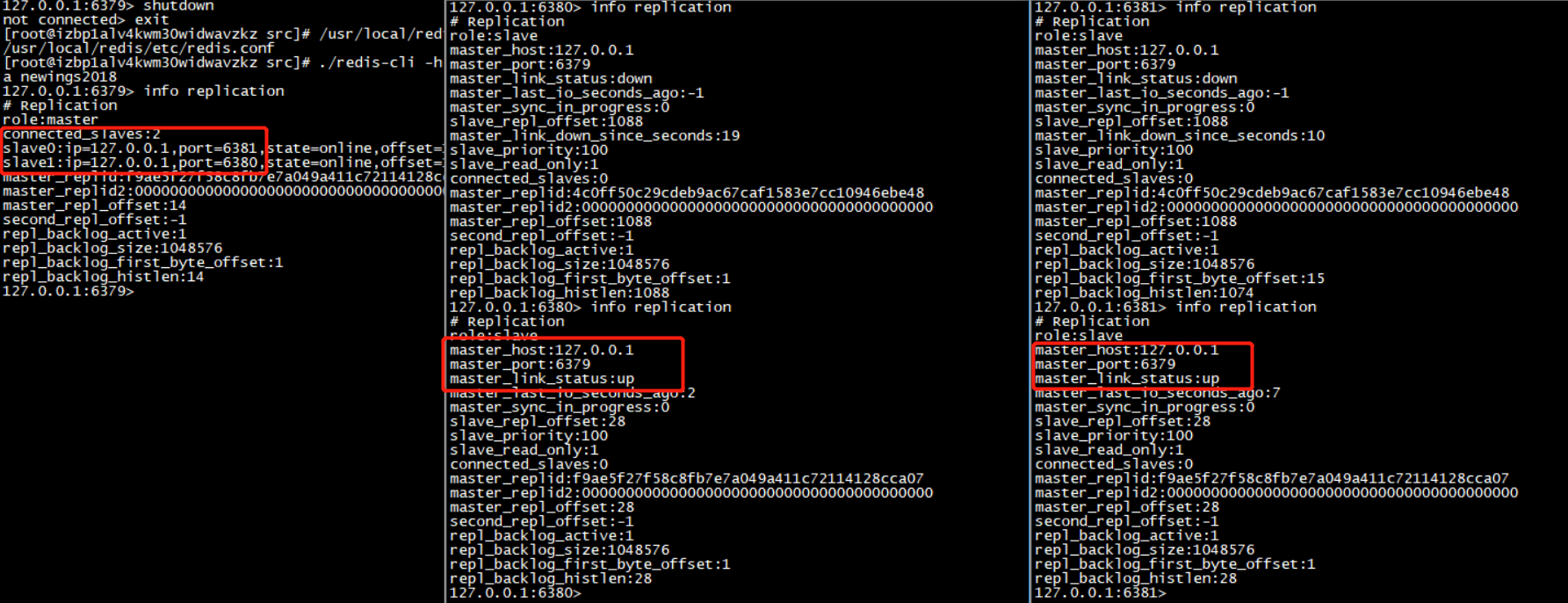
一个库可以是一个库的从库,同时也可以是另一个库的主库,这样可以有效减轻master的压力,避免所有的从库都从一个主库中读取数据:

主从复制的原理:
主库master和从库slave的复制分为全量复制和增量复制:
全量复制:全量复制一般发生在slave初始化阶段,此时slave需要将master上的所有数据都复制一份,具体步骤如下:
- 从库连接到主库,并发送一条SYNC命令;
- 主库接收到SYNC命令后,开始执行BGSAVE命令生成RDB快照文件,并使用缓冲区记录此后执行的所有写命令;
- 主库执行完BGSAVE之后,将快照文件发送到所有从库,在此期间,仍继续将所有写命令记录到缓冲区;
- 从库在接收到快照文件后,丢弃所有旧数据,载入快照文件中的新数据;
- 主库继续向从库发送缓冲区中的写命令;
- 从库将快照文件中的数据载入完毕后,继续接收主库发送的缓冲区中的写命令,并执行这些写命令以更新数据。
完成上面的步骤之后,从库可以开始接收来自用户的读数据请求。增量复制:增量复制是指,在slave初始化完成后的工作阶段,主库将新发生的写命令同步到从库的过程。主库每执行一条写命令,都会向从库发送相同的写命令,从库会执行这些写命令。
总结:主库和从库初次建立连接时,进行全量复制;全量复制结束后,进行增量复制。但是当增量复制不成功时,需要发起全量复制。
主从复制的不足:
主从模式解决了数据备份和性能(通过读写分离)的问题,但是还是存在一些不足:
- RDB 文件过大的情况下,同步非常耗时。
- 在一主一从或者一主多从的情况下,如果主服务器挂了,对外提供的服务就不可用了,单点问题没有得到解决。如果每次都是手动把之前的从服务器切换成主服务器,这个比较费时费力,还会造成一定时间的服务不可用。
哨兵模式:
