numpy
numpy: 专门数组(矩阵)的运算
lis1 = [1, 2, 3] # 向量
lis2 = [4, 5, 6] # 向量
import numpy as np
arr1 = np.array([1,2,3])
arr2 = np.array([4,5,6])
print(arr1*arr2) #[ 4 10 18]
import numpy as np
numpy数组
arr = np.array([1, 2, 3])
print(arr) # 一维的numpy数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
arr3 = np.array([[[1, 2, 3], [4, 5, 6]],[[1, 2, 3], [4, 5, 6]],[[1, 2, 3], [4, 5, 6]]])
print(arr3)
三维的不使用numpy模块,使用tensorflow/pytorch模块
属性(可以记)
'''
T 数组的转置(对高维数组而言)
dtype 数组元素的数据类型
size 数组元素的个数
ndim 数组的维数
shape 数组的维度大小(以元组形式)
astype 类型转换
'''
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
print(arr2.T) # 行与列互换
print(arr2.dtype) # python中的数据类型,
print(arr2.astype(np.float64).dtype)
print(arr2.size)
print(arr2.shape)
print(arr2.ndim)
切片
lis = [1,2,3]
print(lis[:])
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
print(arr2[:, :])
print(arr2[0:1, :])
print(arr2[0:1, 0:1])
print(arr2[0, :])
print(arr2[0, 0],type(arr2[0, 0]))
print(arr2[0, [0,2]])
print(arr2[0, 0] + 1)
修改值
lis = [1,2,3]
lis[0] = 2
print(lis)
arr2 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr2) # 二维的numpy数组(一般就是二维)
arr2[0, :] = 0
print(arr2)
arr2[1, 1] = 1
print(arr2)
arr2[arr2 < 3] = 3 # 布尔取值
print(arr2)
合并
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr1)
arr2 = np.array([[7, 8, 9], [10, 11, 12]]) # 可变数据类型
print(arr2)
print(np.hstack((arr1,arr2))) # 行合并
print(np.vstack((arr1,arr2))) # 列合并
print(np.concatenate((arr1, arr2))) # 默认列合并
print(np.concatenate((arr1, arr2),axis=1)) # 1表示行;0表示列
通过函数创建numpy数组
print(np.zeros((5, 5)))
print(np.ones((5, 5)) * 100)
print(np.eye(5))
print(np.arange(1,10,2)) # 生成一维的
print(np.linspace(0,20,10)) # 平均分成10份 # 构造x坐标轴的值
arr = np.zeros((5, 5))
print(arr.reshape((1,25))) #重新排列数组,size要一样
数组运算
+-*/ // % **
print(arr1*arr2)
print(arr1+arr2)
运算函数
print(np.sin(arr1))
print(np.cos(arr1))
print(np.sqrt(arr1))
print(np.exp(arr1))
额外补充(了解)
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr1)
arr2 = np.array([[7, 8, 9], [10, 11, 12]]) # 可变数据类型
print(arr2)
print(arr1.T)
print(arr1.transpose())
m*n × n*m = m*m
print(np.dot(arr1,arr2.T))
求逆
arr1 = np.array([[1, 2, 3], [4, 5, 6], [9, 8, 9]])
print(np.linalg.inv(arr1))
numpy的数学方法(了解)
print(arr1.var())
print(arr1.std())
print(arr1.mean())
print(arr1.cumsum()) # 累加和
numpy随机数(了解)
print(np.random.rand(3,4))
print(np.random.randint(1,10,(3,4))) # 最小值1,最大值10,3*4
print(np.random.choice([1,2,3,4,5],3))
print(arr1)
np.random.shuffle(arr1)
print(arr1)
随机数种子 # 所有的随机数是按照随机数中子生成的
import time
重点
np.random.seed(int(time.time()))
np.random.seed(1)
