代码是作者页面上下载的matlab版。香港中文大学汤晓鸥教授。Learning a Deep Convolutional Network for Image Super-Resolution。
http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
- demo_SR.m为运行主文件。
up_scale = 3; model = 'model9-5-5(ImageNet)x3.mat';
- .mat文件存储数据。三个卷积层的权重和偏置。y=wx+b中的w和b。

%% work on illuminance only if size(im,3)>1 im = rgb2ycbcr(im); im = im(:, :, 1); end im_gnd = modcrop(im, up_scale); im_gnd = single(im_gnd)/255;
彩色图像的话,RGB转为YCbCr。并只对Y通道处理。
若为灰度图像,直接处理。
其中,modcrop函数:将图片裁剪为能够调整的大小(与放大率匹配)。裁剪舍掉余数行和列。
function imgs = modcrop(imgs, modulo) if size(imgs,3)==1 sz = size(imgs); sz = sz - mod(sz, modulo); imgs = imgs(1:sz(1), 1:sz(2)); else tmpsz = size(imgs); sz = tmpsz(1:2); sz = sz - mod(sz, modulo); imgs = imgs(1:sz(1), 1:sz(2),:); end
mod取余,crop修剪的意思。
double数据类型占8个字节,single类型占4个字节。Single(单精度浮点型)对图像归一化处理。得到im_gnd。
%% bicubic interpolation im_l = imresize(im_gnd, 1/up_scale, 'bicubic'); im_b = imresize(im_l, up_scale, 'bicubic');
im_l :将im_gnd 双三次插值缩小后的图像。
im_b : 将im_gnd 双三次插值缩小后再进行同比例放大的图像。
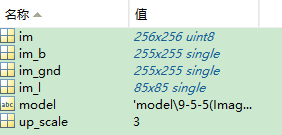
现在,LR是85*85的,放大三倍后是Bicubic,大小为255*255。
经过边界修剪,shave.m。四周各去边框-3。大小变为249*249。
function I = shave(I, border) I = I(1+border(1):end-border(1), ... 1+border(2):end-border(2), :, :);
或
function I = shave(I, border) I = I(1+border(1):end-border(1),1+border(2):end-border(2));
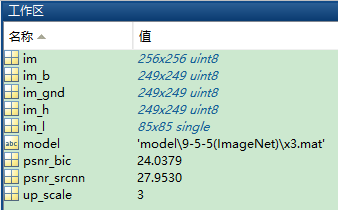
结果是灰度图像:

想要生成彩色图像:可以见别人改过的代码。
【转载自】
SRCNN(一) - 刘一好 - 博客园 https://www.cnblogs.com/howtoloveyou/p/9691233.html
超分辨率重建SRCNN--Matlab 7.0中运行 - juebai123的博客 - CSDN博客 https://blog.csdn.net/juebai123/article/details/80532577
SRCNN.m
function im_h = SRCNN(model, im_b) %% load CNN model parameters load(model); [conv1_patchsize2,conv1_filters] = size(weights_conv1); conv1_patchsize = sqrt(conv1_patchsize2); [conv2_channels,conv2_patchsize2,conv2_filters] = size(weights_conv2); conv2_patchsize = sqrt(conv2_patchsize2); [conv3_channels,conv3_patchsize2] = size(weights_conv3); conv3_patchsize = sqrt(conv3_patchsize2); [hei, wid] = size(im_b); %% conv1 weights_conv1 = reshape(weights_conv1, conv1_patchsize, conv1_patchsize, conv1_filters); conv1_data = zeros(hei, wid, conv1_filters); for i = 1 : conv1_filters conv1_data(:,:,i) = imfilter(im_b, weights_conv1(:,:,i), 'same', 'replicate'); conv1_data(:,:,i) = max(conv1_data(:,:,i) + biases_conv1(i), 0); end %% conv2 conv2_data = zeros(hei, wid, conv2_filters); for i = 1 : conv2_filters for j = 1 : conv2_channels conv2_subfilter = reshape(weights_conv2(j,:,i), conv2_patchsize, conv2_patchsize); conv2_data(:,:,i) = conv2_data(:,:,i) + imfilter(conv1_data(:,:,j), conv2_subfilter, 'same', 'replicate'); end conv2_data(:,:,i) = max(conv2_data(:,:,i) + biases_conv2(i), 0); end %% conv3 conv3_data = zeros(hei, wid); for i = 1 : conv3_channels conv3_subfilter = reshape(weights_conv3(i,:), conv3_patchsize, conv3_patchsize); conv3_data(:,:) = conv3_data(:,:) + imfilter(conv2_data(:,:,i), conv3_subfilter, 'same', 'replicate'); end %% SRCNN reconstruction im_h = conv3_data(:,:) + biases_conv3;
- l Conv1: f1 = 9 *9 activation = ‘relu’
- l Conv2: f2 = 1 *1 activation = ‘relu’ #为了非线性映射 增强非线性
- l Conv3: f3 = 5 * 5 activation = ‘lienar’
【转载自】
SRCNN流程细节 - Python少年 - 博客园 https://www.cnblogs.com/echoboy/p/10289741.html