前言:
卷积神经网络(CNN)在计算机视觉领域取得了显著的成功,几乎成为所有计算机视觉任务中的一种通用和主导方法。
受transformer在自然语言处理(NLP)的成功,许多研究人员正试图探索transformer的应用,一些工作模型视觉任务作为字典查找问题可学习查询,并使用transformer decoder作为一个特定任务的头的CNN主干,如VGG和ResNet。而一些现有技术已经将注意力模块纳入到CNNs中。
论文:https://arxiv.org/pdf/2102.12122.pdf
代码:https://github.com/whai362/PVT
关注公众号CV技术指南,及时获取更多计算机视觉技术总结文章。
Introduction
论文提出了一种使用transformer模型的无卷积主干网络,称为金字塔视觉transformer (Pyramid Vision Transformer--PVT),它可以在许多下游任务中作为一个通用的backbone,包括图像级预测和像素级密集预测。
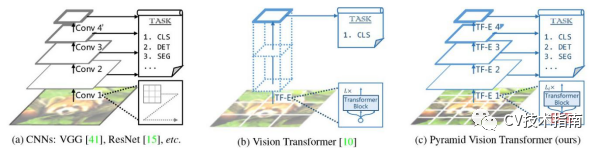
不同架构的比较,其中“Conv”和“TF-E”分别表示卷积和transformer编码器。
(a) 表明,许多CNN backbones都使用金字塔结构进行密集的预测任务,如目标检测(DET)、语义和实例分割(SEG)。
(b) 表明,最近提出的视觉transformer(ViT)是一种专门为图像分类(CLS)设计的“柱状”结构。
(c) 说明,通过结合CNNs的金字塔结构,我们提出了金字塔视觉transformer (PVT),它可以用作许多计算机视觉任务的通用backbone,扩大了ViT的范围和影响。此外,我们的实验还表明,PVT可以很容易地与DETR结合,建立一个端到端目标检测系统,没有卷积和人工设计的组件,如密集anchor和非极大值抑制(NMS)。
具体而言,如上图所示,与ViT不同,PVT通过以下方式克服了传统transformer的困难:
(1)以细粒度的图像补丁(即每个补丁4×4)作为输入来学习高分辨率表示,这对密集的预测任务至关重要。
(2)在网络深度增加时减少transformer的序列长度,显著降低计算消耗。
(3)采用空间减少注意(SRA)层来进一步降低学习高分辨率特征图的资源成本。
Method
与CNN骨干网络类似,所提出的方法有四个阶段来生成不同尺度的特征图。所有的阶段都共享一个类似的架构,它由一个补丁嵌入层和Li transformer编码器层组成。
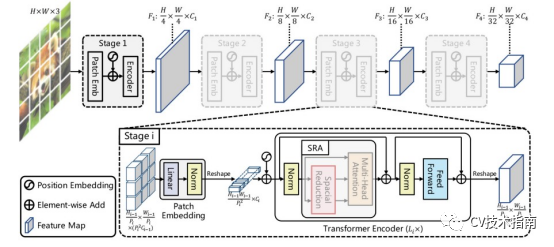
拟建金字塔视觉transformer (PVT)的整体结构。
整个模型分为四个阶段,每个阶段由一个补丁嵌入层和一个Li-layer transformer encoder组成。遵循金字塔结构,四个阶段的输出分辨率逐渐从步长4缩小到步长32。
在第一阶段,给定大小为H×W×3的输入图像,他们首先将其分为(HW)/4²补丁,每个补丁的大小为4×4×3。
然后,他们将扁平的补丁输入到一个线性投影中,并得到大小为(HW)/4²×C1的嵌入补丁(embedded patches)。之后,嵌入块和位置嵌入通过L1层transformer encoder,输出reshape为特征图F1,尺寸为H/4×W/4×C1。同样,使用来自前一阶段的特征图作为输入,它们获得以下特征图F2、F3和F4,其相对于输入图像的步进为8、16和32像素。
所提出的方法需要处理高分辨率特征图,论文提出了一个空间减少注意力(SRA)层来取代编码器中传统的多头注意(MHA)层。
与MHA类似,SRA还接收一个查询Q、一个关键K和一个值V作为输入,并输出一个改进的特性。不同的是,我们的SRA将在注意力操作之前减少K和V的空间尺度,这在很大程度上降低了计算/内存开销。
第一阶段SRA详情如下:

![]()
这些是线性投影的参数。N_i是第一阶段transformer encoder的编号。因此,每个头的尺寸等于Ci/Ni。SR(·)是空间缩减操作,其定义为:
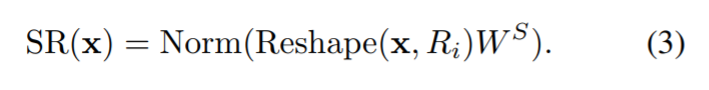
![]()

![]()
利用特征金字塔{F1、F2、F3、F4},该方法可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
结论
总的来说,所提出的PVT具有以下优点。首先,与传统的CNN backbones相比,感受野在深度增加时会增加,PVT总是产生一个全局感受野,比CNNs的局部感受野更适合于检测和分割。其次,与ViT相比,由于金字塔结构的进步,所提出的方法更容易插入到许多具有代表性的密集预测pipeline中。第三,利用PVT,我们可以结合PVT与其他为不同任务设计的transformer decoder,构建一个无卷积管道。
实验提出了第一个端到端目标检测检测pipeline,PVT+DETR,它是完全无卷积的。它在2017年COCO上达到34.7,优于基于ResNet50的原始DETR。
原文链接:
https://medium.com/mlearning-ai/pyramid-vision-transformer-a-versatile-backbone-for-dense-prediction-without-convolutions-fe58842d2609
本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。


其它文章