计算成像
定义:凡是在成像过程中参与了计算过程的成像方式都可以认为是计算成像。
计算成像能够实现传统成像无法完成的任务,例如:去除运动模糊、超分辨率重建等。
在实际应用中,计算成像主要在以下三个方面对成像改进:
扩大视场、超分辨率、增大景深。
增大景深与全景深成像 - ostartech - 博客园 http://www.cnblogs.com/wxl845235800/p/9408684.html
计算成像的英文是Computational Imaging,在国外与之相近的叫计算摄像学(Computational Photography)。这门学科是一门将计算机视觉、数字信号处理、图形学等深度交叉的新兴学科,旨在结合计算、数字传感器、光学系统和智能光照等技术,从成像机理上来改进传统相机,并将硬件设计与软件计算能力有机结合,突破经典成像模型和数字相机的局限性,增强或者扩展传统数字相机的数据采集能力,全方位地捕捉真实世界的场景信息。
针对于实际应用中的问题,计算成像主要可以在大视场、高分辨率、全景深等方便进行提高。
在扩大视场方面,典型的做法是微相机阵列拼接与复眼仿生;
在提高成像分辨率方面,典型的做法是采用各种超分辨率算法;
在增大景深方面,典型的做法是利用波前编码技术。
扩大视场:
(1)微相机阵列拼接
结合微相机阵列的大视场成像系统主要利用球透镜成像的轴向对称性,结合微相机阵列与后期的计算成像技术,实现宽视场和高分辨率效果的成像结果。结合微相机阵列的大视场成像系统包括一个共心光学主透镜组和一系列小的光学元件组成的微相机阵列,共心光学主透镜组将观测视场成像于球面一次像面,微相机阵列在距一次像面一定位置处成球面分布,一次成像面经过微相机阵列折转后被分割成一系列子图像,相邻微相机阵列之间存在视场重叠,利用图像处理算法,将每一个微相机拍摄的小视场图像拼接为一幅宽视场图像,最终实现宽视场成像。
(2)复眼仿生
节肢动物的复眼一直是科学家感兴趣的研究对象。复眼有非常大的视角和景深,对运动物体的感应也十分灵敏。模拟复眼特性的仿生复眼照相机可实现视角和景深极大化,且不会产生轴外像差。人造同位复眼照相机由一组弹性微型透镜阵列和一组可变形的硅基光电感 应阵列组成,分别布置在弹性薄膜基底的两侧,其中每个微型透镜和光感元件构成一个“小眼”。这两个阵列都在平面上制造并组装起来,然后经由弹性变形转换成近乎完整的半球形状(160度),上面集成了180个小眼,与火蚁和树皮甲虫复眼中的小眼数相近。这一特性使新相机实现了视角和景深的极大化。可拉伸电子器件对于仿生复眼照相机的研制起到了关键作用。因为传统的脆性电子器件不能承受变形,无法像昆虫的复眼那样把光电感应阵列分布在一个半球形的表面上。仿生复眼照相机具有的所谓“同位”功能,是指弹性薄膜基底在液压调控下变形成任意曲率的球面时,微型透镜和光感元件都能保持高度对应性,从而确保复眼照相机不会发生轴外像差,即由于折射球面存在球面像差和像面弯曲,衍生出实际像与理想像的偏差。
(3)球面探测器
完全对称的共心光学系统各球面共心,没有与视场相关的像差,容易实现大视场,其像面为球面,如果采用曲面探测器则可以较好地匹配光学系统,但是基于目前曲面探测器的发展状况,实现球形像面的困难较多。谷歌公司2016年01月27日申请公布的发明专利《曲面基板上的光电探测器阵列》提出将多个光电探测器定位在由光学系统限定的弯曲的焦曲面上的精确位置。为了实现该定位,光电探测器可以被安装在平坦配置的柔性基板上的期望位置处。安装有光电探测器的柔性基板可以被成形为与弯曲的焦曲面的形状基本上一致。该成形可以通过将柔性基板夹在至少两个夹紧件之间而实现。夹在所述至少两个夹紧件之间的弯曲的柔性基板可以被相对于光学系统定位,使得光电探测器位于弯曲的焦曲面上的期望三维位置处。
