前言
本文介绍了一个端到端的用于视觉跟踪的transformer模型,它能够捕获视频序列中空间和时间信息的全局特征依赖关系。在五个具有挑战性的短期和长期基准上实现了SOTA性能,具有实时性,比Siam R-CNN快6倍。
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

论文:Learning Spatio-Temporal Transformer for Visual Tracking
代码:https://github.com/researchmm/Stark
Backgound
卷积核不擅长对图像内容和特征的长期相关性进行建模,因为它们只处理局部邻域,无论是在空间上还是在时间上。目前流行的追踪器,包括离线siamese追踪器和在线学习模型,几乎都是建立在卷积运算的基础上。因此,这些方法只能很好地对图像内容的局部关系进行建模,但仅限于捕获远程的全局交互。这样的缺陷可能会降低模型处理全局上下文信息对于定位目标对象很重要的场景的能力,例如经历大规模变化或频繁进出视图的对象。
空间信息和时间信息对于目标跟踪都是重要的。前者包含用于目标定位的对象外观信息,而后者包含对象跨帧的状态变化。以前的siamese跟踪器只利用空间信息进行跟踪,而在线方法使用历史预测进行模型更新。虽然这些方法很成功,但它们并没有明确地对空间和时间之间的关系进行建模。
Contribution
受最近的检测transformer(DETR)的启发,论文提出了一种新的端到端跟踪结构,采用编码器-解码器transformer来提高传统卷积模型的性能。
新架构包含三个关键组件:编码器、解码器和预测头。
1. 编码器接受初始目标对象、当前图像和动态更新模板的输入。编码器中的self-attention模块通过输入的特征依赖关系来学习输入之间的关系。由于模板图像在整个视频序列中被更新,因此编码器可以捕获目标的空间和时间信息。
2. 解码器学习嵌入的查询以预测目标对象的空间位置。
3. 使用基于角点的预测头来估计当前帧中目标对象的边界框。同时,学习记分头来控制动态模板图像的更新。
总而言之,这项工作有三个贡献。
1. 提出了一种新的致力于视觉跟踪的transformer架构。它能够捕获视频序列中空间和时间信息的全局特征依赖关系。提出使用动态更新模板。
2. 整个方法是端到端的,不需要余弦窗口、bounding box平滑等后处理步骤,大大简化了现有的跟踪流水线。
3. 提出的跟踪器在五个具有挑战性的短期和长期基准上实现SOTA性能,同时以实时速度运行。
Methods