arr1 = np.random.rand(3,4) # 可变数据类型
print(arr1)
rs = np.random.RandomState(1)
print(rs.rand(3,4))
以上只是numpy中基础中的基础,如果想细学,https://docs.scipy.org/doc/numpy/reference/?v=20190307135750
<利用Python进行数据分析> pandas作者写的
pandas
pandas更多的是excel/csv文件处理,excel文件, 对numpy+xlrd模块做了一层封装
pandas的数据类型
import pandas as pd
import numpy as np
# Series(现在一般不使用(一维))
df = pd.Series(np.array([1,2,3,4]))
print(df)
# DataFrame(多维)
dates = pd.date_range('20190101', periods=6, freq='M')
print(dates)
values = np.random.rand(6, 4) * 10
print(values)
columns = ['c1','c2','c3','c3']
df = pd.DataFrame(values,index=dates,columns=columns)
print(df)
'''
dtype 查看数据类型
index 查看行序列或者索引
columns 查看各列的标签
values 查看数据框内的数据,也即不含表头索引的数据
describe 查看数据每一列的极值,均值,中位数,只可用于数值型数据
transpose 转置,也可用T来操作
sort_index 排序,可按行或列index排序输出
sort_values 按数据值来排序
'''
print(df.dtypes)
print(df.index)
print(df.columns)
print(df.describe())
print(df.T)
import pandas as pd
import numpy as np
dates = pd.date_range('20190101', periods=6, freq='M')
print(dates)
values = np.random.rand(6, 4) * 10
print(values)
columns = ['c4','c2','c3','c1']
df = pd.DataFrame(values,index=dates,columns=columns)
df.T
df = df.sort_index(axis=1) # 0列,1是行
df
df.sort_values('c3') #按列C3的值排序
#取值
df['c1']
df[['c1','c3']]
df.loc['2019-01-31':'2019-02-28']
df.values[1,1]
df.iloc[:,:]
df[df['c1']>3]
#值替换
df.iloc[1,1] = 1
#pandas操作表格
from io import StringIO
test_data = '''
5.1,,1.4,0.2
4.9,3.0,1.4,0.2
4.7,3.2,,0.2
7.0,3.2,4.7,1.4
6.4,3.2,4.5,1.5
6.9,3.1,4.9,
,,,
'''
print(test_data)
test_data = StringIO(test_data) # 把test_data读入内存,相当于变成文件
print(test_data)
#把数据读入内存,变成csv文件
df = pd.read_csv('test.csv', header=None) #读取文件 # header没有columns
df.columns =['c1','c2','c3','c4']
df
#缺失值处理
df = df.dropna(axis=0) # 1列,0行
df = df.dropna(thresh=3) # 必须得有4个值
#合并处理
df1 = pd.DataFrame(np.zeros((2,3)))
df2 = pd.DataFrame(np.ones((2,3)))
pd.concat((df1,df2),axis=1) # 默认按列0,1行
df1.append(df2)
#导入数据
df = pd.read_csv('test.csv', header=None) #读取文件 # header没有columns
df.columns =['c1','c2','c3','c4']
df = df.dropna(thresh=4)
df.index = ['nick','jason','tank'] #加列标题
df.to_csv('test1.csv') # 导出csv文件
df.to_excel('')
pandas基础中的基础,一定要学会, <奥卡姆剃刀>
matplotlib
matplotlib模块:画图
#条形图
import matplotlib.pyplot as plt # 默认支持英文,不支持中文
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='D:msyh.ttc')
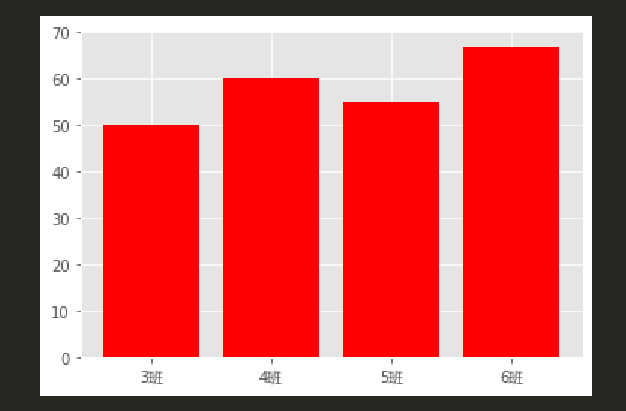
classes = ['3班','4班','5班','6班']
students = [50,60,55,67]
ind = range(len(classes))
plt.bar(ind,students,color='r')
plt.xticks(ind,classes,fontproperties= font)
plt.show()
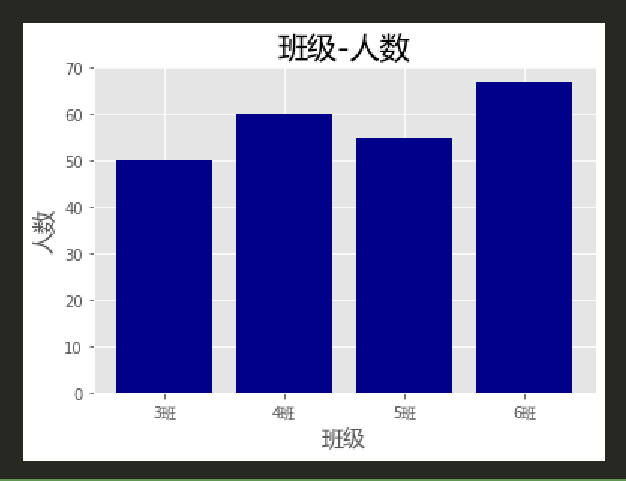
plt.style.use('ggplot')
plt.bar(ind,students,color='darkblue')
plt.xticks(ind,classes,fontproperties= font)
plt.xlabel('班级',fontproperties=font,fontsize=15)
plt.ylabel('人数',fontproperties= font,fontsize=15)
plt.title('班级-人数',fontproperties=font,fontsize=20)
plt.show()
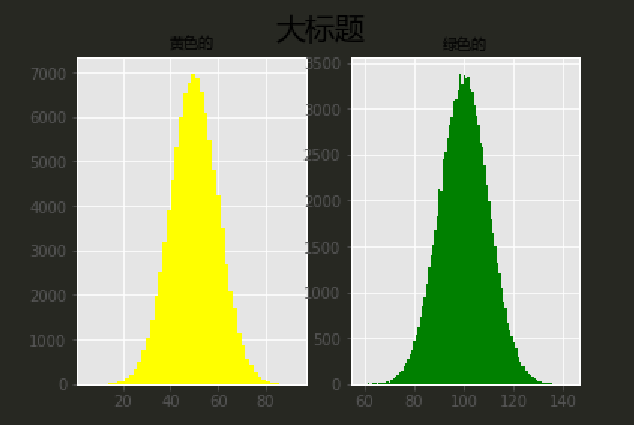
#直方图
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
# %matplotlib inline # 如果没有这个,不会显示图片,有这个会显示图片(只针对jupyter)
font = FontProperties(fname='D:msyh.ttc')
mu1,mu2,sigma = 50,100,10
x1 = mu1+sigma*np.random.randn(100000) # 符合正太分布的随机数据
x2 = mu2+sigma*np.random.randn(100000)
plt.hist(x1,bins=50) # 每50个数据一根柱子
plt.show()
# 对比图
fig = plt.figure()
ax1 = fig.add_subplot(1,2,1) # 一行2列 第一个
ax1.hist(x1,bins=50,color='yellow')
ax1.set_title('黄色的',fontproperties=font)
ax2 = fig.add_subplot(1,2,2) # 一行2列 第二个
ax2.hist(x2,bins=100,color='green')
ax2.set_title('绿色的',fontproperties=font)
fig.suptitle('大标题',fontproperties=font,fontsize=20)
plt.show()
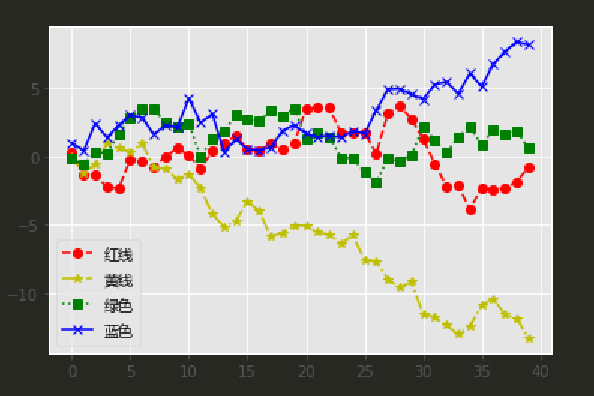
#折线图
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
# %matplotlib inline # 如果没有这个,不会显示图片,有这个会显示图片(只针对jupyter)
font = FontProperties(fname='D:msyh.ttc')
x1 = np.random.randn(1,40).cumsum()
x2 = np.random.randn(1,40).cumsum()
x3 = np.random.randn(1,40).cumsum()
x4 = np.random.randn(1,40).cumsum()
plt.plot(x1,marker='o',color='r',label='红线',linestyle='--')
plt.plot(x2,marker='*',color='y',label='黄线',linestyle='-.')
plt.plot(x3,marker='s',color='green',label='绿色',linestyle=':')
plt.plot(x4,marker='x',color='b',label='蓝色',linestyle='-')
plt.legend(prop=font) # label的字体的需要在这里换
plt.show()
#散点图+直线图
mport matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
# %matplotlib inline # 如果没有这个,不会显示图片,有这个会显示图片(只针对jupyter)
font = FontProperties(fname='D:msyh.ttc')
x1 = np.arange(1,20,2)
y = x1**2
plt.scatter(x1,y,s=100)
plt.show()

python基础-->(函数/面向对象/网络编程(scoket套接字)/并发编程(mutiprocessing))<br>
运维+web开发-->页面展示(django/flask/mysql/postgresql/熟悉redis/熟悉mongodb/了解爬虫)**最保险**<br>
爬虫-->获取数据丢入excel表格;(一天爬一个小网站,经验)(通过爬网站学习知识点-->requests/scrapy/redis数据库/mongodb数据库/scrapy-redis,了解web)<br>
数据分析-->通过对excel表进行数据的展示(画张图);(基础的excel操作/精通numpy/精通pandas/精通matplotlib必会,了解web)<br>
数据挖掘-->通过机器学习算法得到决策函数;(了解numpy/了解pandas/了解maplotlib/sklearn/java(scala)/hadoop/hbase/hive,了解web))<br>
**除了机器学习(人工智能),以上都可以通过努力找到工作,你只能去上网找英文文档(论文/视频)**<br>
机器学习-->构造机器学习算法(了解numpy/了解pandas/了解maplotlib/sklearn/tensorflow(多维张量操作)/pytorch/数学(高数必会,传统机器学习-->概率论;深度学习-->线性代数,强化学习,进阶<博弈论><离散数学><凸优化>))<br>
自动化运维--> 运维经验<br>
自动化测试--> 测试经验<br>
python办公自动化--> 办公经验<br>
少儿编程 --> 女孩子,线上视频<br>