增加分辨率:
增加空间分辨率最直接的解决方法就是通过传感器制造技术减少像素尺寸(例如增加每单元面积的像素数量)。然而,随着像素尺寸的减少,光通量也随之减少,它所产生的散粒噪声使得图像质量严重恶化。不受散粒噪声的影响而减少像素的尺寸有一个极限,对于0.35微米的CMOS处理器,像素的理想极限尺寸大约是40平方微米。当前的图像传感器技术大多能达到这个水平。
另外一个增加空间分辨率的方法是增加芯片的尺寸,从而增加图像的容量。因为很难提高大容量的耦合转换率,因此这种方法一般不认为是有效的。在许多高分辨率图像的商业应用领域,高精度光学和图像传感器的高价格也是一个必须考虑的重要因素。因此,有必要采用一种新的方法来增加空间分辨率,从而克服传感器和光学制造技术的限制。
(1)超分辨率重建
图像超分辨率是指由一幅低分辨率图像或图像序列恢复出高分辨率图像,高分辨率图像意味着图像具有高像素密度,可以提供更多的细节,这些细节往往在应用中起到关键作用。图像超分辨率技术分为超分辨率复原和超分辨率重建。超分辨率重构的基本过程为:先进行图像退化分析,然后进行图像的配准,最后根据配准的信息对图像进行重构。目前,图像超分辨率研究可分为3个主要范畴:基于插值、基于重建和基于学习的方法。具体方法有:规整化重建方法,均匀空间样本内插方法,迭代反投影方法(IBP),集合理论重建方法(凸集投影POCS),统计重建方法(最大后验概率MAP和最大似然估计ML),混合ML/MAP/POCS方法,自适应滤波/维纳滤波/卡尔曼滤波方法,确定性重建方法基于学习和模式识别的方法。
超分辨率重建,即通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像。超分辨率重建的核心思想就是用时间带宽(获取同一场景的多帧图像序列)换取空间分辨率,实现时间分辨率向空间分辨率的转换。在基于超分辨率重建的空间分辨率增强技术中,其基本前提是通过同一场景可以获取多幅低分辨率细节图像。在超分辨率重建中,典型地认为低分辨率图像代表了同一场景的不同侧面,也就是说低分辨率图像是基于亚像素精度的平移亚采样。如果仅仅是整数单位的像素平移,那么每幅图像中都包含了相同的信息,这样就不能为高分辨率图像的复原提供新的信息。如果每幅低分辨率图像彼此之间都是不同的亚像素平移,那么它们彼此之间就不会相互包含,在这种情况下,每一幅低分辨率图像都会为高分辨率图像的复原提供一些不同的信息。为了得到同一场景的不同侧面,必须通过一帧接一帧的多场景或者视频序列的相关的场景运动。我们可以通过一台照相机的多次拍摄或者在不同地点的多台照相机获取多个场景,例如在轨道卫星一类可控制的图像应用中,这种场景运动是能够实现的;对于局部对象移动或者震荡一类的不可控制的图像应用也是同样能实现的。如果这些场景运动是已知的或者是在亚像素精度范围了可估计的,同时如果我们能够合成这些高分辨率图像,那么超分辨率重建图像复原是可以实现的。
