准备入坑下深度学习啦,好好学习,天天向上嘎嘎
整个PPT的思维导图如下,图片来源为深度学习导论 - 读李宏毅《1天搞懂深度学习》
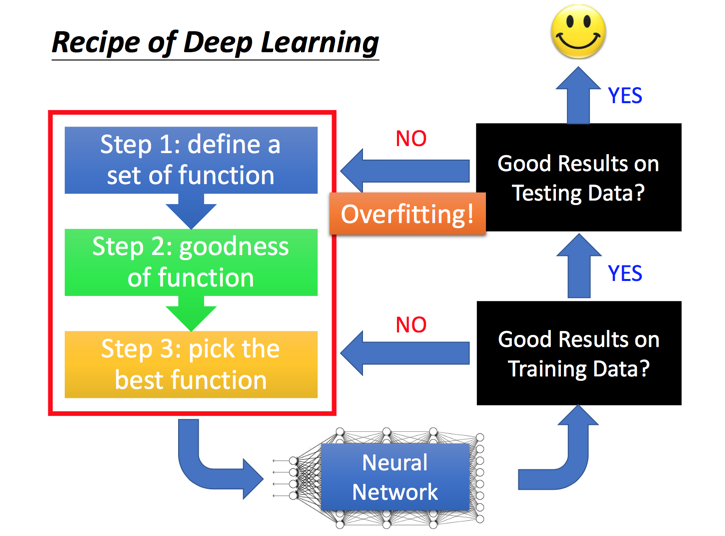
深度学习的三个步骤
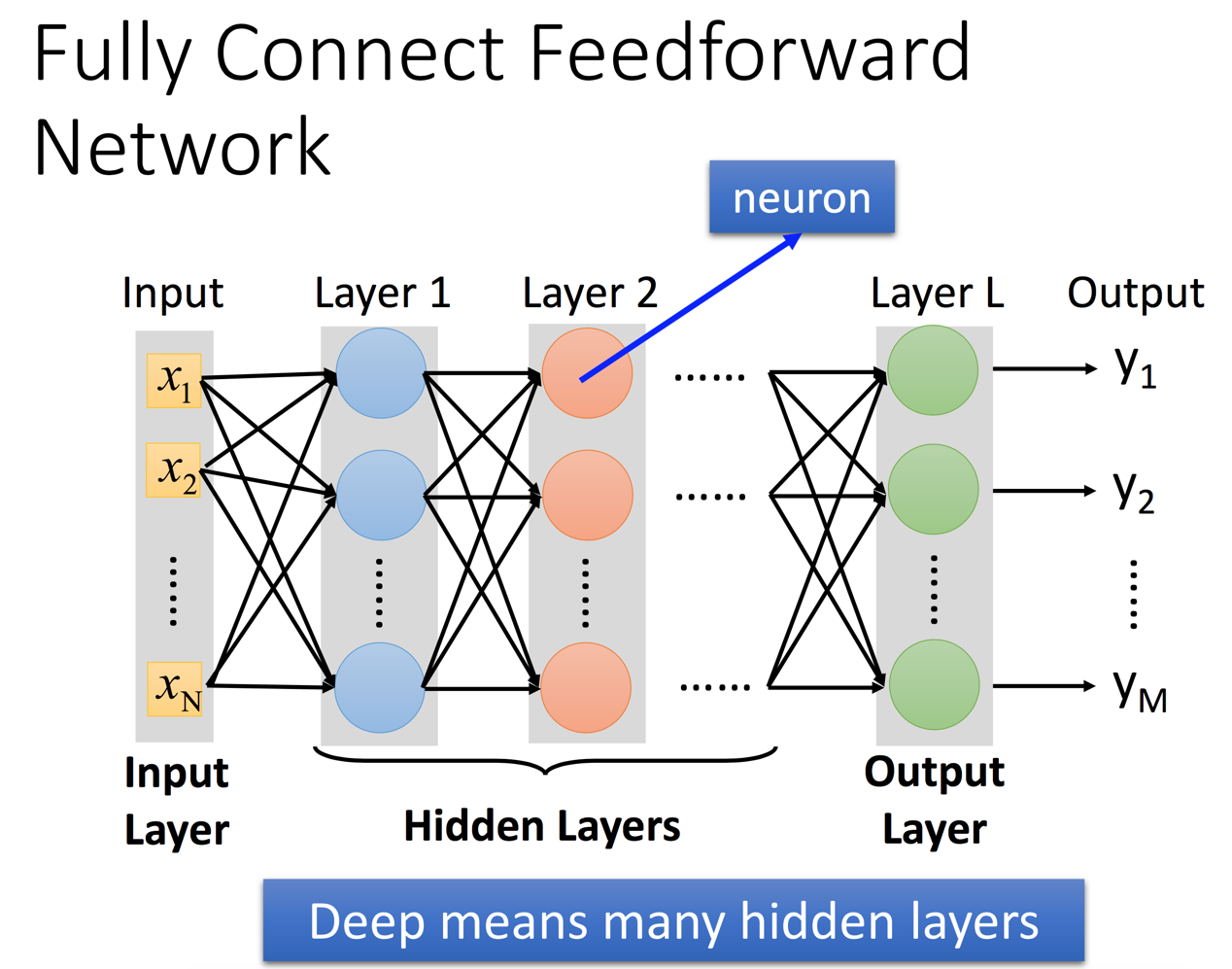
1.定义一组函数→即找到合适的神经网络(网络的参数θ:包括权重和偏移bias)
神经网络的思想来源于对人脑生理上的研究。
人类智能最重要的部分是大脑,大脑虽然复杂,它的组成单元却是相对简单的,大脑皮层以及整个神经系统,是由神经元细胞组成的。而一个神经元细胞,由树突和轴突组成,它们分别代表输入和输出。连在细胞膜上的分叉结构叫树突,是输入,那根长长的“尾巴”叫轴突,是输出。神经元输出的有电信号和化学信号,最主要的是沿着轴突细胞膜表面传播的一个电脉冲。忽略掉各种细节,神经元,就是一个积累了足够的输入,就产生一次输出(兴奋)的相对简单的装置。
树突和轴突都有大量的分支,轴突的末端通常连接到其他细胞的树突上,连接点上是一个叫“突触”的结构。一个神经元的输出通过突触传递给成千上万个下游的神经元,神经元可以调整突触的结合强度,并且,有的突触是促进下游细胞的兴奋,有的是则是抑制。一个神经元有成千上万个上游神经元,积累它们的输入,产生输出。
神经网络和人脑类似,存在多个层级(layer),每个层级都有多个节点(神经元),层级和层级之间相互连接(轴突),最终输出结果。
对于神经网络的计算能力可以理解为通过一层层Layer的计算归纳,逐步的将抽象的原始数据变的具体。以图片识别为例,输入是一个个像素点,经过每层神经网络,逐步变化成为线、面、对象的概念,然后机器有能力能够识别出来。
2.(不断训练)函数达到完善的功能(即使得误差最小。总的损失:对于所有训练的数据,总的损失等于各损失之和。
