使用Py3的HTMLParser解析模块解析HTML的时候,出现:no moudle named 'markupbase' 错误。
用xpath打算分析html里面的新闻。根据运行程序后的报错的信息,知道出问题的地方是 "~/.conda/envs/jjenv/lib/python3.6/site-packages/HTMLParser.py" 在这个文件的 72行出问题了。但是不知道是什么原因,
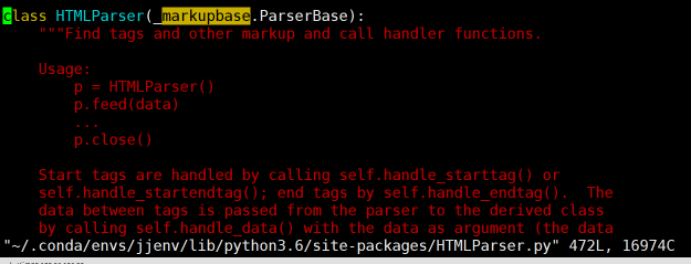
然后我就百度了下,说是:
解决方法:将所有的 markupbase 改为 _markupbase 即可。原因为markupbase是py2库的,_markupbase是py3库的。
于是我进入"~/.conda/envs/jjenv/lib/python3.6/site-packages/HTMLParser.py"这个文件,修改后的结果如上图的第一行。问题得到解决.
反思总结:勇于根据程序报错的信息里面所提示的出错文件位置,定位到相应的文件,然后修改对应的源码代码!
############################## ###################### ##################################
原html文件如下:

content1 = tree.xpath('//text()') print ('content1====',content1)
这个输出结果如下:
<html> <head> <meta charset="utf-8"/> <title> 供给忧虑推升油价破纪录_国际经济_新浪财经_新浪网 </title> </head> <body><div><div id="artibodyTitle"> <h1>供给忧虑推升油价破纪录</h1> <p class="from_info">http://www.sina.com.cn 2008年04月29日 13:14 <span class="linkRed02">南方日报</span></p> </div> <div class="artibody" id="artibody"> <center> <center/></center> <p> <font face="楷体_GB2312">纽约油价盘中达每桶119.93美元</font> </p> <p> 据新华社北京4月28日电由于英国石油公司在北海油田的一条输油管道被关闭等因素引起市场交易者担心石油供给短缺,4月28日纽约油价在电子交易时段创出新高,进一步逼近每桶120美元的高位。</p> <p> 纽约商品交易所6月份交货的轻质原油期货价格在电子交易中一度达到每桶119.93美元,刷新了4月22日创下的每桶119.90美元的最高交易价。</p> <p> 由于英国一家主要炼油厂工人4月27日举行罢工,英国石油公司被迫关闭了在北海油田的一条主输油管道。这条输油管道日输油能力为70万桶,接近英国全国原油日产量的一半。另外,受工人罢工和石油生产设施遭到袭击的影响,非洲产油大国尼日利亚超过一半的石油产能处于关闭状态,进一步加剧了市场对原油供应的担忧。</p> <p> 受美元贬值以及石油输出国组织拒绝增加石油产量等因素影响,国际油价近来一直在高位运行,分析人士认为目前市场交易者因突发事件对石油供给的担忧将对近期油价走势产生较大影响,并可能推升油价进一步走高。</p> <p> 据阿拉伯金融网站报道,沙特阿拉伯最大的国家石油公司———阿美石油公司已作出新的发展计划,将石油钻井数量在目前的基础上再增加三分之一,并将进一步加大对能源项目的投资,使投资额提高40%。</p> <p> 该网站援引英国《中东经济文摘》周刊的一篇报道说,这项将于2009至2013年实施的计划草案将被提交到今年5月中旬的公司董事会上讨论通过。 </p> <a href="target=_blank"/> </div> </div></body></html>
是根据这个输出结果写的如下代码,
接下来说说如何用xpath 去抽取html中我想要的正文部分
#coding=utf-8 from lxml import etree from HTMLParser import HTMLParser from lxml import html filepath = '/data0/news_cleaned/sina/finance/2008-04-29/finance.sina.com.cn_+world_+gjjj_+20080429_+13144815898.html' with open(filepath) as f: s=f.read() #print(s) #print(html) tree = html.fromstring(s) ################################## ### 输出整个html的东西 #### content1 = tree.xpath('//text()') print ('content1====',content1) ### 输出 h1标签的内容 ############## title = tree.xpath("//h1/text()")[0] print('title===',title) ######################################################## filepath = '/data0/news_cleaned/sina/finance/2008-04-29/finance.sina.com.cn_+world_+gjjj_+20080429_+13144815898.html' each_paper='' with open(filepath) as f: s=f.read() tree = html.fromstring(s) div_list = tree.xpath("//div[@class='artibody']/p") for div_i in div_list: each_paper = each_paper + div_i.xpath('.//text()')[0] print('each_paper===',each_paper) #结果是正确的,但是未保留html正文文本的中的换行之类的。 #########################################################3 ################################# div_list = tree.xpath("//div[@class='artibody']") print('shishi===',(div_list[0].text_content())) # 成功的,保留了原html正文的格式,如换行 #print('shishi===',html.tostring(div_list[0])) #不成功的尝试 #for div_i in div_list: #print('shishi===',str(html.tostring(div_i))) #不成功的尝试 #print('shishi===',(div_i.text_content())) #不成功的尝试
############################# #################### ##########################
张miao同事也给了我一个不错的版本
from bs4 import BeautifulSoup import re html='xxxxxxx' soup=BeautifulSoup(html) div=soup.find('div') content=re.findall('<font.*/font>(.*)a href',str(div))
 我: 这个还得继续进行re吧 :
我: 这个还得继续进行re吧 :
张 :replace 无用符号就行了 :或者sub一下
我: :我看看是不是能解决所有html文本。
: