一、topic(主题) partition(分区) offset(位移)

创建toipc bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test-topic --partitions 3 --replication-factor 1 test-topic // topic名字 --partitions 3 // 分区数为3 --replication-factor 1 // 副本数为1(不得超过broker数量) 列出topic bin/kafka-topics.sh --zookeeper localhost:2181 --list 查看指定topic详情 bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test-topic
1、创建topic时会指定partitions的数量,也就是说一个topic下面可以创建多个分区。
2、producer向topic发消息时,会把消息均摊到这些partition上面,每向一个partition上写一个消息,partition上面写入offset会向后移一位。
3、consumer消费topic时,是按partition读取的,partition上每消费一条消息,该消费者读取的offset会向后移一位。注意producer写入的offset与consumer读取的offset不是同一个。
二、producer发送的消息会均摊到每个partitions上
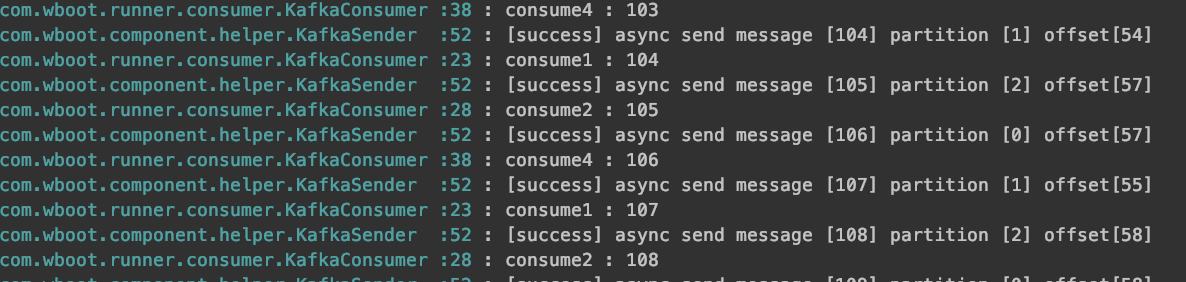
创建了一个topic,里面有3个partition。当发送消息时,会负载均衡的把消息均摊到每个partition上,并且每个partition的offset是累加的。如下图所示,我从100开始累加逐条发送到topic上面,可以看到消息确实是均摊到每个partition上面的。

三、consumer是按partition消费的
1、topic有三个partition,消费者组有一个消费者实例时。可以看到消费者会先消费一个partition,消费完这个partition后再消费下一个partition。之后生产者轮询向partition发消息,消费者依次消费。

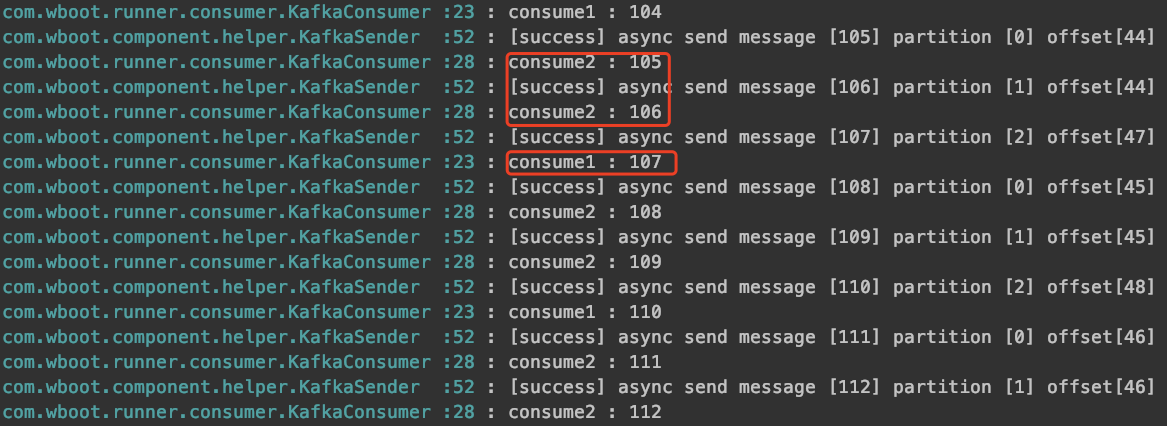
2、topic有三个partition,消费者组有两个消费者实例时。可以看到consume1消费一个partition,consumer2消费两个partition。
3、topic有三个partition,消费者组有三个消费者实例时。可以看到三个实例各自消费一个partition。

4、 topic有三个partition,消费者组有四个消费者实例时。可以看到是有一个实例是消费不到partition的,所以消费者实例并不是越多吞吐量越大,等于partition数就可达到最大吞吐量。