当一个模型输出结果之后,如果跟预想的结果有偏差(即存在较大的损失)->降低损失->寻找一个可以降低损失的函数->更改参数值(权重,偏差等)
由此可见,对数据的训练是一个逆向的思维,由结果不断地去调整网络,直到结果满意。)
3.选择最佳函数(采用梯度下降法,但是梯度下降法无法保证结果是全局最优的,PPT中有图介绍了该方法,往往用反向传播算法BP来计算梯度)
Softmax的概念
输出层(也可以叫做选择层),将Softmax层作为输出层。
我们知道max,假如说我有两个数,a和b,并且a>b,如果取max,那么就直接取a,没有第二种可能。但有的时候我不想这样,因为这样会造成分值小的那个饥饿(即一直取不到)。所以我希望分值大的那一项经常取到,分值小的那一项也偶尔可以取到,那么我用softmax就可以了。现在还是a和b,a>b,如果我们取按照softmax来计算取a和b的概率,那a的softmax值大于b的,所以a会经常取到,而b也会偶尔取到,概率跟它们本来的大小有关。所以说不是max,而是Softmax
训练方法
训练过程中会发现了两种情况:
1. 没有办法得到很好的训练结果 ---》 重新选择训练方式
2. 没有办法得到很好的测试结果 ---》 往往由于过度拟合导致,需要重新定义方法
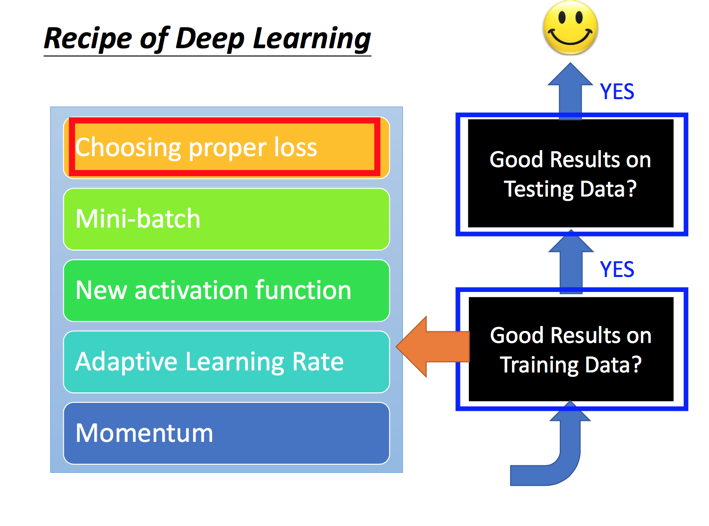
优化训练方法的手段:
1. 选择合适的Loss function:当使用softmax作为输出层的时候,Cross Entropy效果要优于Mean Square Error
2. Mini-batch: 每次训练使用少量数据而不是全量数据效率更高
3. Activation Function:使用ReLU替代Sigmoid可以解决梯度消失的问题,可以训练更深的神经网络
