zoukankan
html css js c++ java
Python爬虫学习==>第六章:爬虫的基本原理
学习目的:
掌握爬虫相关的基本概念
正式步骤
Step1:什么是爬虫
请求网站并提取数据的自动化程序
Step2:爬虫的基本流程
Step3:Request和Response
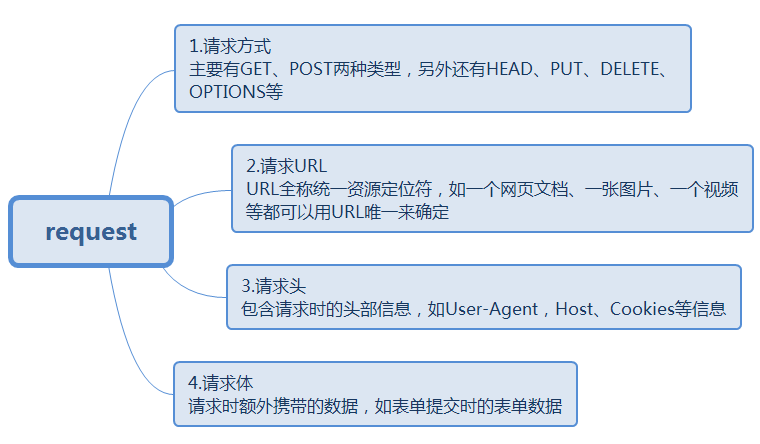
1.request
2.response
Step4:能抓怎样的数据
Step5:怎么样来解析
Step6:怎样保存数据
学习总结:
结构化的爬虫还需要学很多,还有Python的基础技能要进一步学习,多应用才能巩固
查看全文
相关阅读:
js中两种定时器,setTimeout和setInterval的区别
简单说 JavaScript实现雪花飘落效果
CSS 浮动 float 属性
使用jQuery做简单的图片轮播效果
DIV+CSS中标签dl dt dd常用的用法
CSS display的几个常用的属性值,inline , block, inline-block
Confluence代码块(Code Block)宏
salt总结
快速搭建rabbitmq单节点并配置使用
使用python脚本配置zabbix发送报警邮件
原文地址:https://www.cnblogs.com/wuzhiming/p/8698659.html
最新文章
<<< java如何调用系统程序
<<< Oracle序列的创建、修改、删除基本操作
<<< Oracle表创建、修改、删除基础操作
<<< Oracle表空间创建、修改、删除基本操作
<<< Oracle系统参数命令、服务进程、默认用户
<<< 将一个rar格式的文件变成一张jpg图片,按照后缀来选择打开他的模式
TCP/IP协议的工作流程
TCP粘包和拆包的定义,产生的原因以及解决方案
UDP中一个包的大小最大能多大?TCP呢?
Spring MVC原理图及其重要组件
热门文章
Java/C++ 学习资源推荐
TCP协议的11种状态及其变化过程?传输的内容又是什么?
TCP协议有几大计时器?
使用TCP的协议有哪些?使用UDP的协议有哪些?
TCP报文格式+UDP报文格式+MAC帧格式
【面试】IP数据报格式分析
VS Code 的常用快捷键
理解与应用css中的display属性
为什么要在<button>元素中添加type属性
如何在网页中添加 jQuery。
Copyright © 2011-2022 走看看