论文提出了一种用于视觉跟踪的时空transformer网络,称为STARK。论文基于一种简单的基线方法,该方法直接应用原始编解码器变压器进行跟踪,且只考虑了空间信息。论文扩展基线以学习用于目标定位的空间和时间表示,引入了一个动态模板和一个更新控制器来捕捉目标对象的外观变化。
Baseline方法
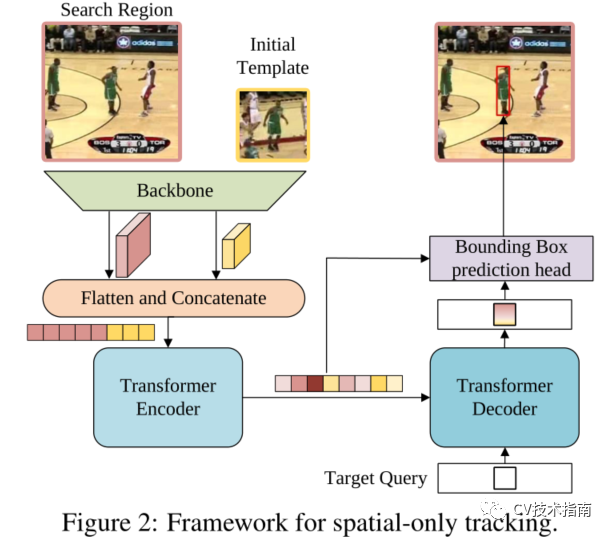
图2为baseline方法
baseline主要由三个部分组成:卷积主干、编解码器转换器和bounding box预测头。
原图像先通过CNN backbone进行降维和降采样,完了再进行Flatten 和Concatenate得到向量,向量再加入正弦位置嵌入,作为transformer的Encoder输入。随机初始化一个查询向量,Decoder将目标查询和来自编码器的增强特征序列作为输入。与DETR采用100个对象查询不同,论文只向解码器输入一个查询来预测目标对象的一个bounding。此外,由于只有一个预测,论文去掉了DETR中用于预测关联的匈牙利算法。目标查询可以关注模板上的所有位置和搜索区域特征,从而学习最终边界框预测的鲁棒表示。

![]()
DETR采用三层感知器预测目标坐标。然而,正如GFLoss所指出的那样,直接回归坐标等同于拟合狄拉克增量分布,它没有考虑数据集中的模糊性和不确定性。这种表示方式不灵活,对目标跟踪中的遮挡和杂乱背景等挑战也不够稳健。
为了提高box估计的质量,通过估计box角点的概率分布,设计了一种新的预测头。如图3所示,首先从编码器的输出序列中提取搜索区域特征,然后计算搜索区域特征与解码器输出嵌入的相似度。最后特征序列会reshape成3维,通过L层Conv-BN-ReLU的全卷积网络输出两个概率图,一个概率图为bounding box左上角的坐标,一个概率图为bounding box右下角的坐标,跟DETR一样,这里不多细讲。
本文方法
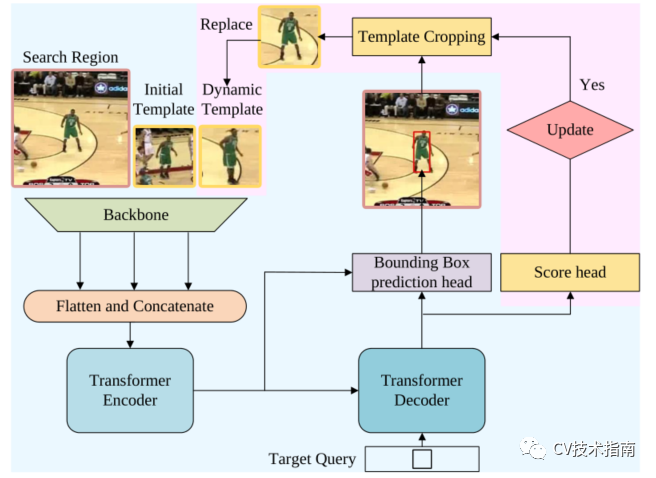
论文提出的时空跟踪框架。粉色突出显示了与纯空间架构的区别。
与仅使用第一帧和当前帧的基线方法不同,时空方法引入了从中间帧采样的动态更新模板作为附加输入(论文的唯一贡献),如图所示。除了初始模板的空间信息外,动态模板还可以捕捉目标外观随时间的变化,提供额外的时间信息。三元组的特征图被扁平化和拼接,然后发送到编码器。该编码器通过在空间和时间维度上对所有元素之间的全局关系建模来提取可区分的时空特征。