4. Adaptive Learning Rate:可以随着迭代不断自我调整,提高学习效率
5. Momentum: 可以一定程度上避免陷入局部最低点的问题
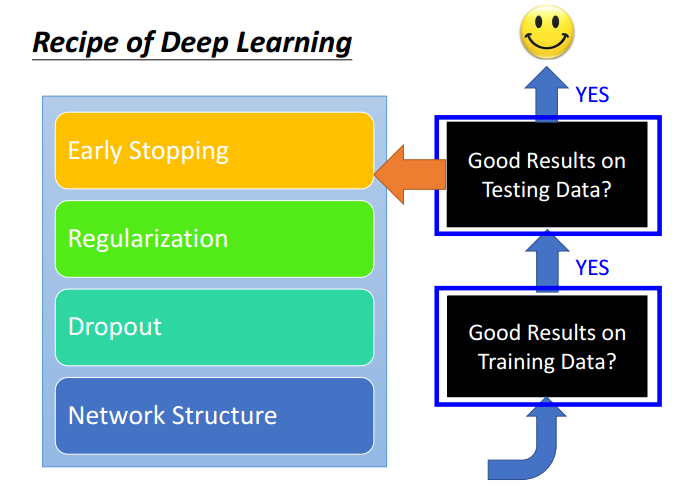
避免过度拟合(overfitting)的方法:
1. Early Stopping:使用cross validation的方式,不断对validation data进行检验,一旦发现预测精度下降则停止。
2. Weight Decay:参数正则化的一种方式?
3. Dropout:通过随机去掉一些节点的连接达到改变网络形式,所以会产生出多种网络形态,然后汇集得到一个最佳结果
4. Network Structure: 例如CNN等其他形态的网络
神经网络变体
Convolutional Neural Network (CNN)
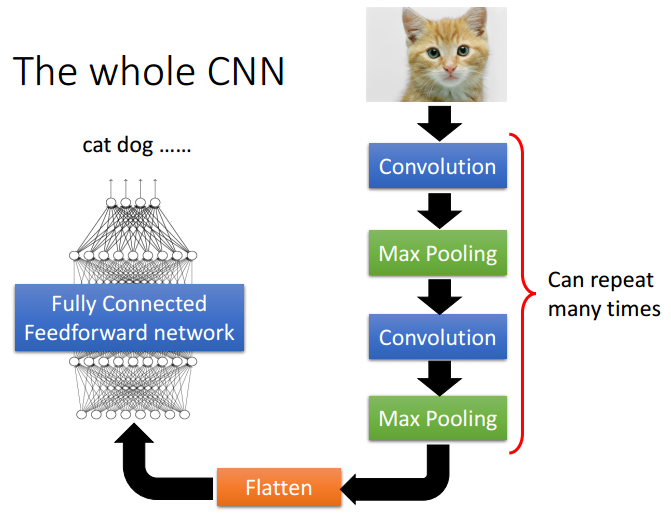
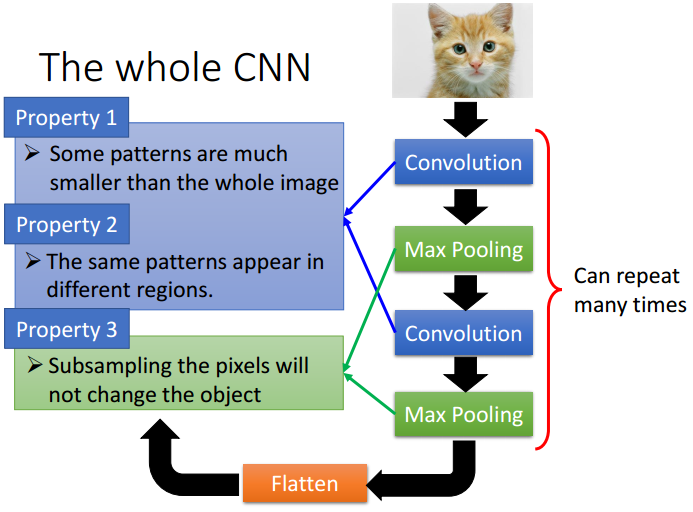
通常情况下,一个CNN包含多次的卷积、池化,然后Flatten,最终再通过一个深度神经网络进行学习预测。CNN在图像、语音识别取得非常好的成绩,核心的想法在于一些物体的特征往往可以提取出来,并且可能出现在图片的任何位置,而且通过卷积、池化可以大大减少输入数据,加快训练效率。
Recurrent Neural Network (RNN)
RNN的想法是可以将hidden layer的数据存储下来,然后作为输入给下一个网络学习。这种网络的想法可以解决自然语言中前后词语是存在关联性的,所以RNN可以把这些关联性放到网络中进行学习。

其他前沿技术
笔记参考来源:
[1] 深度学习导论 - 读李宏毅《1天搞懂深度学习》