通过对获得的低分辨率图像进行处理以后,一方面能够对成像光学系统的点扩展函数进行反卷积,去除光学系统的影响;另一方面能够获得显示图像的像元总数增加,同时也希望在处理过程中去除相应的成像系统的噪声等。通过这些处理以后,图像的分辨率得到了改善,但获得的并不一定是真实的高分辨率图像,而是对真实高分辨率图像的某种估计,因而通常称所获得的图像为超分辨率图像,相应处理过程为超分辨率图像重建。超分辨率涉及的两个问题:a)图像修复:改良光照不均匀、噪声较多的图像,但是不改变图像大小;b)图像插值改变图像大小,对单张图像进行插值并不属于超分辨率重建技术。图像插值,即增加单幅图像的尺寸。插值也分线性插值与非线性插值,其中线性插值最简单,容易实现。尽管这个领域已经被广泛地研究,即使一些基本的功能已经建立,从一幅近似的低分辨率图像放大图像的质量仍然是有限的,这是因为对单幅图像插值不能恢复在低分辨率采样过程中损失的高频部分,因此图像插值方法不能被认作是超分辨率重建技术。为了在这方面有更大的改进,下一步就需要应用基于同一场景的相关的额外数据,基于同一场景的不同的观察信息的融合就构成了基于场景的超分辨率重建复原。
基于学习的概念首次由Freeman提出,基本思想是先学习低分辨率图像与高分辨率图像之间的关系,利用这种关系来指导对图像进行超分辨率。马尔可夫网络建模低分辨率和高分辨率图像块间的关系,学习因降质丢失的高频分量,然后与插值得到的初始估计相加恢复出高分辨率图像。主要方法有:有效组织图像块数据库提高匹配效率,通过主要轮廓先验增强图像质量,基于流形学习的方法,利用多尺度张量投票理论来估计位置的高分辨率图像,融合不同尺寸的图像进行分辨率增强。
(2)双目视觉
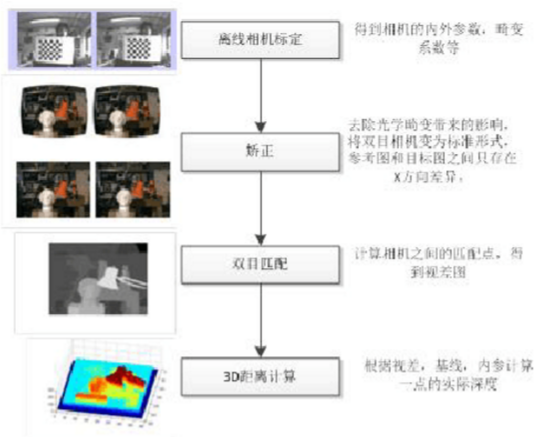
双目视觉是模拟人类视觉原理,使用计算机被动感知距离的方法,它是基于视差原理并由多幅图像获取物体三维几何信息的方法。双目立体视觉系统一般由双摄像机从不同角度同时获得被测物的两幅数字图像,或由单摄像机在不同时刻从不同角度获得被测物的两幅数字图像,并基于视差原理恢复出物体的三维几何信息,重建物体三维轮廓及位置。双目立体视觉系统在机器视觉领域有着广泛的应用前景。从两个或者多个点观察一个物体,获取在不同视角下的图像,根据图像之间像素的匹配关系,通过三角测量原理计算出像素之间的偏移来获取物体的三维信息。得到了物体的景深信息,就可以计算出物体与相机之间的实际距离,物体3维大小,两点之间实际距离。目前也有很多研究机构进行3维物体识别,来解决2D算法无法处理遮挡,姿态变化的问题,提高物体的识别率。双目视觉算法流程如下:
(3)双摄像头
华为 P9 采用双摄像头设计,两个摄像头做不同的事情。两个摄像头中的一颗采用了索尼 IMX 286 传感器,这个用于捕捉物体的 RGB 颜色;而另外一颗采用了 monochrome 黑白摄像头用于捕捉物体的黑白影像。通过黑白摄像头的大进光量捕捉到更清晰的物体细节;而通过 IMX 286 的 RGB 颜色摄像头去考虑颜色,就是配备一颗摄像头负责记录色彩,一颗黑白负责记录细节轮廓。当 P9 拿到 RGB 摄像头捕捉到的彩色信息的图片和黑白大进光量的 monochrome 摄像头捕捉到的细节图片时,通过软件算法将两张图片合成。这样理论上我们会获得一张拍摄质量更好的照片,特别是在高亮以及暗处的细节表现上。
【参考资料】
计算成像_百度文库 https://wenku.baidu.com/view/b4c07736aef8941ea66e0590.html?from=search