哨兵模式是通过后台监控主库是否故障,当主库发生故障时,将根据投票数自动将某一从库转换为主库。
sentinel monitor host6399 192.168.254.137 6399 1 --配置监控的master节点
sentinel down-after-milliseconds host6399 5000 --表示如果5s内mymaster没响应,就认为SDOWN
protected-mode no -- 禁止保护
daemonize yes -- 后台运行
logfile "/var/log/sentinel_log.log"
sentinel failover-timeout host6399 15000 --表示如果15秒后,mysater仍没活过来,则启动failover,从剩下的slave中选一个升级为master
sentinel auth-pass host6399 wuzhenzhao -- 密码
然后通过 /usr/local/redis/bin/redis-sentinel /usr/local/redis/etc/sentinel.conf 启动哨兵会出现以下信息:
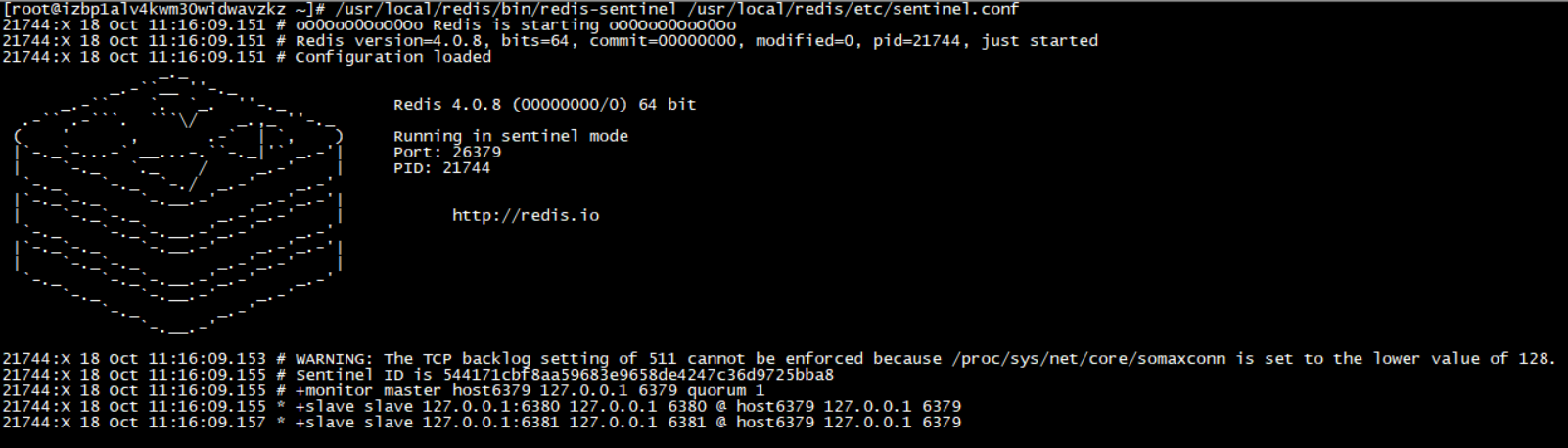
此刻说明哨兵已经启动,接下去我让主机 6379 宕机,来演示主机宕机以后从机的反客为主。
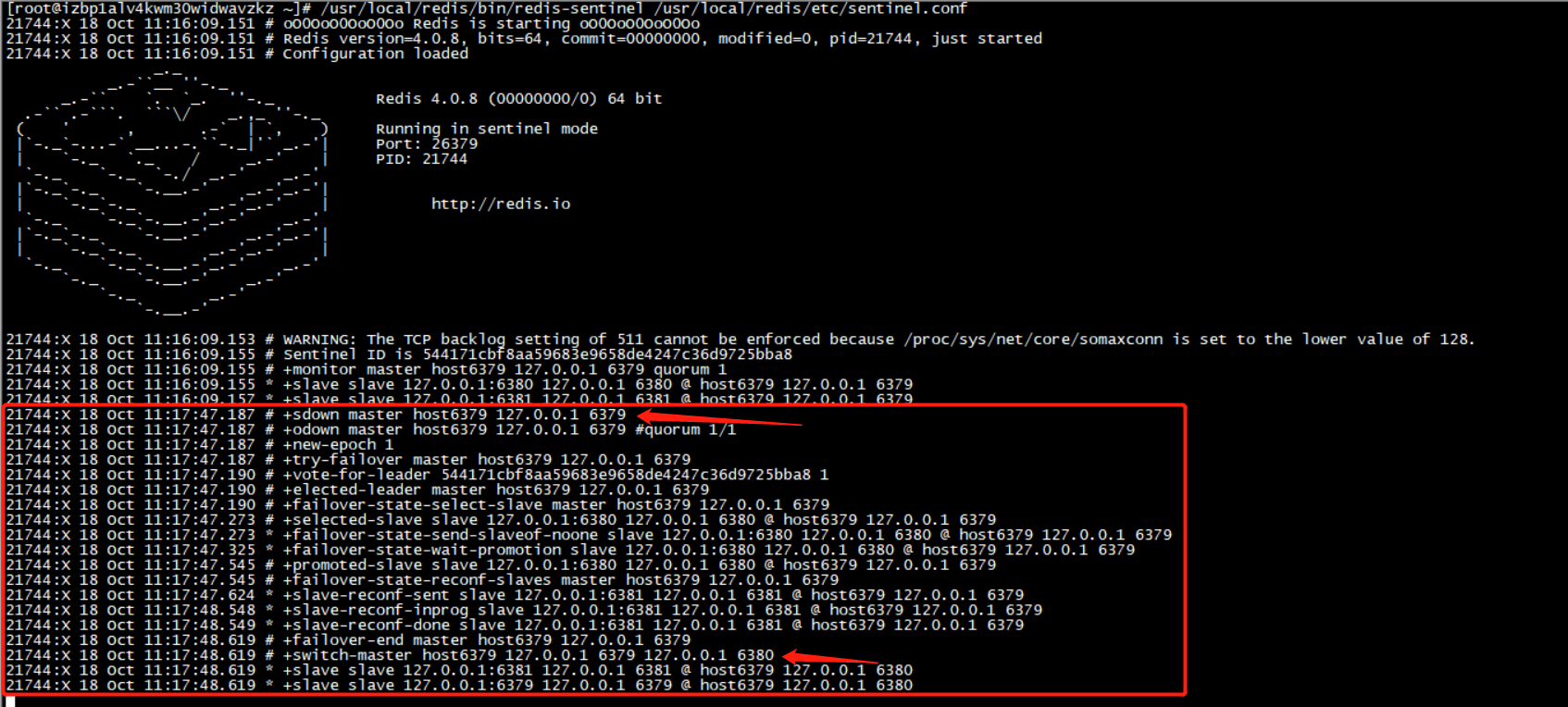
可以看到当主机宕机后,经过哨兵监控,发现主机宕机,会根据事先的配置文件里规则去选举新的master。这里选出来的是6380,如下图: 
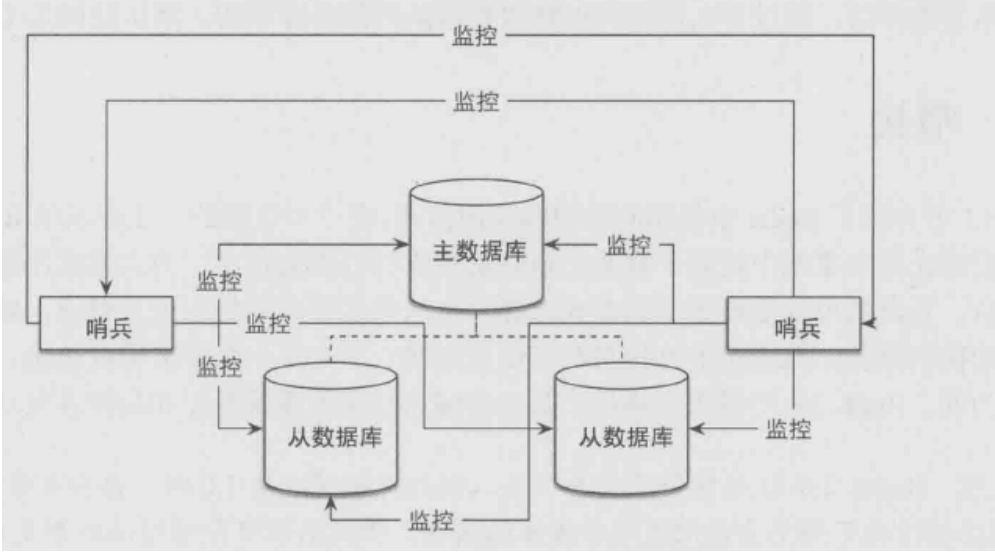
- 需要相互感知的sentinel都向他们共同监视的master节点订阅channel:sentinel:hello
- 新加入的sentinel节点向这个channel发布一条消息,包含自己本身的信息,这样订阅了这个channel的sentinel就可以发现这个新的sentinel
- 新加入得sentinel和其他sentinel节点建立长连接
哨兵机制的不足:
主从切换的过程中会丢失数据,因为只有一个 master。只能单点写,没有解决水平扩容的问题。如果数据量非常大,这个时候我们需要多个 master-slave 的 group,把数据分布到不同的 group 中。
public class JedisSentinelTest { private static JedisSentinelPool pool; private static JedisSentinelPool createJedisPool() { // master的名字是sentinel.conf配置文件里面的名称 String masterName = "redis-master"; Set<String> sentinels = new HashSet<String>(); sentinels.add("192.168.1.101:26379"); sentinels.add("192.168.1.102:26379"); sentinels.add("192.168.1.103:26379"); pool = new JedisSentinelPool(masterName, sentinels); return pool; } public static void main(String[] args) { JedisSentinelPool pool = createJedisPool(); pool.getResource().set("name", "qq"+System.currentTimeMillis()); System.out.println(pool.getResource().get("name")); } }