在跟踪过程中,有些情况下不应更新动态模板。例如,当目标被完全遮挡或移出视线时,或者当跟踪器漂移时,裁剪的模板是不可靠的。为简单起见,论文认为只要搜索区域包含目标,就可以更新动态模板。为了自动确定当前状态是否可靠,论文添加了一个简单的分数预测头,它是一个三层感知器,然后是Sigmoid激活。如果得分高于阈值τ,则认为当前状态可靠。
训练和推理
正如最近的工作所指出的那样,定位和分类的联合学习可能会导致这两个任务的次优解,这有助于将定位和分类解耦。因此,论文将训练过程分为两个阶段,将定位作为首要任务,将分类作为次要任务。
具体地说,在第一阶段,除了分数头外,整个网络都进行了端到端的训练,只使用与定位相关的损失。在这个阶段,确保所有的搜索图像都包含目标对象,并让模型学习定位能力。在第二阶段,仅利用定义为如下的二进制交叉熵损失来优化分数头

![]()
并且冻结所有其他参数以避免影响定位能力。这样,最终的模型在经过两个阶段的训练后,既学习了定位能力,又学习了分类能力。
在推理过程中,在第一帧中初始化两个模板和对应的特征。然后,裁剪搜索区域并将其送入网络,生成一个边界框和置信度分数。仅当达到更新间隔并且置信度分数高于阈值τ时,才更新动态模板。为了提高效率,论文将更新间隔设置为Tu 帧。新的模板被从原始图像中裁剪出来,然后馈送到主干中进行特征提取。
Conclusion
与以前的长期跟踪器相比,提出的方法的框架要简单得多。具体地说,以前的方法通常由多个组件组成,例如基本跟踪器、目标验证模块和全局检测器。相比之下,提出的方法只有一个以端到端方式学习的网络。大量的实验表明,提出的方法在短期和长期跟踪基准上都建立了新的SOTA性能。
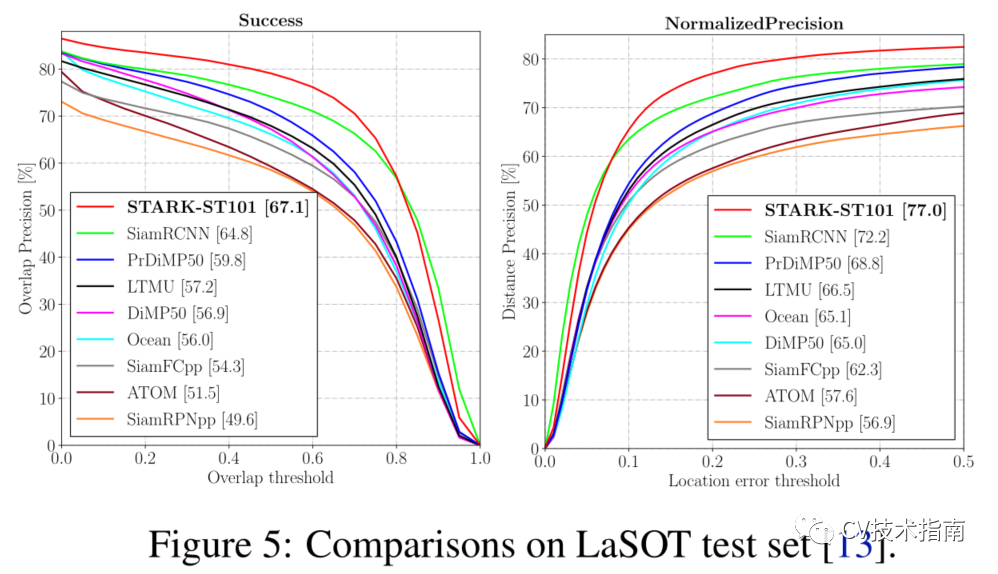
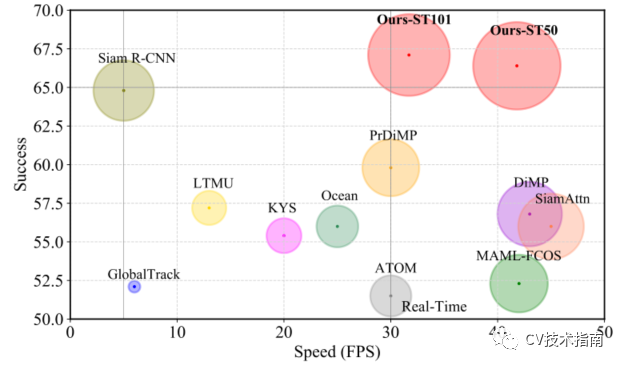
例如,论文的时空transformer跟踪器在GOT-10K和LaSOT上分别比Siam R-CNN高3.9%(AO score)和2.3%(Success)。此外,论文的跟踪器可以实时运行,在Tesla V100图形处理器上比Siam R-CNN(30V.S.5fps)快6倍,如图所示
![]()
与LaSOT上SOTA的比较。将Success性能与Frame-PerSecond(Fps)跟踪速度进行了可视化比较。
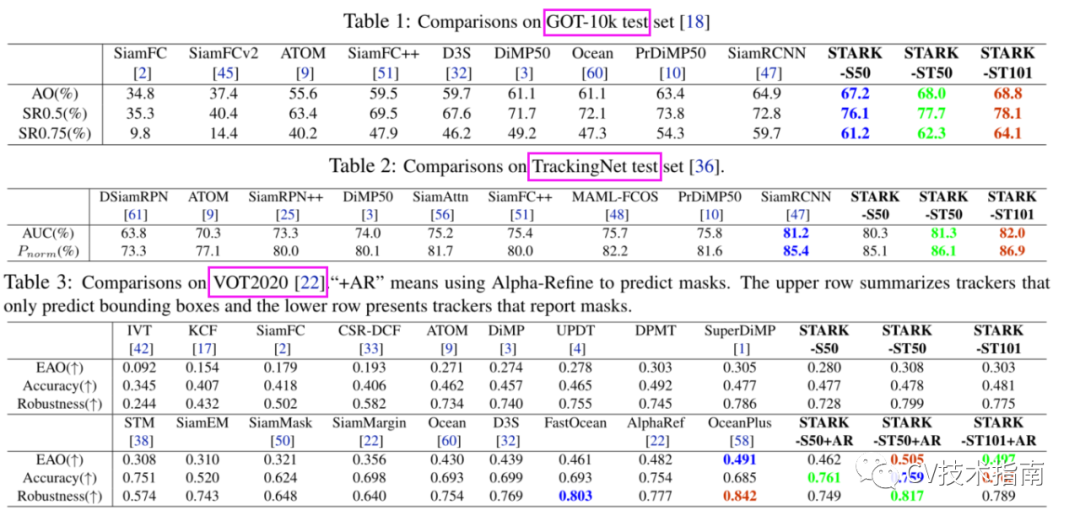
在多个数据集上与其它SOTA方法的比较
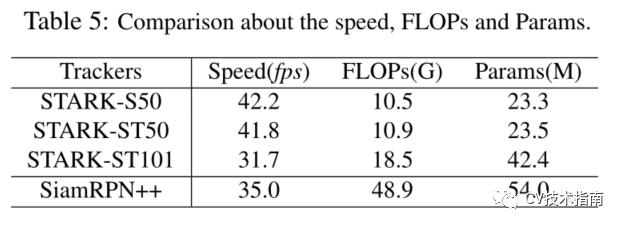
速度、计算量和参数
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章